File-based
File-based Streaming Sources and Targets
For file stream sources, incoming data files are incrementally and efficiently processed as they arrive in cloud storage. No additional setup is necessary, and cloud storage only needs to be accessible from the User's fabric.
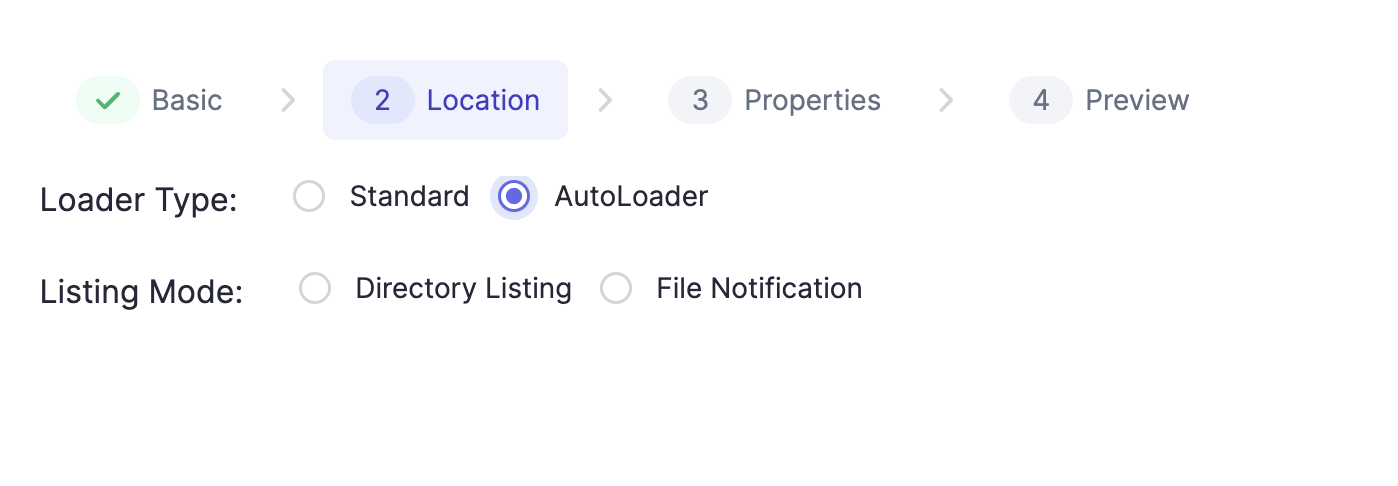
Autoloader is available for use with a Databricks fabric and supports loading data directory listing, as well as using file notifications via AWS's Simple Queue Service (SQS). More on Autoloader here. For different Cloud Storages supported by Autoloader, please check this page.
When you select Format and click NEXT, this Location Dialog opens:
Databricks Auto Loader
Databricks fabrics can utilize Auto Loader.
Auto Loader supports loading data directory listing as well as using AWS's Simple Queue Service (SQS) file notifications. More on this here. Stream sources using Auto Loader allow configurable properties that can be configured using the Field Picker on the gem:
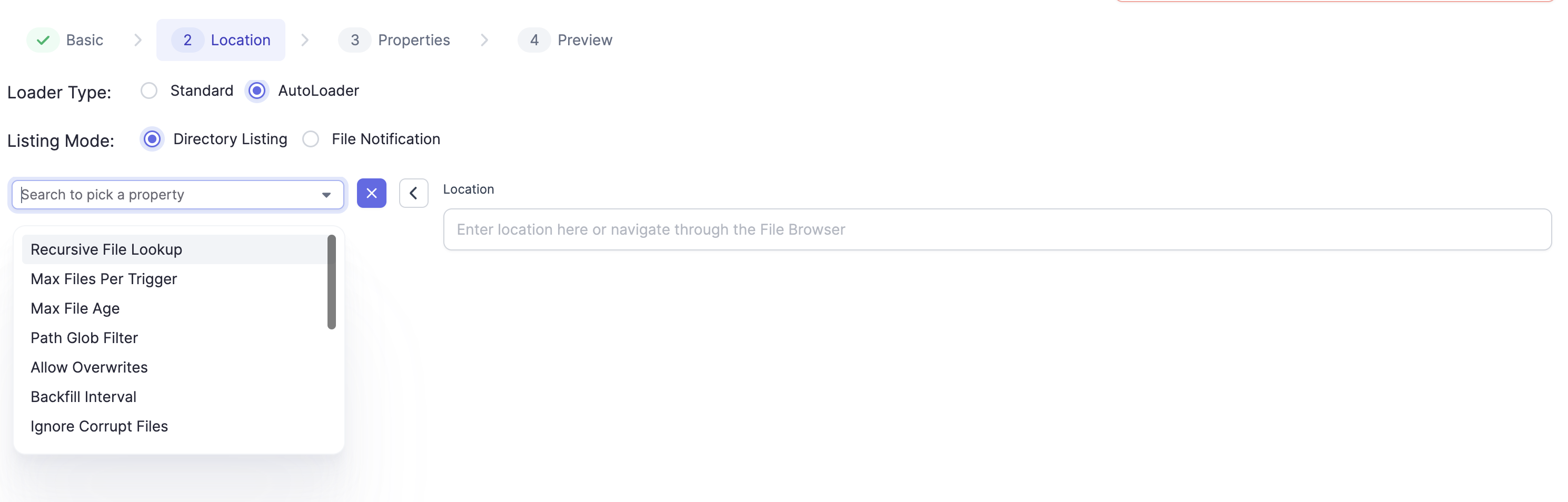
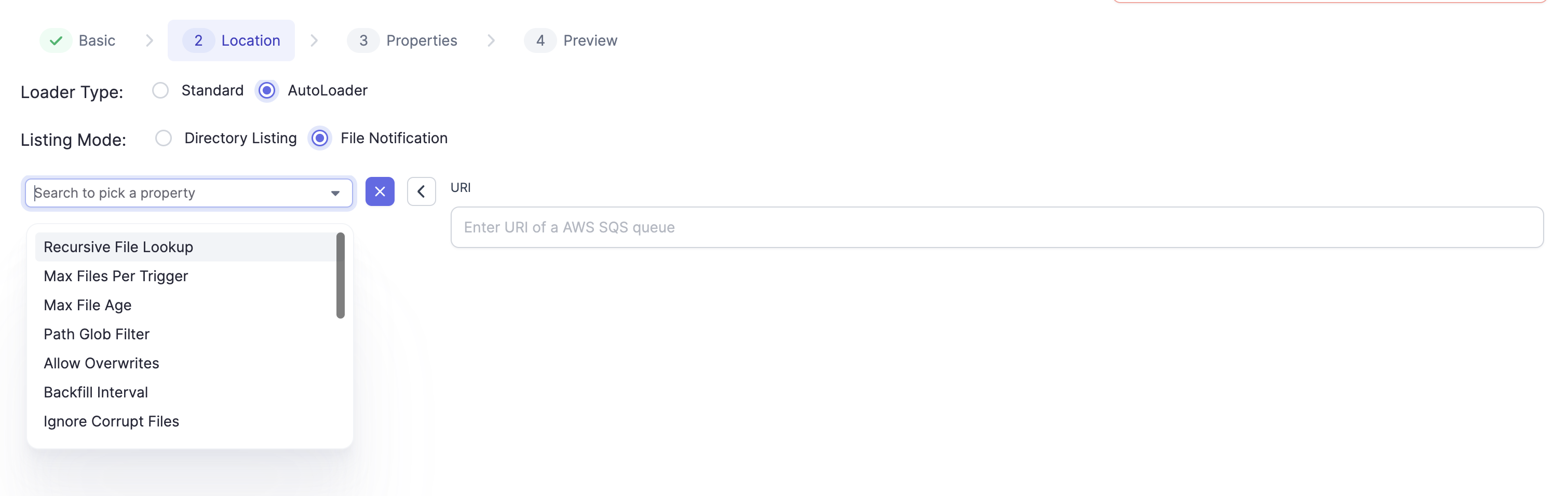
Formats Supported
The following file formats are supported. The gem properties are accessible under the Properties Tab by clicking on + :
- JSON: Native Connector Docs for Source here. Additional Autoloader Options here.
- CSV: Native Connector Docs for Source here. Additional Autoloader Options here.
- Parquet: Native Connector Docs for Source here. Additional Autoloader Options here.
- ORC: Native Connector Docs for Source here. Additional Autoloader Options here.
- Delta: A quickstart on Delta Lake Stream Reading and Writing is available here. Connector Docs are available here. Note, that this would require installing the Spark Delta Lake Connector if the user has an on prem deployment. We have additionally provided support for Merge in the Delta Lake Write Connector. (uses
forEatchBatchbehind the scenes).