Aggregate
Allows you to group the data and apply aggregation methods and pivot operation.
Parameters
| Parameter | Description | Required |
|---|---|---|
| DataFrame | Input DataFrame | True |
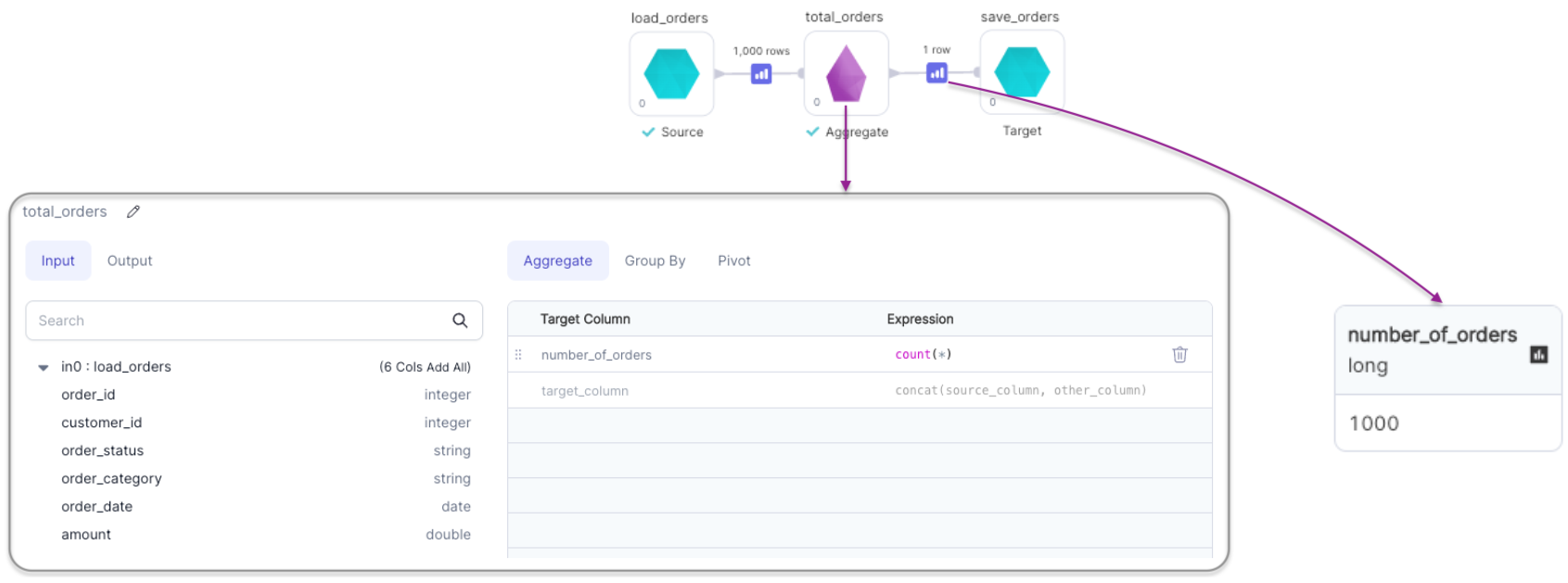
| Target column (Aggregate Tab) | Output column name of aggregated column | True |
| Expression (Aggregate Tab) | Aggregate function expression Eg: sum("amount"), count(*), avg("amount") | True |
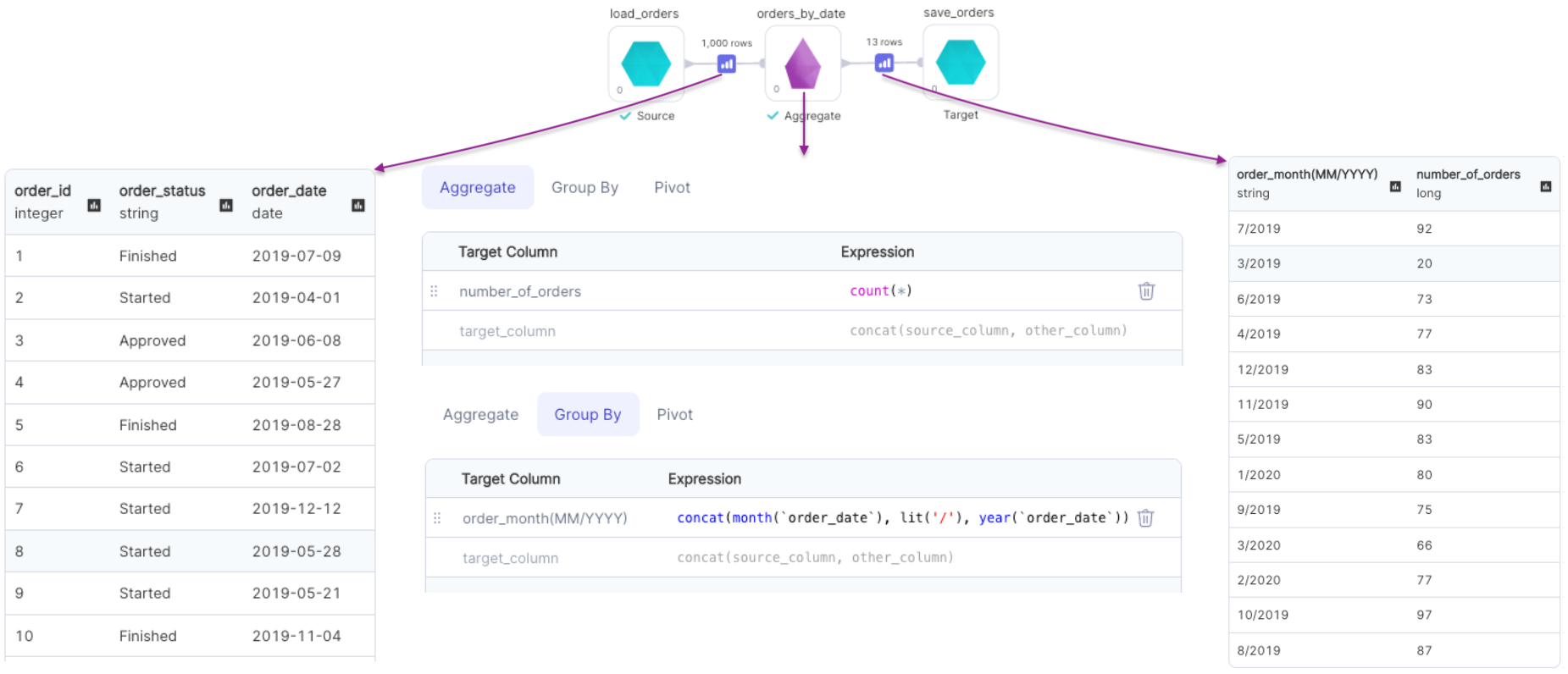
| Target column (Group By Tab) | Output column name of grouped column | Required if Pivot Column is present |
| Expression (Group By Tab) | Column expression to group on Eg: col("id"), month(col("order_date")) | Required if a Target Column(Group By) is present |
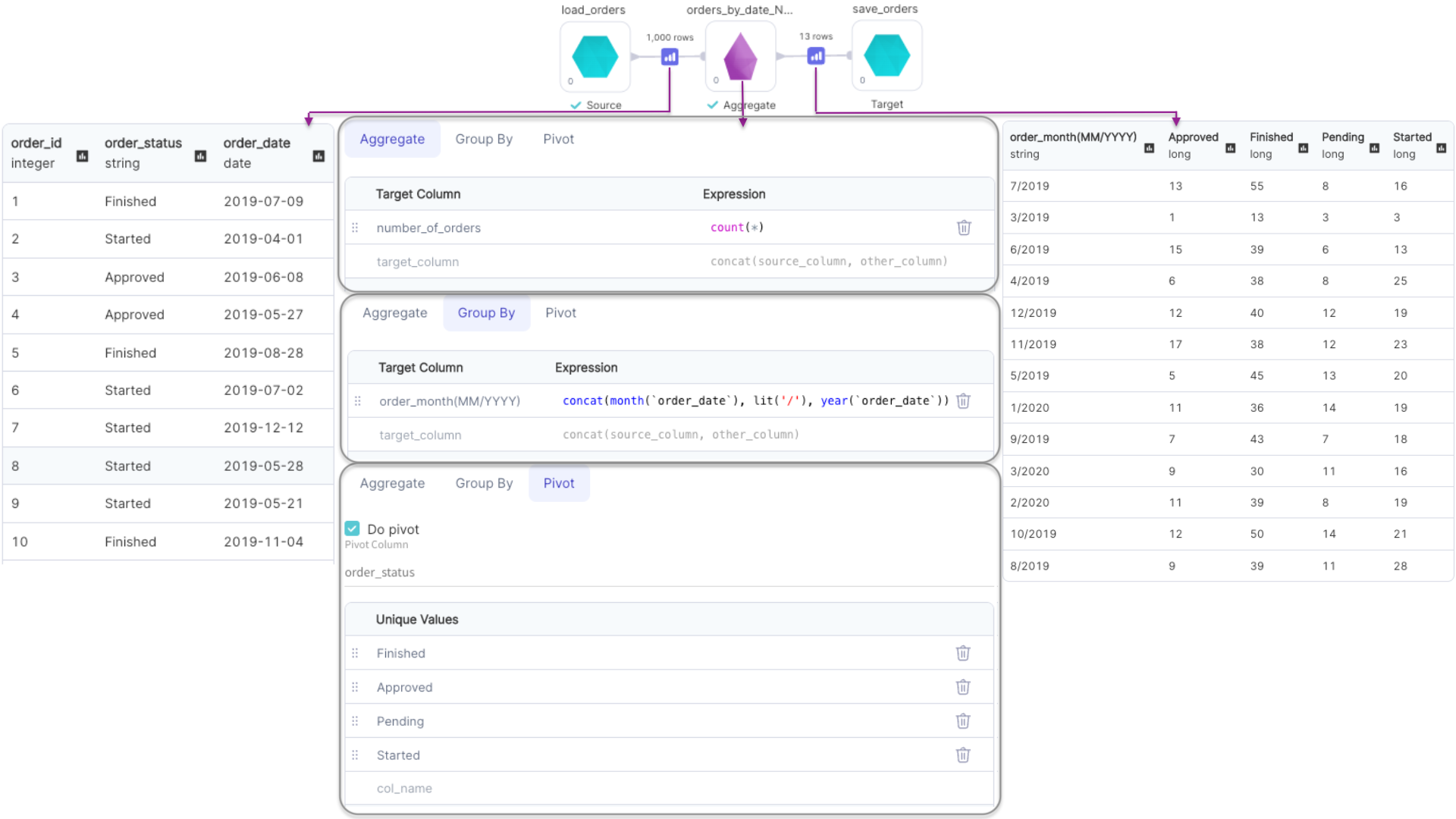
| Pivot column | Column name to pivot | False |
| Unique values | List of values in Pivot Column that will be translated to columns in the output DataFrame | False |
| Propagate All Input Columns | If true, all columns from the DataFrame would be propagated to output DataFrame. By default all columns apart from ones specified in group by, pivot, aggregate expressions are propagated as first(col_name) in the output DataFrame | False |
info
Providing Unique values while performing pivot operation improves the performance of the operation since Spark does not have to first compute the list of distinct values of Pivot Column internally.
Examples
Aggregation without Grouping
- Python
- Scala
def total_orders(spark: SparkSession, in0: DataFrame) -> DataFrame:
return in0.agg(count(lit(1)).alias("number_of_orders"))
object total_orders {
def apply(spark: SparkSession, in: DataFrame): DataFrame =
in.agg(count(lit(1)).as("number_of_orders"))
}
Aggregation with Grouping
- Python
- Scala
def orders_by_date(spark: SparkSession, in0: DataFrame) -> DataFrame:
df1 = in0.groupBy(concat(month(col("order_date")), lit("/"), year(col("order_date")))
.alias("order_month(MM/YYYY)"))
return df1.agg(count(lit(1)).alias("number_of_orders"))
object orders_by_date {
def apply(spark: SparkSession, in: DataFrame): DataFrame =
in.groupBy(
concat(month(col("order_date")), lit("/"), year(col("order_date")))
.as("order_month(MM/YYYY)")
)
.agg(count(lit(1)).as("number_of_orders"))
}
Pivot Columns
- Python
- Scala
def orders_by_date_N_status(spark: SparkSession, in0: DataFrame) -> DataFrame:
df1 = in0.groupBy(concat(month(col("order_date")), lit("/"), year(col("order_date"))).alias("order_month(MM/YYYY)"))
df2 = df1.pivot("order_status", ["Approved", "Finished", "Pending", "Started"])
return df2.agg(count(lit(1)).alias("number_of_orders"))
object orders_by_date_N_status {
def apply(spark: SparkSession, in: DataFrame): DataFrame =
in.groupBy(
concat(month(col("order_date")), lit("/"), year(col("order_date")))
.as("order_month(MM/YYYY)")
)
.pivot(col("order_status"),
List("Approved", "Finished", "Pending", "Started")
)
.agg(count(lit(1)).as("number_of_orders"))
}
Propagate all input Columns
This option in used to propagate all columns from input DataFrame to output DataFrame.
By default first(col_name) is used as aggregate function for columns not specified in group by, pivot, aggregate expressions.
- Python
- Scala
def Aggregate_1(spark: SparkSession, in0: DataFrame) -> DataFrame:
df1 = in0.groupBy(col("customer_id"))
return df1.agg(
*[first(col("order_date")).alias("order_date")],
*[
first(col(x)).alias(x)
for x in in0.columns
if x not in ["order_date", "customer_id"]
]
)
object Aggregate {
def apply(spark: SparkSession, in: DataFrame): DataFrame =
in.agg(first(col("order_date")).as("order_date"),
List() ++ in.columns.toList
.diff(List("order_date", "customer_id"))
.map(x => first(col(x)).as(x)): _*
)
}