Delta
Reads and writes Delta tables, including Delta Merge operations and Time travel.
Source
Source Parameters
| Parameter | Description | Required |
|---|---|---|
| Location | File path for the Delta table | True |
| Read Timestamp | Time travel to a specific timestamp | False |
| Read Version | Time travel to a specific version of table | False |
For time travel on Delta tables:
- Only
Read TimestampORRead Versioncan be selected, not both. - Timestamp should be between the first commit timestamp and the latest commit timestamp in the table.
- Version needs to be an integer. Its value has to be between min and max version of table.
By default most recent version of each row is fetched if no time travel option is used.
To read more about Delta time travel and its use cases click here.
Example
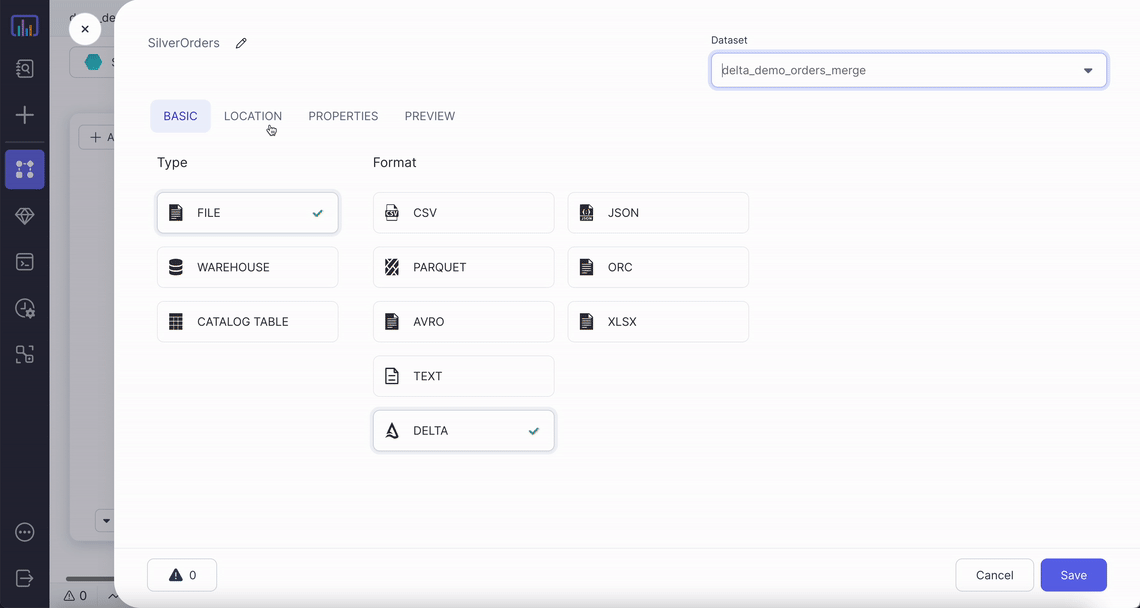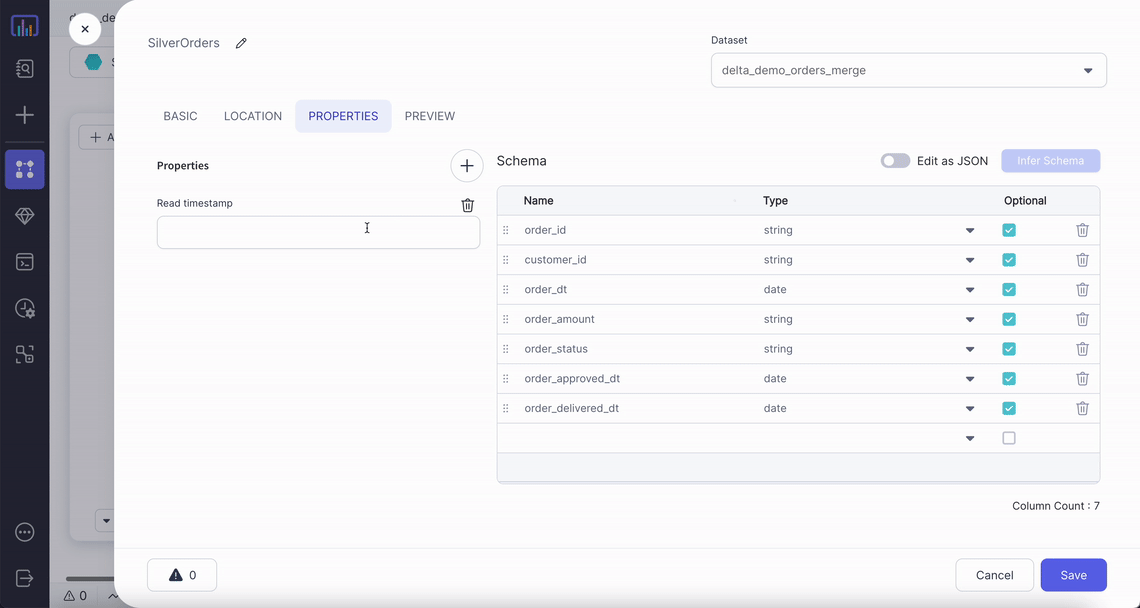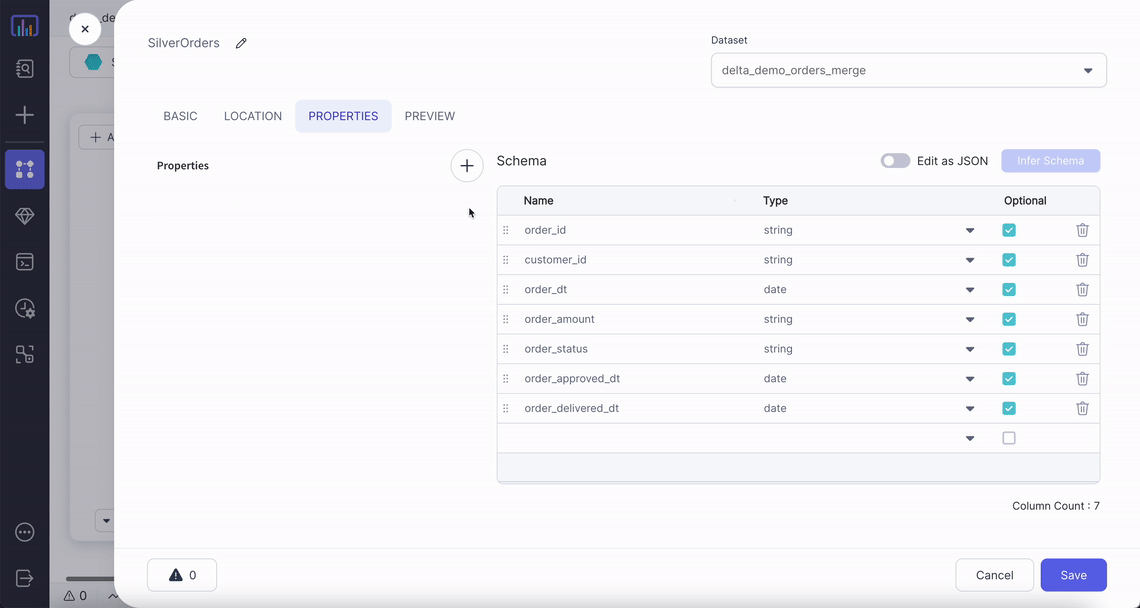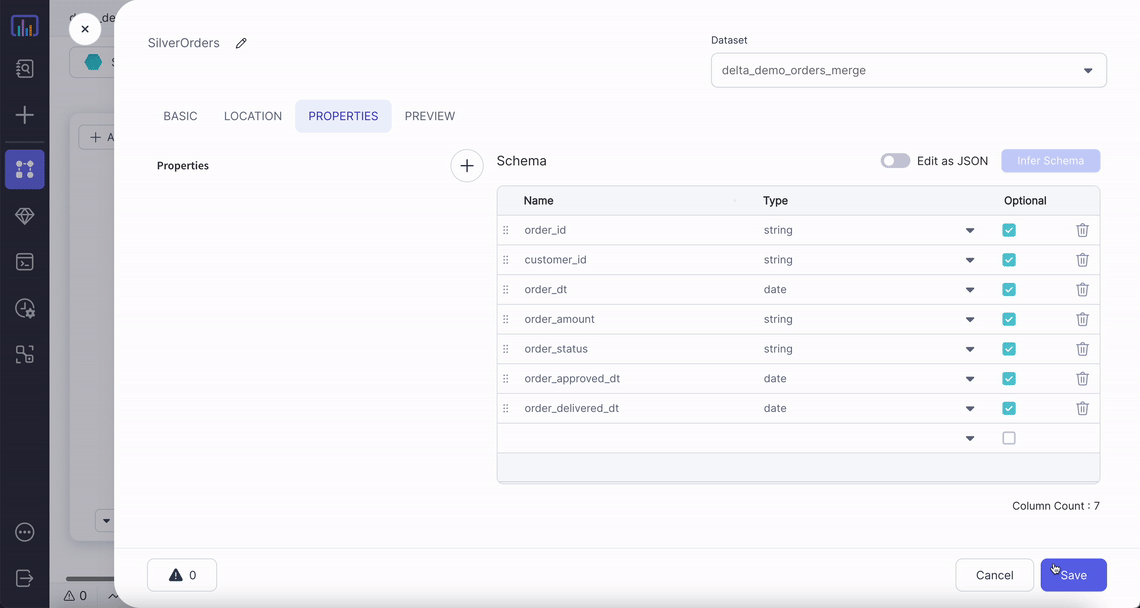
Generated Code
Without time travel
- Python
- Scala
def ReadDelta(spark: SparkSession) -> DataFrame:
return spark.read.format("delta").load("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
object ReadDelta {
def apply(spark: SparkSession): DataFrame = {
spark.read.format("delta").load("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
}
}
Timestamp-based time travel
- Python
- Scala
def ReadDelta(spark: SparkSession) -> DataFrame:
return spark.read.format("delta").option("timestampAsOf", "2022-05-05")\
.load("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
object ReadDelta {
def apply(spark: SparkSession): DataFrame = {
spark.read.format("delta").option("timestampAsOf", "2022-05-05")
.load("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
}
}
Version-based time travel
- Python
- Scala
def readDelta(spark: SparkSession) -> DataFrame:
return spark.read.format("delta").option("versionAsOf", "0")\
.load("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
object readDelta {
def apply(spark: SparkSession): DataFrame = {
spark.read.format("delta").option("versionAsOf", "0")
.load("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
}
}
Target
Target Parameters
| Parameter | Description | Required |
|---|---|---|
| Location | File path to write the Delta table to | True |
| Write mode | Write mode for DataFrame | True |
| Optimise write | If true, it optimizes Spark partition sizes based on the actual data | False |
| Overwrite table schema | If true, overwrites the schema of the Delta table with the schema of the incoming DataFrame | False |
| Merge schema | If true, then any columns that are present in the DataFrame but not in the target table are automatically added on to the end of the schema as part of a write transaction | False |
| Partition Columns | List of columns to partition the Delta table by | False |
| Overwrite partition predicate | If specified, then it selectively overwrites only the data that satisfies the given where clause expression. | False |
Supported Write Modes
| Write Mode | Description |
|---|---|
| overwrite | If data already exists, overwrite with the contents of the DataFrame |
| append | If data already exists, append the contents of the DataFrame |
| ignore | If data already exists, do nothing with the contents of the DataFrame. This is similar to a CREATE TABLE IF NOT EXISTS in SQL. |
| error | If data already exists, throw an exception. |
| merge | Insert, delete and update data using the Delta merge command. |
| SCD2 merge | It is a Delta merge operation that stores and manages both current and historical data over time. |
Among these write modes overwrite, append, ignore and error works the same way as in case of parquet file writes. Merge will be explained with several examples in the following sections.
Target Example
Generated Code
- Python
- Scala
def writeDelta(spark: SparkSession, in0: DataFrame):
return in0.write\
.format("delta")\
.option("optimizeWrite", True)\
.option("mergeSchema", True)\
.option("replaceWhere", "order_dt > '2022-01-01'")\
.option("overwriteSchema", True)\
.mode("overwrite")\
.partitionBy("order_dt")\
.save("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
object writeDelta {
def apply(spark: SparkSession, in: DataFrame): Unit = {
in0.write
.format("delta")
.option("optimizeWrite", True)
.option("mergeSchema", True)
.option("replaceWhere", "order_dt > '2022-01-01'")
.option("overwriteSchema", True)
.mode("overwrite")
.partitionBy("order_dt")
.save("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
}
}
Delta MERGE
You can upsert data from a source DataFrame into a target Delta table by using the MERGE operation. Delta MERGE supports Inserts, Updates, and Deletes in a variety of use cases, and Delta is particularly suited to examine data with individual records that slowly change over time. Here we consider the most common types of slowly changing dimension (SCD) cases: SCD1, SCD2, and SCD3. Records are modified in one of the following ways: history is not retained (SCD1), history is retained at the row level (SCD2), or history is retained at the column level (SCD3).
SCD1
Let's take the simplest case to illustrate a MERGE condition.
Parameters
| Parameter | Description | Required |
|---|---|---|
| Source alias | Alias to use for the source DataFrame | True |
| Target alias | Alias to use for existing target Delta table | True |
| Merge Condition | Condition to merge data from source DataFrame to target table, which would be used to perform update, delete, or insert actions as specified. | True |
| When Matched Update Action | Update the row from Source that already exists in Target (based on Merge Condition) | False |
| When Matched Update Condition | Optional additional condition for updating row. If specified then it must evaluate to true for the row to be updated. | False |
| When Matched Update Expressions | Optional expressions for setting the values of columns that need to be updated. | False |
| When Matched Delete Action | Delete rows if Merge Condition (and the optional additional condition) evaluates to true | False |
| When Matched Delete Condition | Optional additional condition for deleting row. If a condition is specified then it must evaluate to true for the row to be deleted. | False |
| When Not Matched Action | The action to perform if the row from Source is not present in Target (based on Merge Condition) | False |
| When Not Matched Condition | Optional condition for inserting row. If a condition is specified then it must evaluate to true for the row to be updated. | False |
| When Not Matched Expressions | Optional expressions for setting the values of columns that need to be updated. | False |
- At least one action out of update, delete or insert needs to be set.
- Delete removes the data from the latest version of the Delta table but does not remove it from the physical storage until the old versions are explicitly vacuumed. See vacuum for details.
- A merge operation can fail if multiple rows of the source DataFrame match and the merge attempts to update the same rows of the target Delta table. Deduplicate gem can be placed before target if duplicate rows at source are expected.
When possible, provide predicates on the partition columns for a partitioned Delta table as such predicates can significantly speed up the operations.
Example
Let's assume our initial customers table is as below:
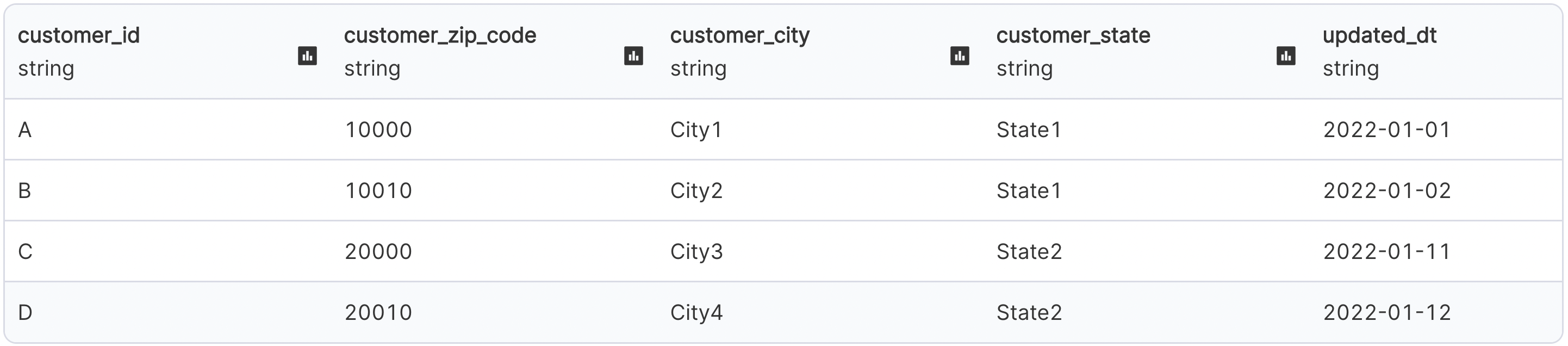
And we have the below updates coming into customers table

Our output and configurations for SCD1 merge will look like below:
Generated Code
- Python
- Scala
def writeDeltaMerge(spark: SparkSession, in0: DataFrame):
from delta.tables import DeltaTable, DeltaMergeBuilder
if DeltaTable.isDeltaTable(spark, "dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd1"):
DeltaTable\
.forPath(spark, "dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd1")\
.alias("target")\
.merge(in0.alias("source"), (col("source.customer_id") == col("target.customer_id")))\
.whenMatchedUpdateAll()\
.whenNotMatchedInsertAll()\
.execute()
else:
in0.write\
.format("delta")\
.mode("overwrite")\
.save("dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd1")
object writeDeltaMerge {
def apply(spark: SparkSession, in: DataFrame): Unit = {
import _root_.io.delta.tables._
if (DeltaTable.isDeltaTable(spark, "dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd1")) {
DeltaTable
.forPath(spark, "dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd1")
.as("target")
.merge(in0.as("source"), (col("source.customer_id") === col("target.customer_id")))
.whenMatched()
.updateAll()
.whenNotMatched()
.insertAll()
.execute()
}
else {
in0.write
.format("delta")
.mode("overwrite")
.save("dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd1")
}
}
}
SCD2
Let's use the Delta log to capture the historical customer_zip_code at the row-level.
Parameters
| Parameter | Description | Required |
|---|---|---|
| Key columns | List of key columns which would remain constant | True |
| Historic columns | List of columns which would change over time for which history needs to be maintained | True |
| From time column | Time from which a particular row became valid | True |
| To time column | Time till which a particular row was valid | True |
| Min/old-value flag | Column placeholder to store the flag as true for the first entry of a particular key | True |
| Max/latest flag | Column placeholder to store the flag as true for the last entry of a particular key | True |
| Flag values | Option to choose the min/max flag to be true/false or 0/1 | True |
Example
Using the same customer tables as in our merge example above, output and configurations for SCD2 merge will look like below:
Generated Code
- Python
- Scala
def writeDeltaSCD2(spark: SparkSession, in0: DataFrame):
from delta.tables import DeltaTable, DeltaMergeBuilder
if DeltaTable.isDeltaTable(spark, "dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd2"):
existingTable = DeltaTable.forPath(
spark, "dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd2"
)
updatesDF = in0.withColumn("minFlag", lit("true")).withColumn(
"maxFlag", lit("true")
)
existingDF = existingTable.toDF()
updateColumns = updatesDF.columns
stagedUpdatesDF = (
updatesDF.join(existingDF, ["customer_id"])
.where(
(
(existingDF["maxFlag"] == lit("true"))
& (
(
(
existingDF["customer_zip_code"]
!= updatesDF["customer_zip_code"]
)
| (
existingDF["customer_city"]
!= updatesDF["customer_city"]
)
)
| (existingDF["customer_state"] != updatesDF["customer_state"])
)
)
)
.select(*[updatesDF[val] for val in updateColumns])
.withColumn("minFlag", lit("false"))
.withColumn("mergeKey", lit(None))
.union(updatesDF.withColumn("mergeKey", concat("customer_id")))
)
existingTable.alias("existingTable").merge(
stagedUpdatesDF.alias("staged_updates"),
concat(existingDF["customer_id"]) == stagedUpdatesDF["mergeKey"],
).whenMatchedUpdate(
condition=(
(existingDF["maxFlag"] == lit("true"))
& (
(
(
existingDF["customer_zip_code"]
!= stagedUpdatesDF["customer_zip_code"]
)
| (
existingDF["customer_city"]
!= stagedUpdatesDF["customer_city"]
)
)
| (
existingDF["customer_state"]
!= stagedUpdatesDF["customer_state"]
)
)
),
set={"maxFlag": "false", "end_date": "staged_updates.updated_dt"},
)\
.whenNotMatchedInsertAll()\
.execute()
else:
in0.write\
.format("delta")\
.mode("overwrite")\
.save("dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd2")
object writeDeltaSCD2 {
def apply(spark: SparkSession, in: DataFrame): Unit = {
import _root_.io.delta.tables._
if (
DeltaTable.isDeltaTable(
spark,
"dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd2"
)
) {
val updatesDF = in
.withColumn("minFlag", lit("true"))
.withColumn("maxFlag", lit("true"))
val existingTable: DeltaTable = DeltaTable.forPath(
spark,
"dbfs:/FileStore/data_engg/delta_demo/silver/customers_scd2"
)
val existingDF: DataFrame = existingTable.toDF
val stagedUpdatesDF = updatesDF
.join(existingDF, List("customer_id"))
.where(
existingDF.col("maxFlag") === lit("true") && List(
existingDF.col("customer_zip_code") =!= updatesDF
.col("customer_zip_code"),
existingDF.col("customer_city") =!= updatesDF
.col("customer_city"),
existingDF.col("customer_state") =!= updatesDF
.col("customer_state")
).reduce((c1, c2) => c1 || c2)
)
.select(updatesDF.columns.map(x => updatesDF.col(x)): _*)
.withColumn("minFlag", lit("false"))
.withColumn("mergeKey", lit(null))
.union(updatesDF.withColumn("mergeKey", concat(col("customer_id"))))
existingTable
.as("existingTable")
.merge(
stagedUpdatesDF.as("staged_updates"),
concat(existingDF.col("customer_id")) === stagedUpdatesDF(
"mergeKey"
)
)
.whenMatched(
existingDF.col("maxFlag") === lit("true") && List(
existingDF.col("customer_zip_code") =!= stagedUpdatesDF
.col("customer_zip_code"),
existingDF.col("customer_city") =!= stagedUpdatesDF
.col("customer_city"),
existingDF.col("customer_state") =!= stagedUpdatesDF
.col("customer_state")
).reduce((c1, c2) => c1 || c2)
)
.updateExpr(
Map("maxFlag" → "false", "end_date" → "staged_updates.updated_dt")
)
.whenNotMatched()
.insertAll()
.execute()
} else {
in0.write
.format("delta")
.mode("overwrite")
.save("dbfs:/FileStore/data_engg/delta_demo/silver/orders")
}
}
}
SCD3
Using the same customer tables as in our merge example above, output and configurations for SCD3 merge will look like below. Let's track change for customer_zip_code by adding a column to show the previous value.
To check out our blogpost on making data lakehouse easier using Delta with Prophecy click here.