CSV
Allows you to read or write delimited files such as CSV (Comma-separated Values) or TSV (Tab-separated Values)
Source
Source Parameters
CSV Source supports all the available Spark read options for CSV.
The below list contains the additional parameters to read a CSV file:
| Parameter | Description | Required | |
|---|---|---|---|
| Dataset Name | Name of the Dataset | True | |
| Location | Location of the file(s) to be loaded Eg: dbfs:/data/test.csv | True | |
| Schema | Schema to applied on the loaded data. Can be defined/edited as JSON or inferred using Infer Schema button | True |
Example
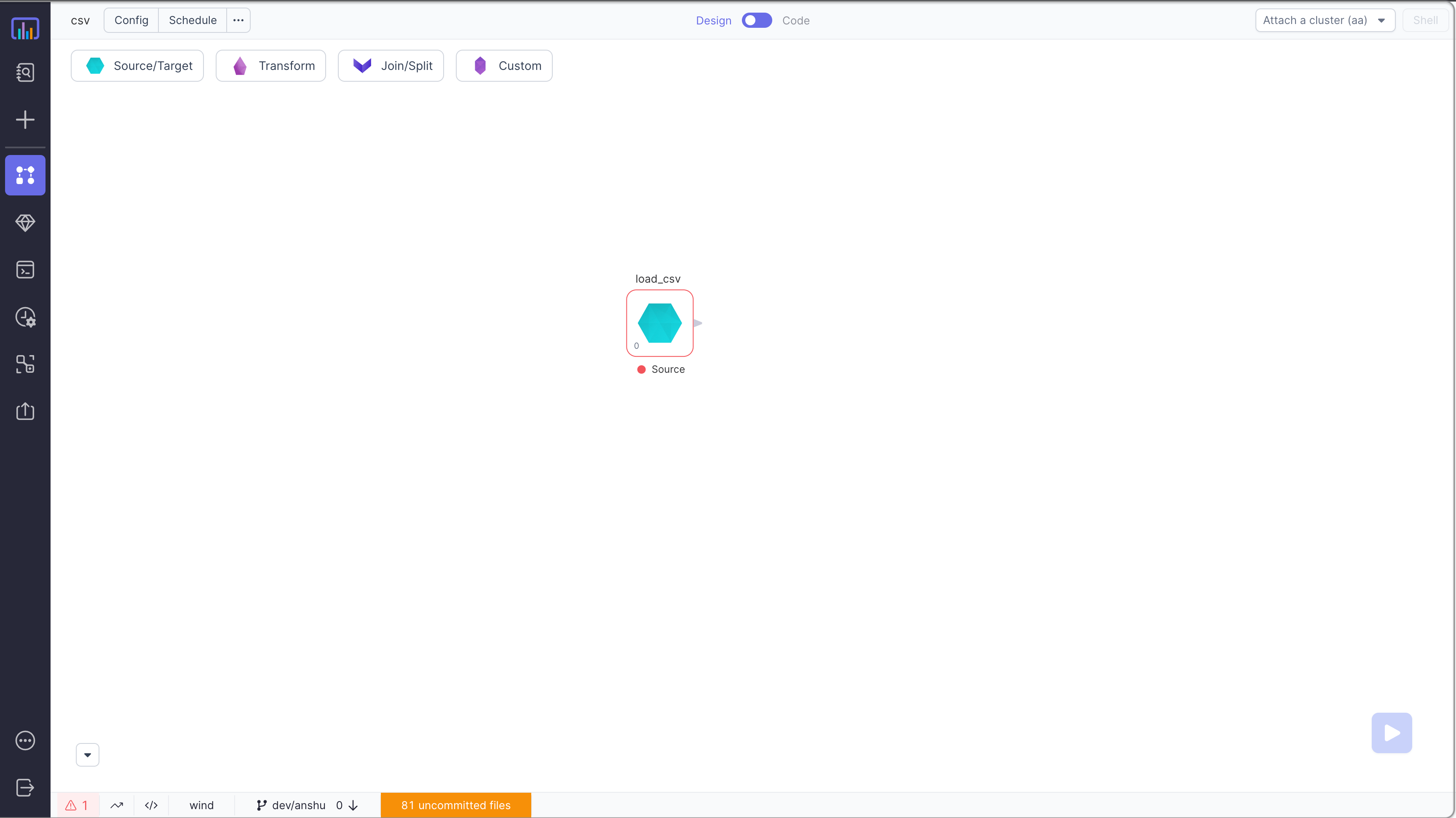
Step 1 - Create Source Component
Generated Code
- Python
- Scala
def load_csv(spark: SparkSession) -> DataFrame:
return spark.read\
.schema(
StructType([
StructField("order_id", IntegerType(), True),
StructField("customer_id", IntegerType(), True),
StructField("order_status", StringType(), True),
StructField("order_category", StringType(), True),
StructField("order_date", DateType(), True),
StructField("amount", DoubleType(), True)
])
)\
.option("header", True)\
.option("quote", "\"")\
.option("sep", ",")\
.csv("dbfs:/Prophecy/anshuman@simpledatalabs.com/OrdersDatasetInput.csv")
object load_csv {
def apply(spark: SparkSession): DataFrame =
spark.read
.format("csv")
.option("header", true)
.option("quote", "\"")
.option("sep", ",")
.schema(
StructType(
Array(
StructField("order_id", IntegerType, true),
StructField("customer_id", IntegerType, true),
StructField("order_status", StringType, true),
StructField("order_category", StringType, true),
StructField("order_date", DateType, true),
StructField("amount", DoubleType, true)
)
)
)
.load("dbfs:/Prophecy/anshuman@simpledatalabs.com/OrdersDatasetInput.csv")
}
Target
Target Parameters
CSV Target supports all the available Spark write options for CSV.
The below list contains the additional parameters to write a CSV file:
| Parameter | Description | Required |
|---|---|---|
| Dataset Name | Name of the Dataset | True |
| Location | Location of the file(s) to be loaded Eg: dbfs:/data/output.csv | True |
| Write Mode | How to handle existing data. See this table for a list of available options. | False |
Supported Write Modes
| Write Mode | Description |
|---|---|
| overwrite | If data already exists, overwrite with the contents of the DataFrame |
| append | If data already exists, append the contents of the DataFrame |
| ignore | If data already exists, do nothing with the contents of the DataFrame. This is similar to a CREATE TABLE IF NOT EXISTS in SQL. |
| error | If data already exists, throw an exception. |
Example
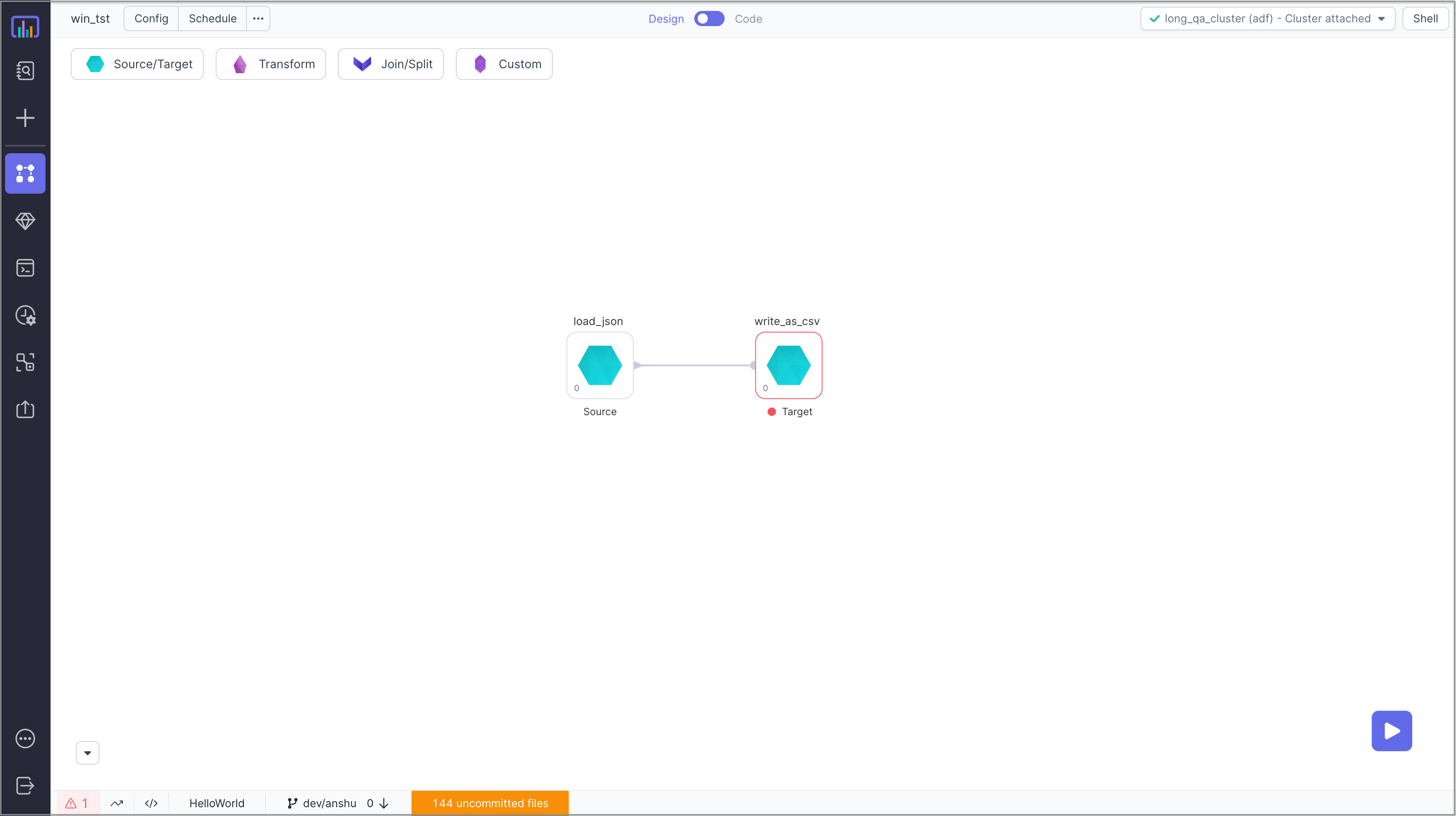
Step 1 - Create Target Component
Generated Code
- Python
- Scala
def write_as_csv(spark: SparkSession, in0: DataFrame):
in0.write\
.option("header", True)\
.option("sep", ",")\
.mode("error")\
.option("separator", ",")\
.option("header", True)\
.csv("dbfs:/Prophecy/anshuman@simpledatalabs.com/output.csv")
object write_as_csv {
def apply(spark: SparkSession, in: DataFrame): Unit =
in.write
.format("csv")
.option("header", true)
.option("sep", ",")
.mode("error")
.save("dbfs:/Prophecy/anshuman@simpledatalabs.com/output.csv")
}
Producing a single output file
Because of Spark's distributed nature, output files are written as multiple separate partition files. If you need a single output file for some reason (such as reporting or exporting to an external system), use a Repartition Gem in Coalesce mode with 1 output partition:
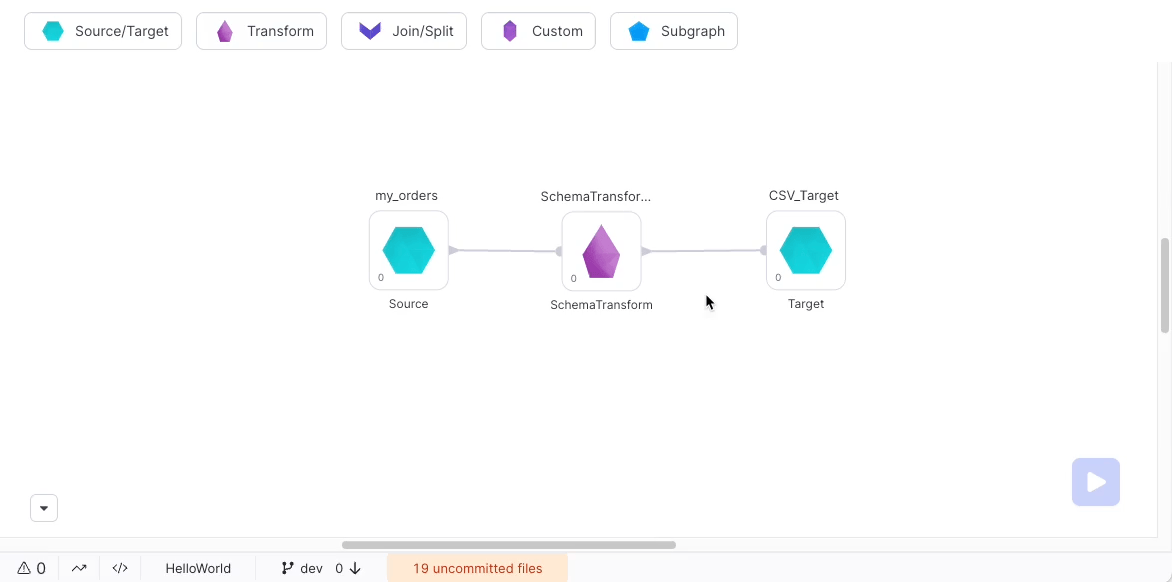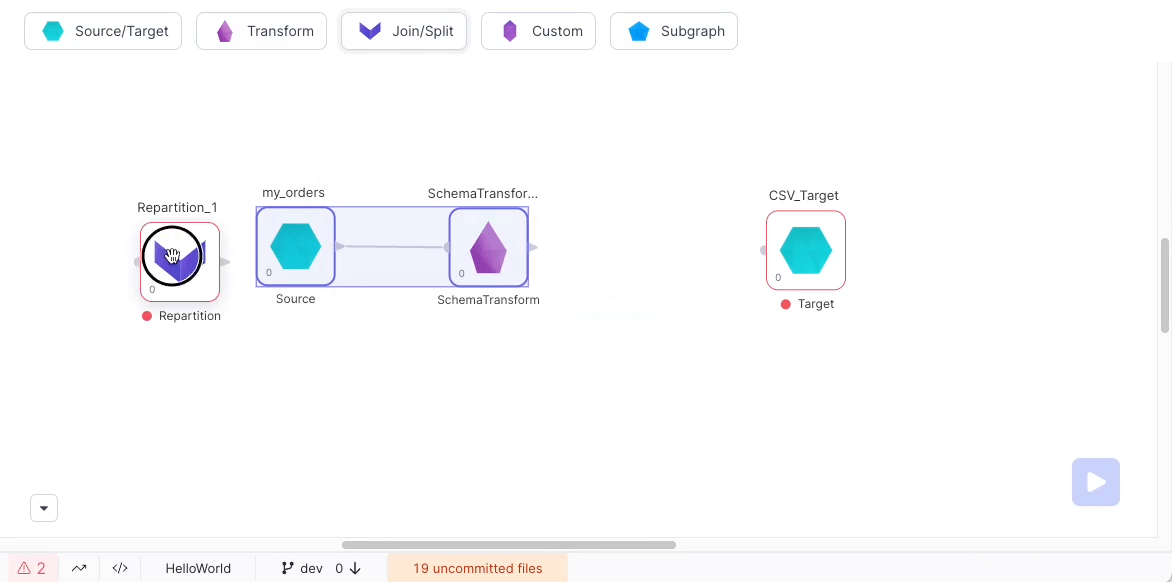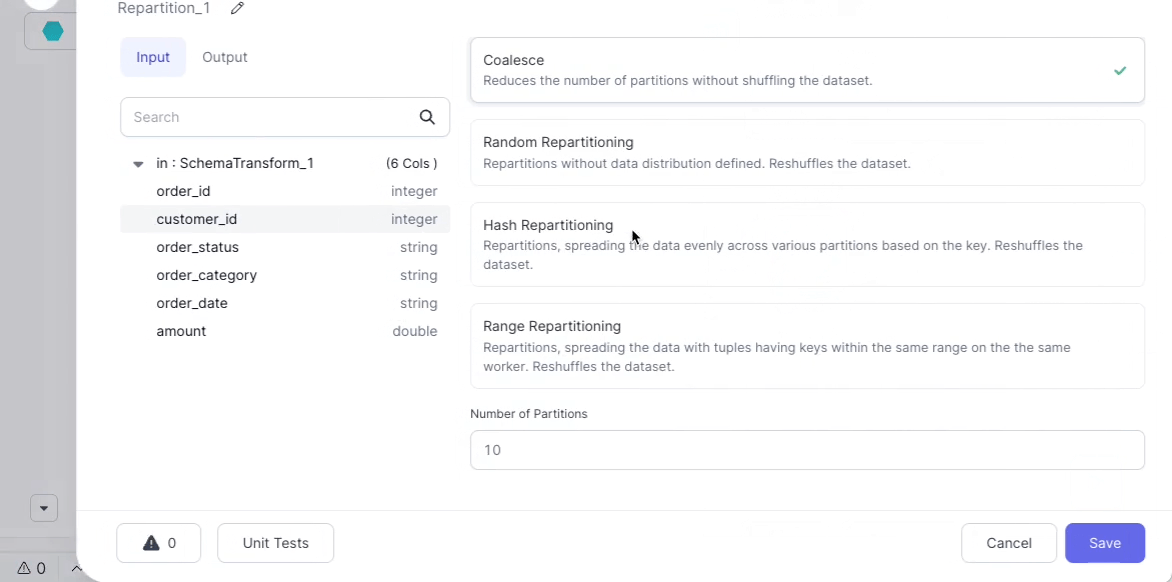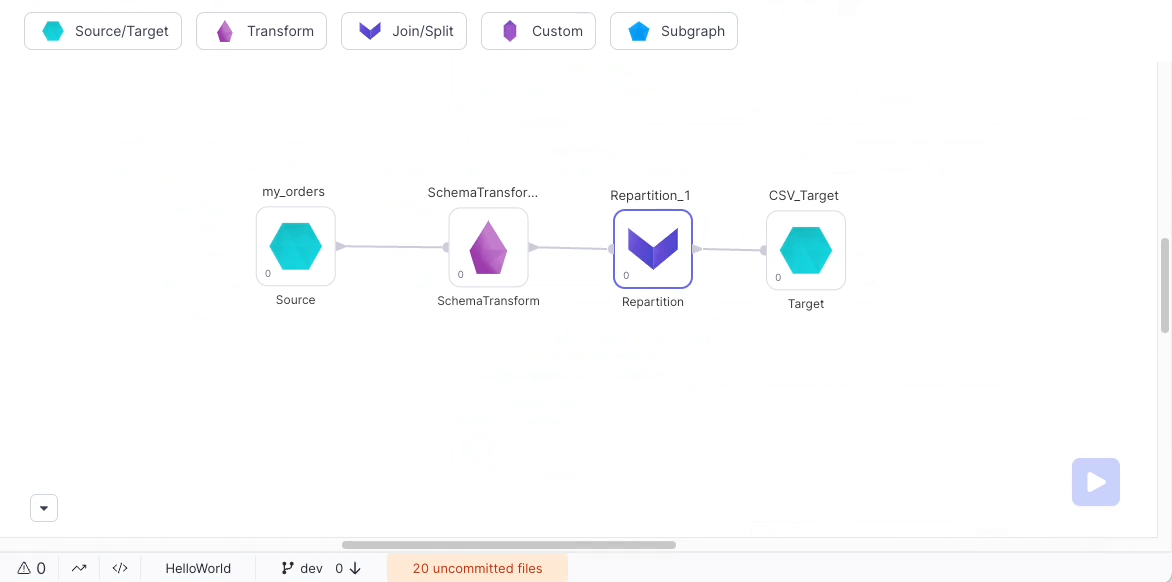
Note: This is not recommended for extremely large data sets as it may overwhelm the worker node writing the file.