Working with XLSX (Excel) files
If you've worked with numbers in your day-to-day operations, odds are you've run into a need to use Excel at one point or another. This tutorial is going to cover the two most basic scenarios: Reading and Writing.
For a full list of options supported by Prophecy when interacting with Excel files see here
Reading XLSX files
Reading an Excel file is quite easy in Prophecy! Simply follow these steps to create a new XLSX source.
- Select the XLSX format
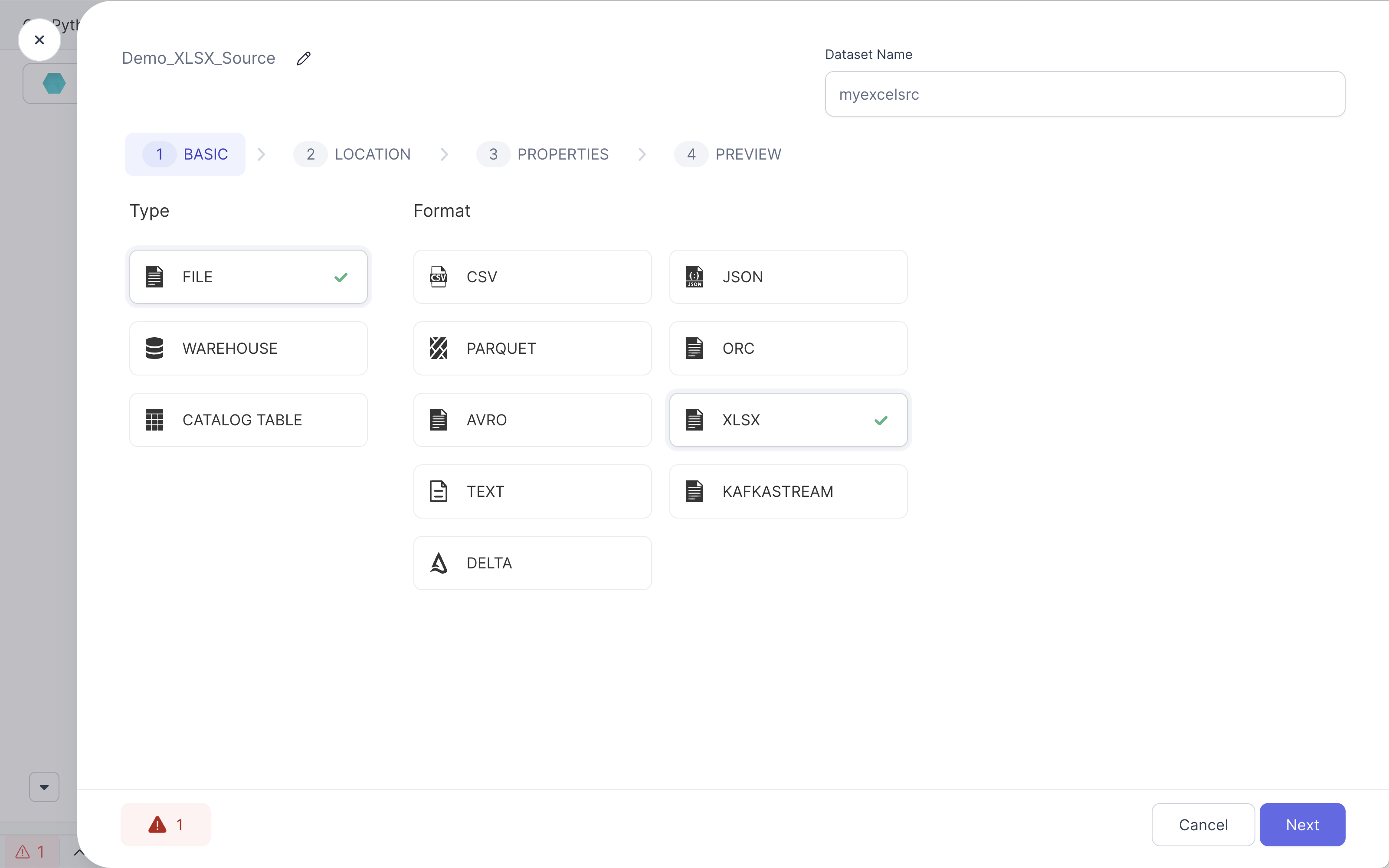
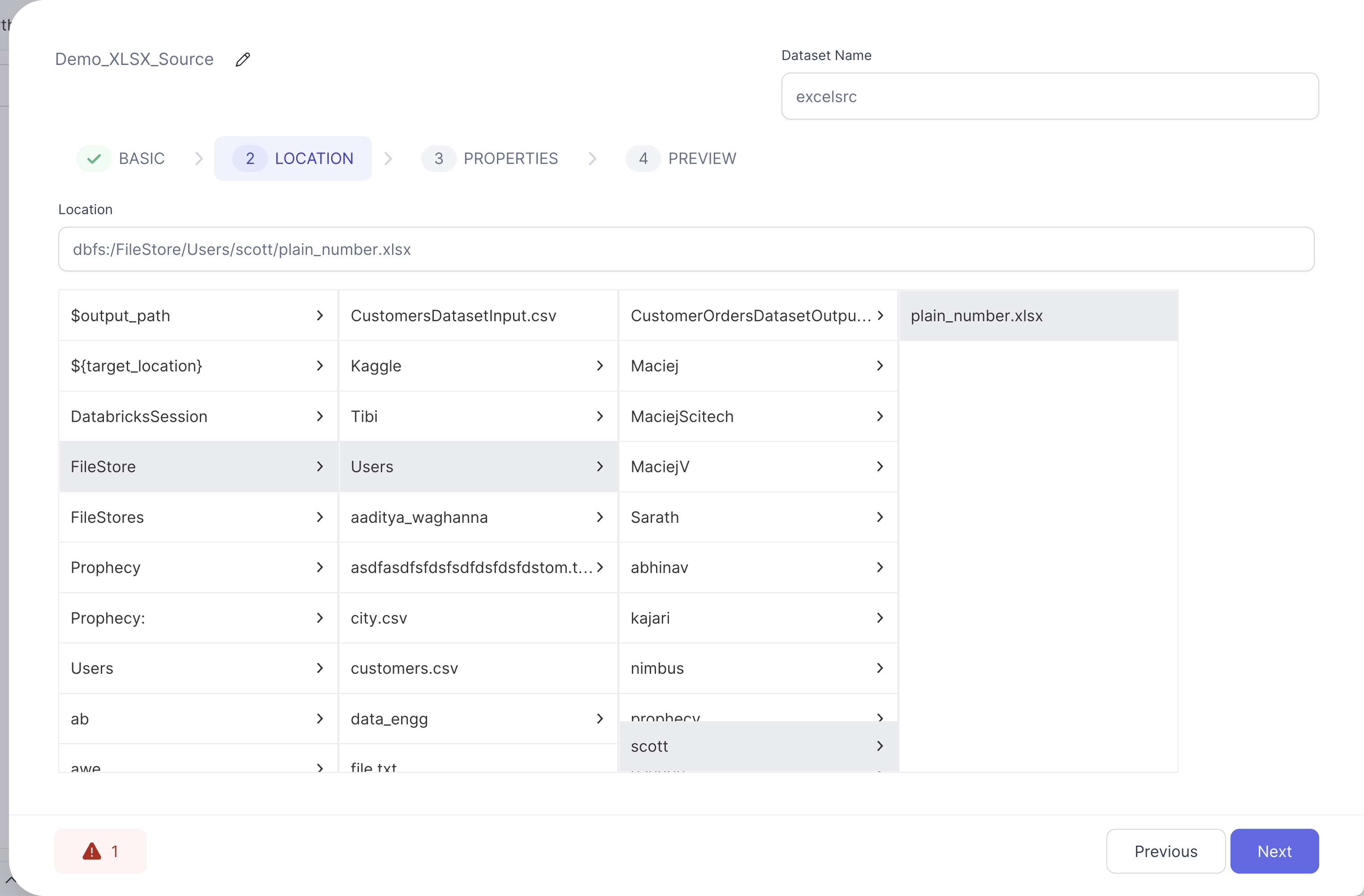
- Navigate to the desired XLSX source file
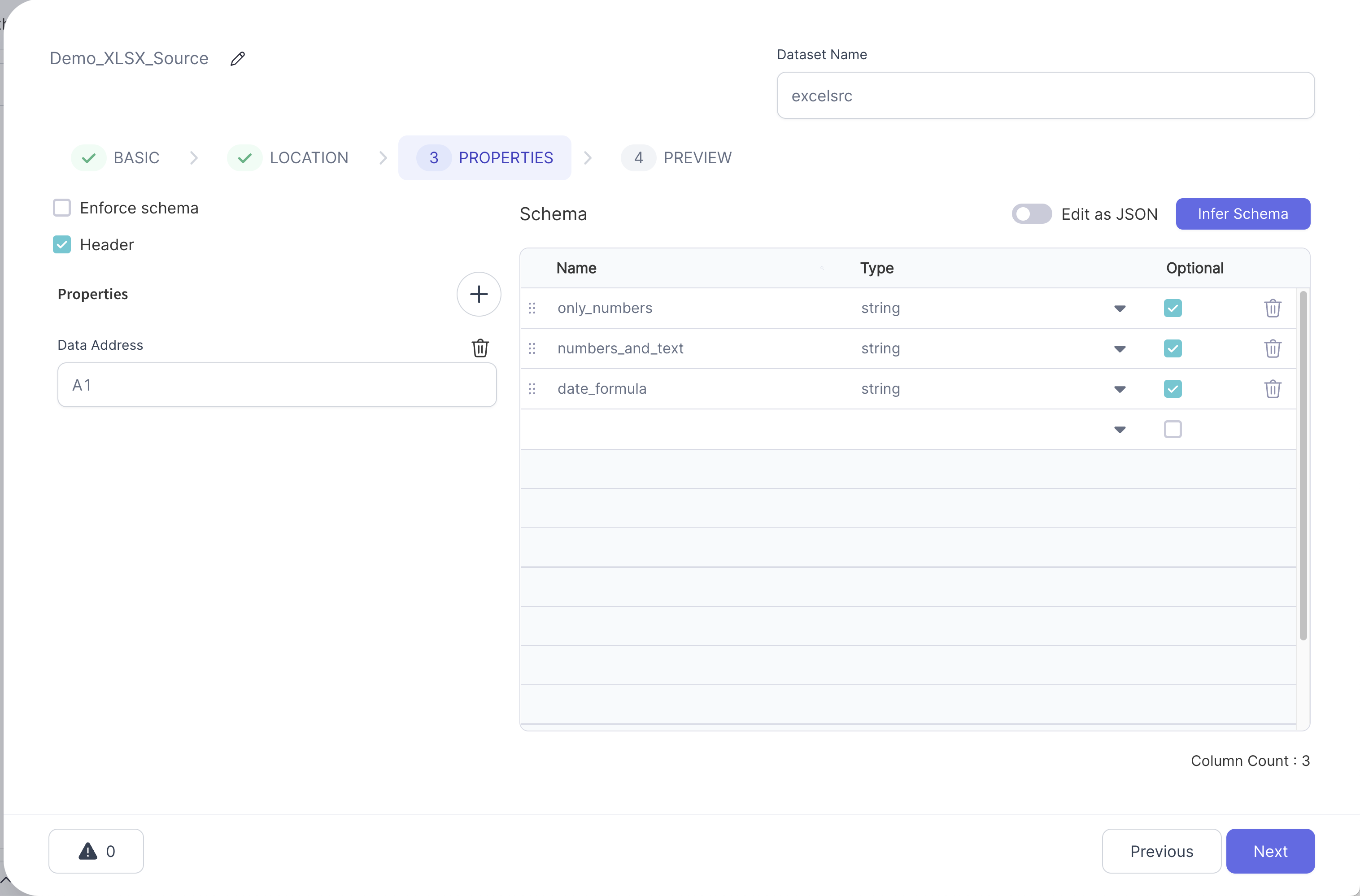
- Customize any properties you might need and tweak the schema to your liking
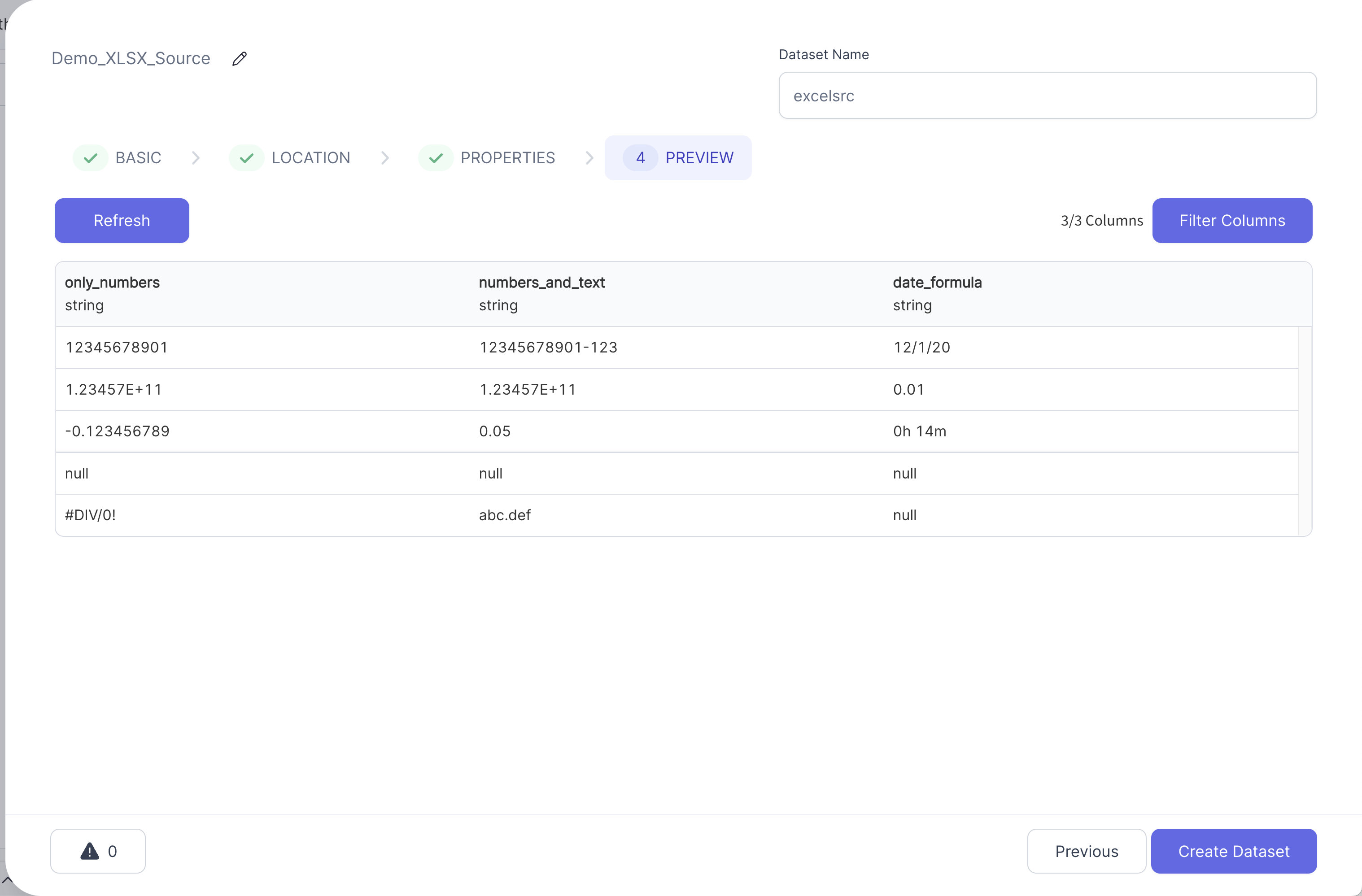
- Preview the file and double-check that the schema matches your intentions
Once the Source Gem is created and validation passes you'll be able to find the code of your new Source in the graph directory of your Pipeline code.
- Python
def Source_0(spark: SparkSession) -> DataFrame:
if Config.fabricName == "demos":
return spark.read\
.format("excel")\
.option("header", True)\
.option("dataAddress", "A1")\
.option("inferSchema", True)\
.load("dbfs:/FileStore/Users/scott/plain_number.xlsx")
else:
raise Exception("No valid dataset present to read fabric")
Writing XLSX files
Writing an Excel file is just as easy, with only one small caveat to be discussed after. Let's look at an example Pipeline with an XLSX output target:
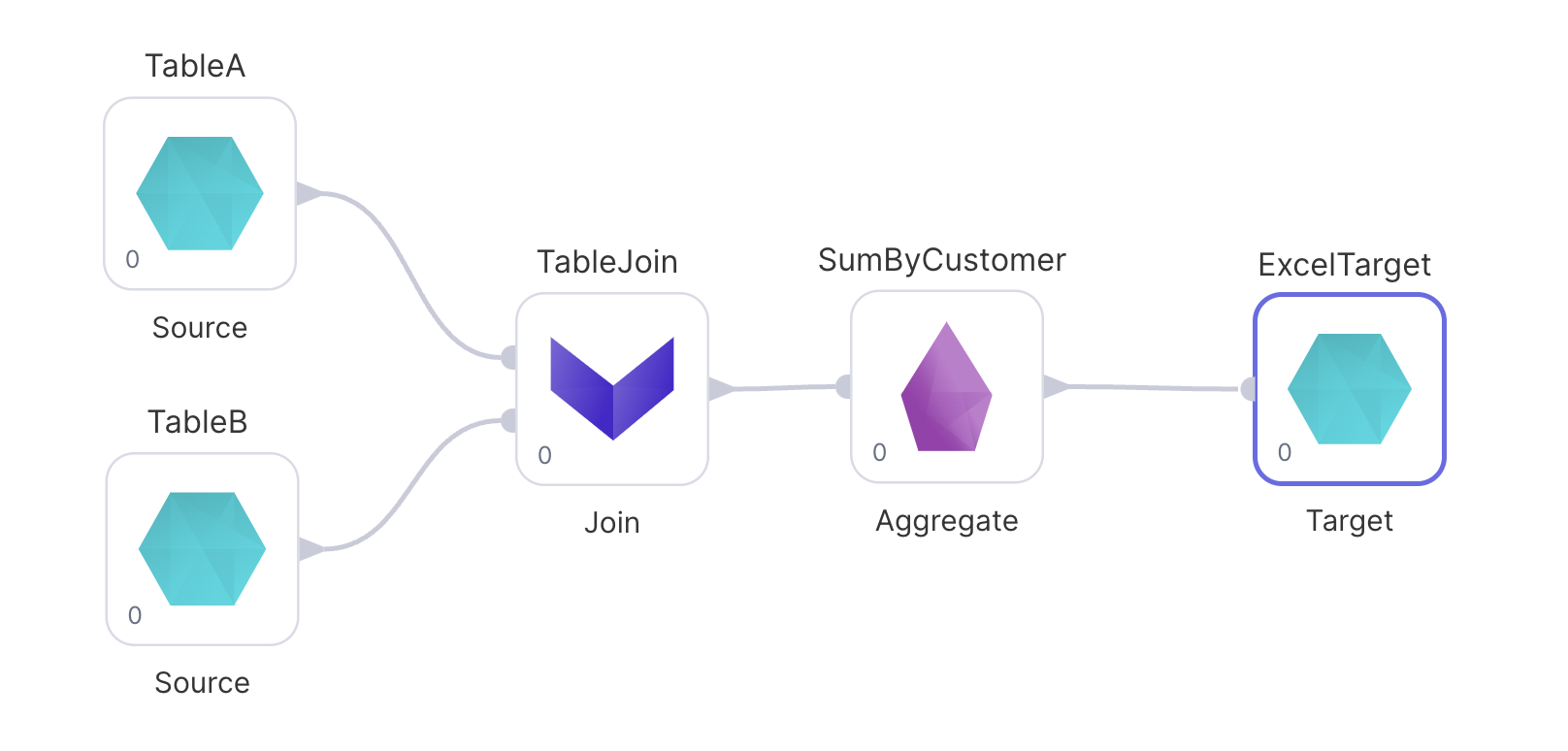
In this scenario we're building a report of spending by customer and want an XLSX file as output.
- Select the XLSX format
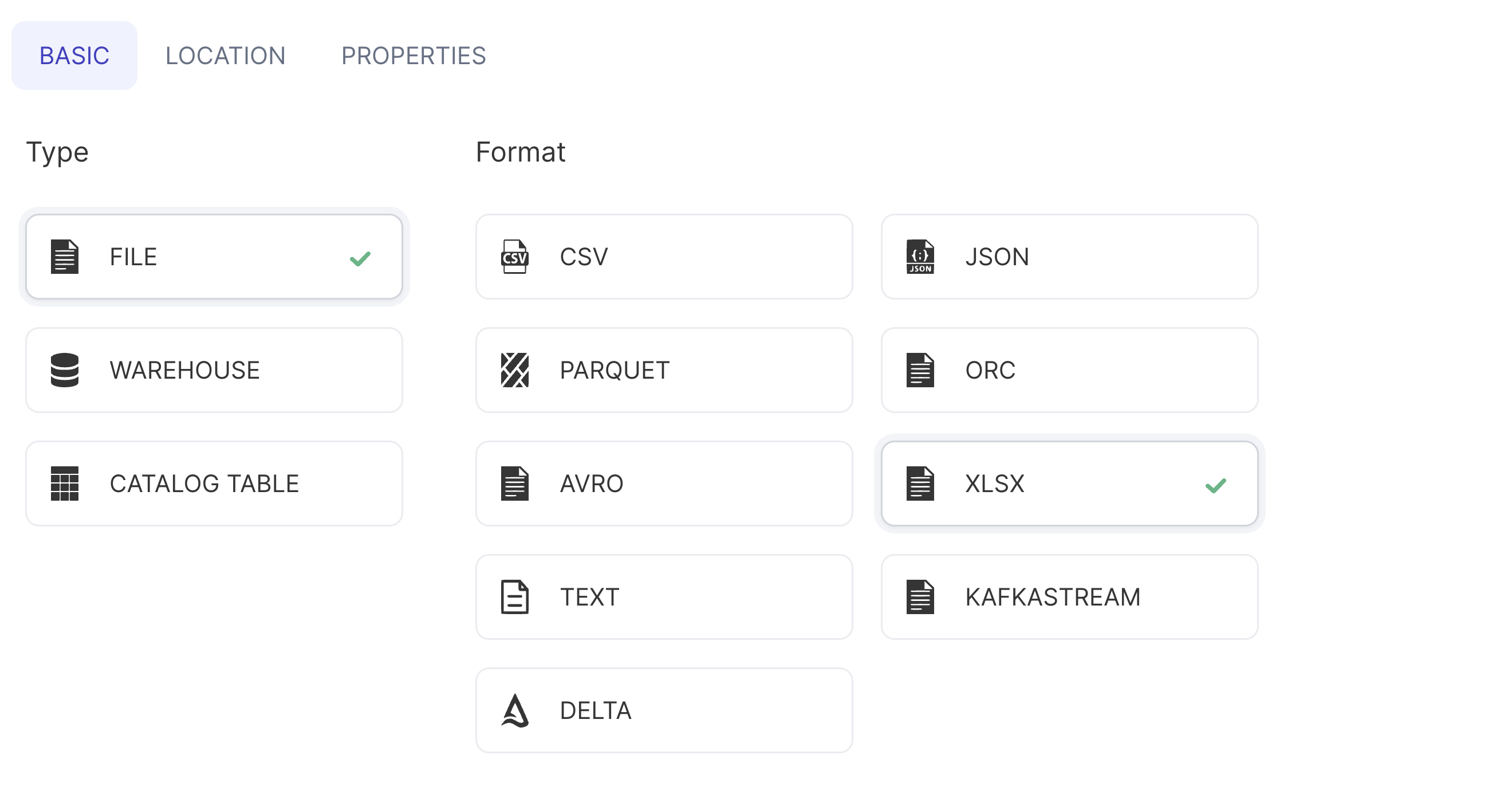
- Navigate to the target location

- Customize any properties needed when writing the output file
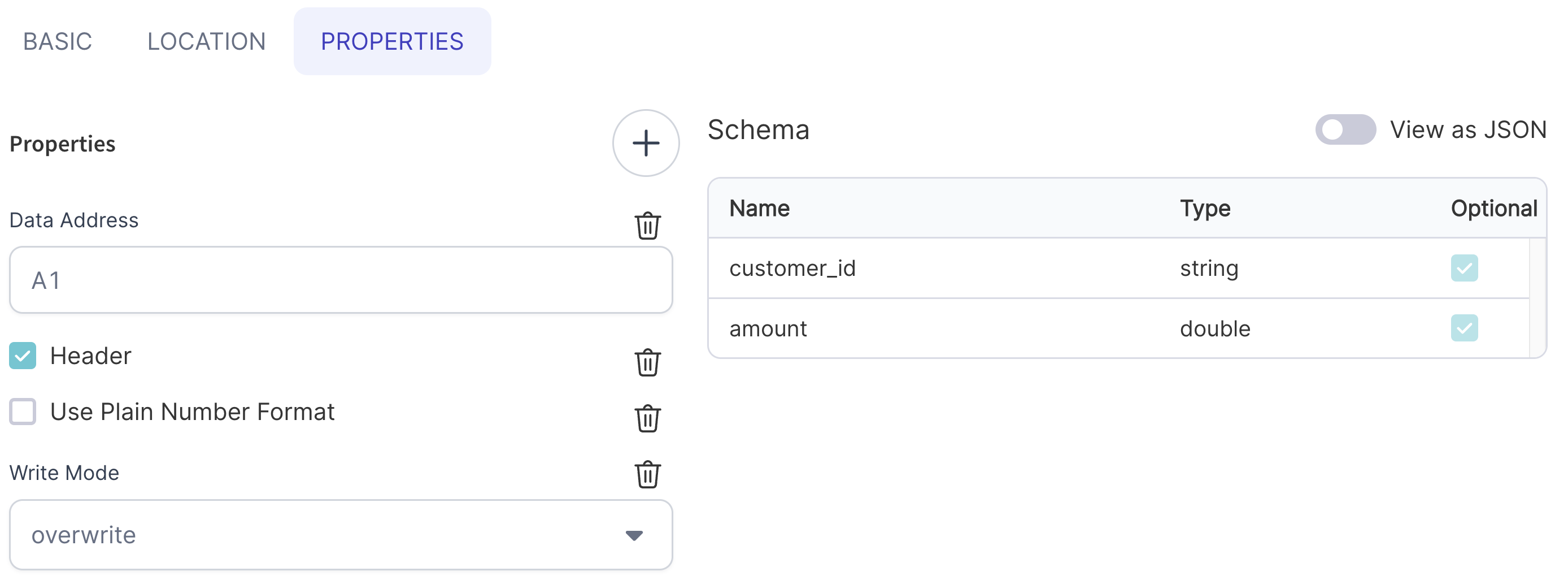
- Run the Pipeline!
Once the Target Gem is created and validation passes you'll be able to find the code of your new Target in the graph directory of your Pipeline code.
- Python
def ExcelTarget(spark: SparkSession, in0: DataFrame):
if Config.fabricName == "demos":
in0.write\
.format("excel")\
.option("header", True)\
.option("dataAddress", "A1")\
.option("usePlainNumberFormat", False)\
.mode("overwrite")\
.save("dbfs:/FileStore/Users/scott/customers.xlsx")
else:
raise Exception("No valid dataset present to read fabric")
Writing a single output file
As mentioned above, there's a caveat when working with any text-based files in Spark. Because of the distributed nature of the framework, you'll find that your output file is not just a single output file but instead a directory with multiple separately partitioned files within it.
For example, using dbfs:/FileStore/Users/scott/customers.xlsx as my Target location I can see the following in DBFS after running my Pipeline:
customers.xlsxis, in reality, a directory...
- ... that contains multiple partitions within it
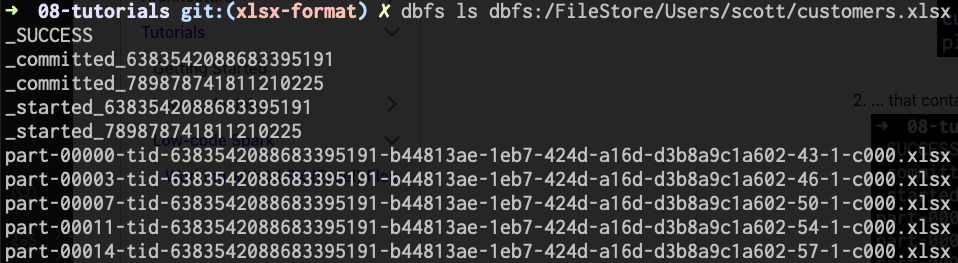
Each file within this directory will be a separate valid XLSX file with a segment of the overall output data. If you want to output only a single file, you'll need to change your Pipeline as such:
- Add a
RepartitionGem inCoalescemode with thePartition Countset to1.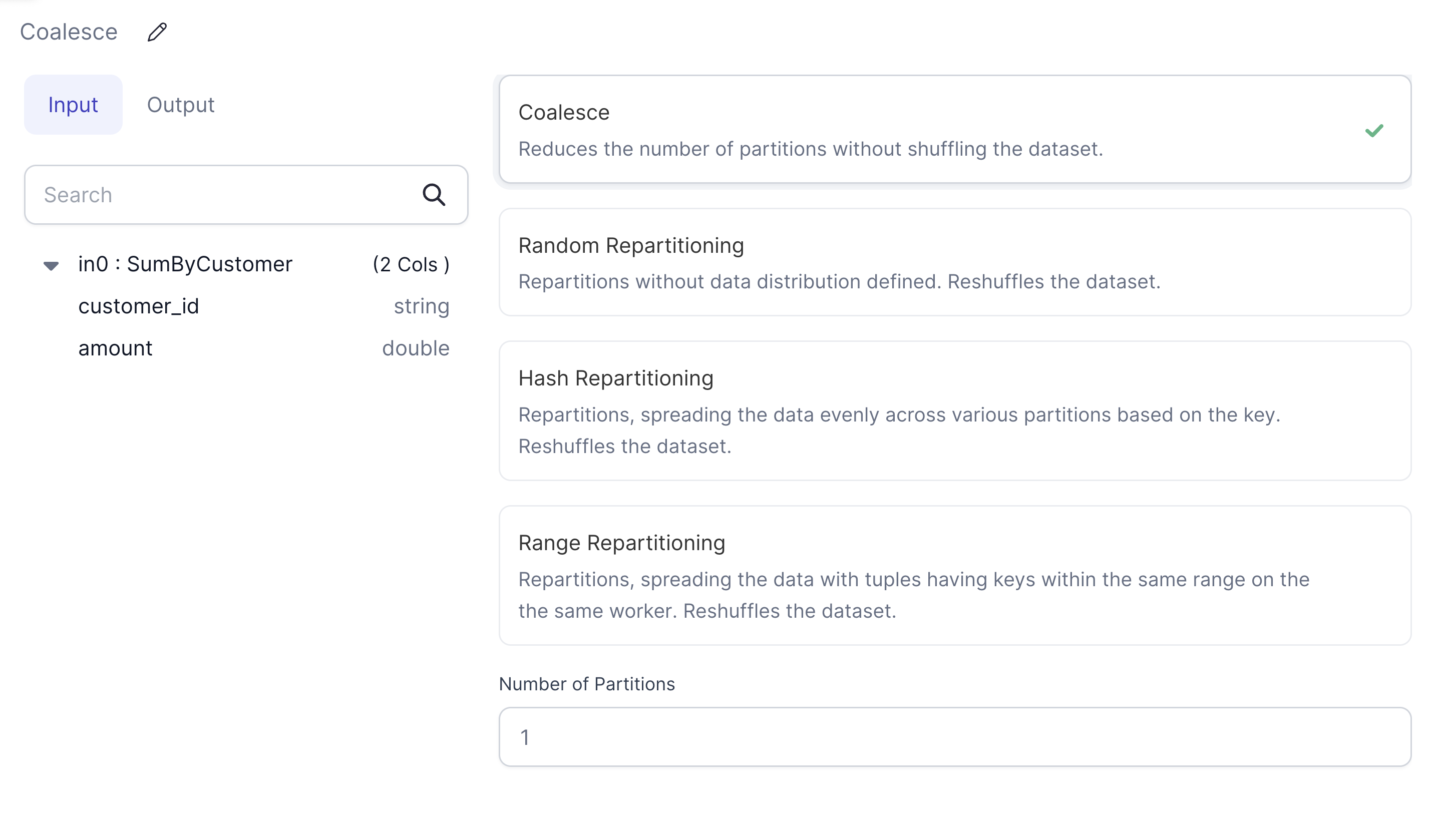
- Connect it between your second-to-last transformation and the
TargetGem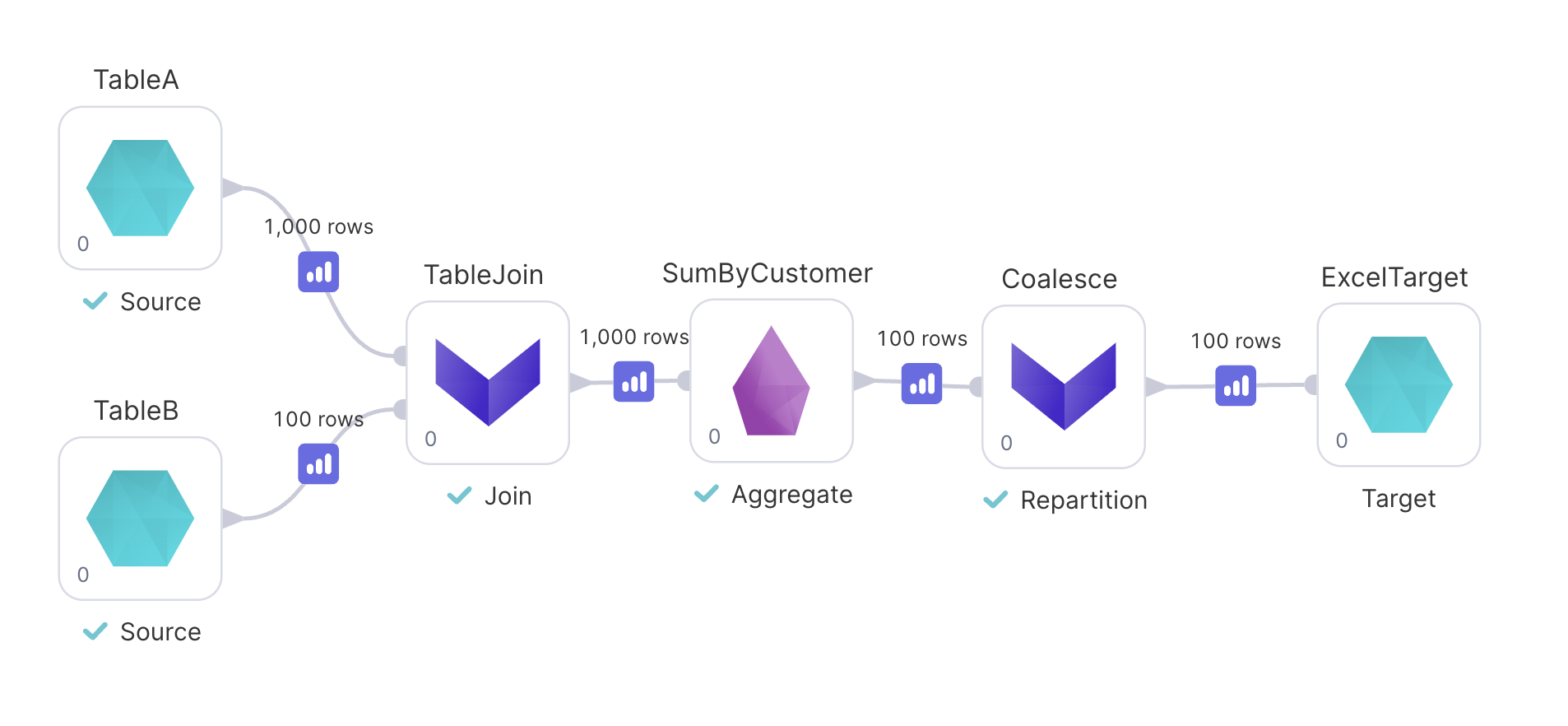
After running, your output will still be a directory, but this time it will only contain a single output file.
