Multi Jobs Trigger
To better structure your projects, sometimes you would like to create multiple different Jobs that trigger only a specific set of Pipelines. E.g. when using the Bronze, Silver, Gold architecture, one might want to have a project for each one of the stages and run each stage sequentially - run Gold after Silver is finished and Silver and after Bronze.
However, this poses a question: How to schedule multiple Jobs together?
Time-based Approach

One traditional approach is to schedule the sequential Jobs to run at different time intervals. E.g. the first Job can run at 7am and the second Job can run an hour later. This works well, if there's no data dependencies between those Jobs, or we're confident the first Job is going to always finish before the second Job.
But what would happen if our first Job (e.g. bronze ingestion) hasn't yet finished, but the second Job (e.g. silver cleanup) is about to start? This could potentially result in only partially processed data or even break the downstream Jobs completely. Recoverability and maintenance also becomes more difficult.
Trigger-based Approach
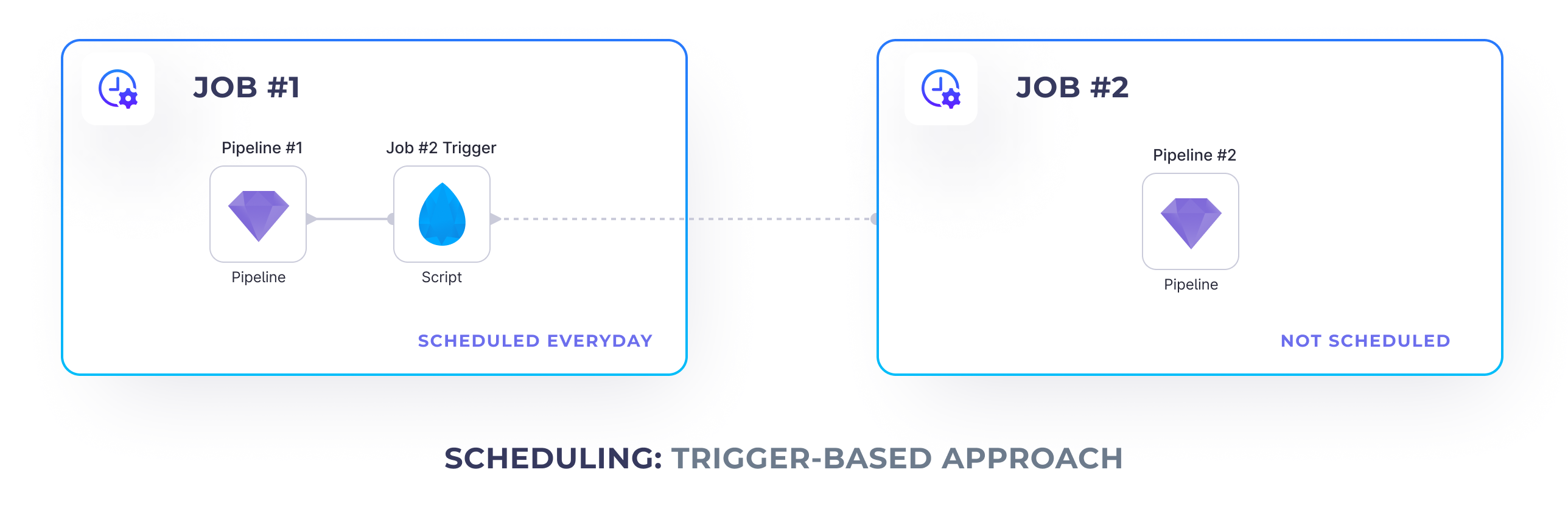
This is where, it might be worth to explore the trigger-based approach. Using this approach, we place additional triggers in our upstream Jobs that trigger the Jobs that should be executed after those finished.
To achieve that we can leverage the Script Gem
and Databricks Jobs API.
To be able to trigger a Job from within another Job, we need to:
- Deploy the Job we want to trigger and find it's Databricks
job_id - Add a
ScriptGem to the scheduled Job that triggers the other one
Deploying Jobs
First of all, to be able to trigger one Job from another, we need to release it and get it’s Databricks Job id.
Please note that this Job is disabled - as we’re only going to run it from a manual API, instead of a time-based trigger.
Job trigger
Once we have the ID of the Job that we'd like to trigger, we can go ahead and create a Script Gem in our upstream Job
that's going to run it.
Insert the following script to trigger a Job:
import requests
# STEP 1: Enter your workspace ID here
domain = 'https://dbc-147abc45-b6c7.cloud.databricks.com'
# STEP 2: Ensure you have a workspace.token secret created and accessible
token = dbutils.secrets.get(scope='workspace', key='token')
response = requests.post(
'%s/api/2.1/jobs/run-now' % (domain),
headers={'Authorization': 'Bearer %s' % token},
# STEP 3: Enter a job_id you'd like to trigger
json={'job_id': '549136548916411'}
)
if response.status_code == 200:
print(response.json())
else:
raise Exception('An error occurred triggering the job. Complete error: %s' % (response.json()))
Make sure to specify the following arguments:
- Databricks workspace url - How to find it?
- Databricks token - How to generate it?
- The Databricks Job id as previously embedded
Please note, that it's not recommended to store your Databricks token within the code directly, as that creates a potential venue for the attacker. A better approach is to leverage Databricks secrets. Check out this guide to learn how to create Databricks secrets.