Execution on Databricks
Cluster Types
Databricks clusters come with various Access Modes. To use Unity Catalog Shared clusters, check for feature support here.
Interims
During development, often the user will want to see their data to make more sense of it and to check whether the expected output is getting
generated or not after the transformation. Prophecy generates these data samples as Interims, which are temporarily cached previews of data after each gem.
To check more about interims, please refer here.
Depending on the type of clusters, we have two modes of Interims
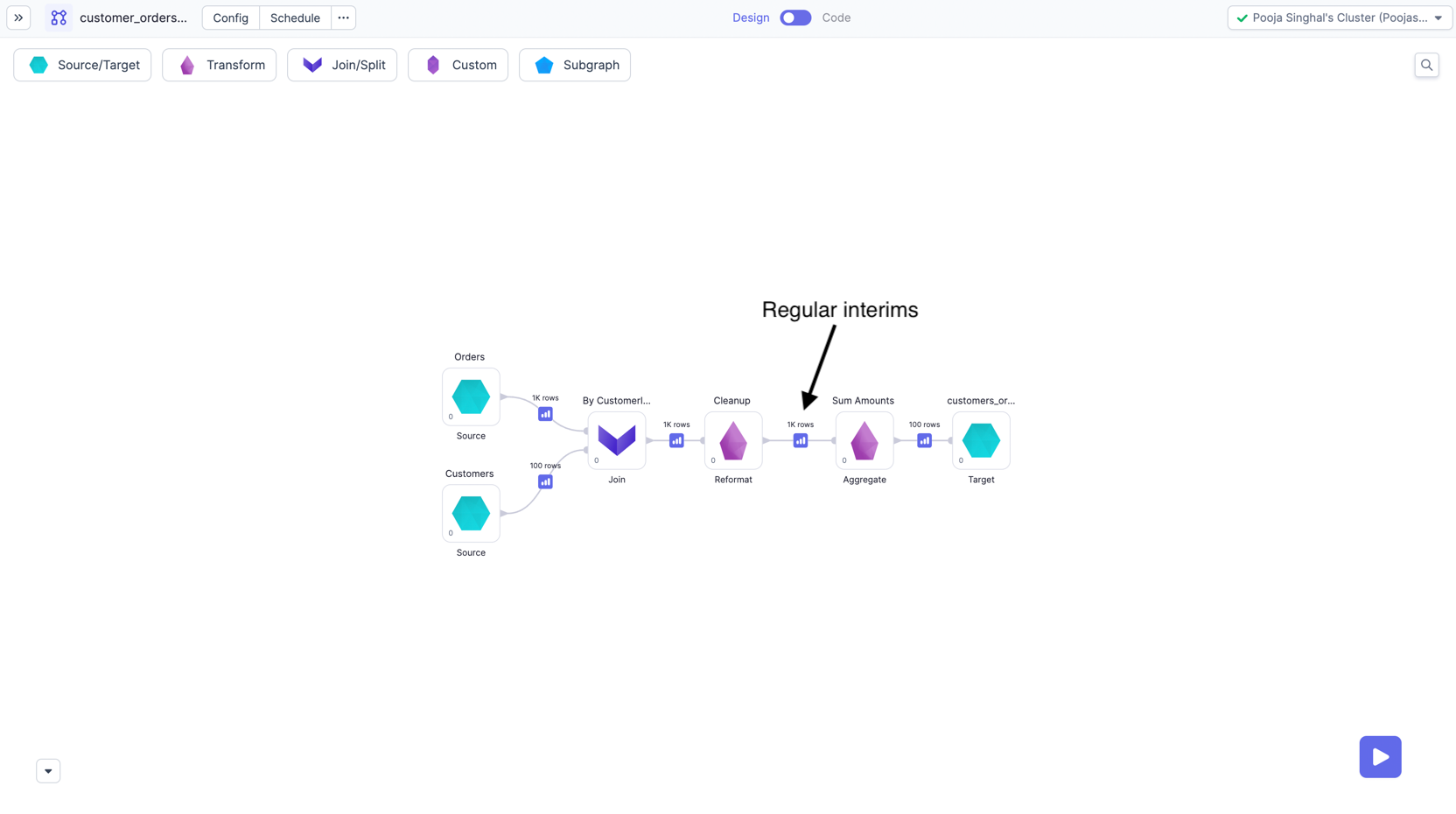
Regular Interims
For Single User clusters, and No isolation Shared clusters, we have interims available after each gem of pipeline. These are available on both Unity and Non Unity catalog workspaces.
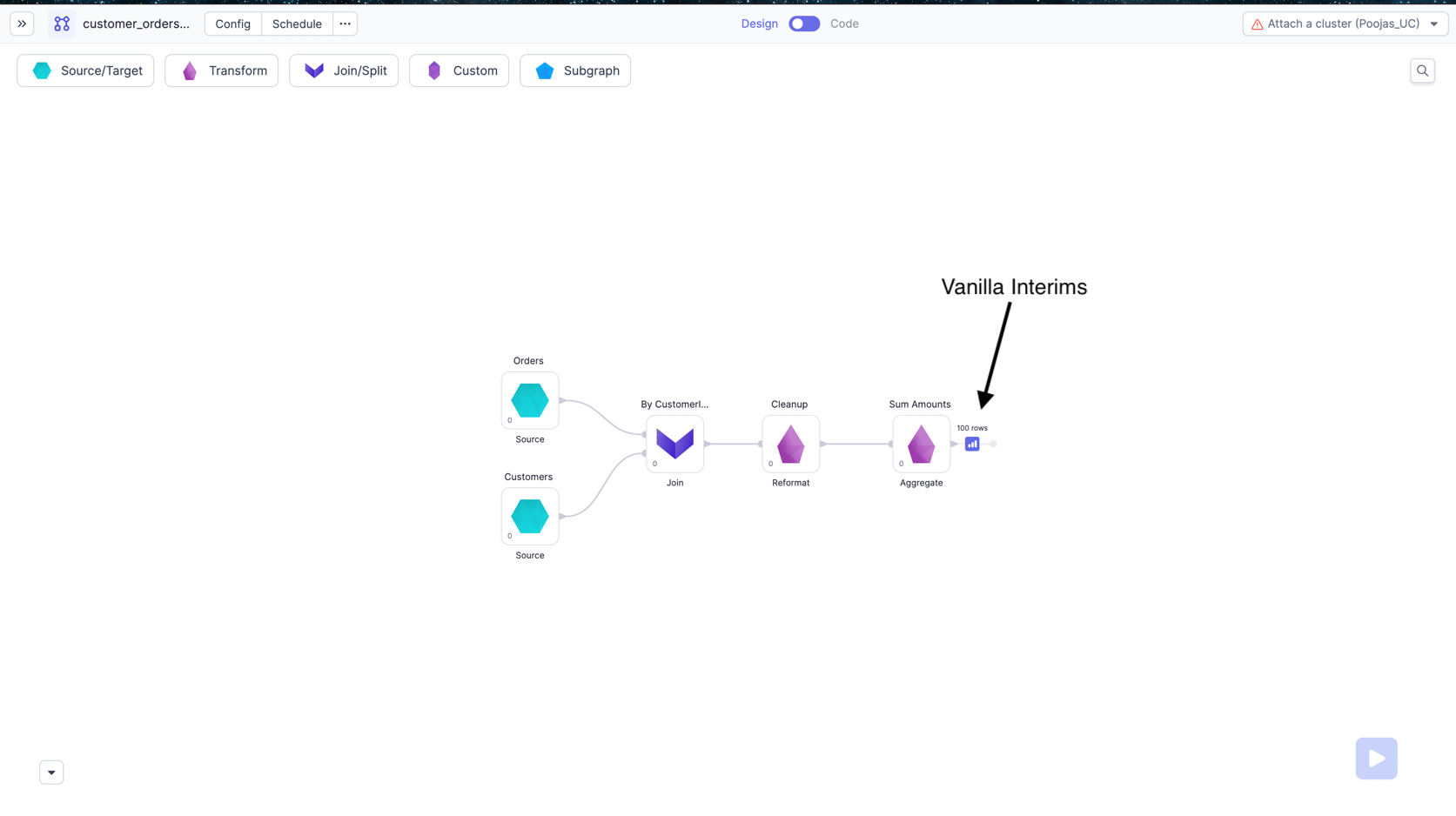
Vanilla Interims
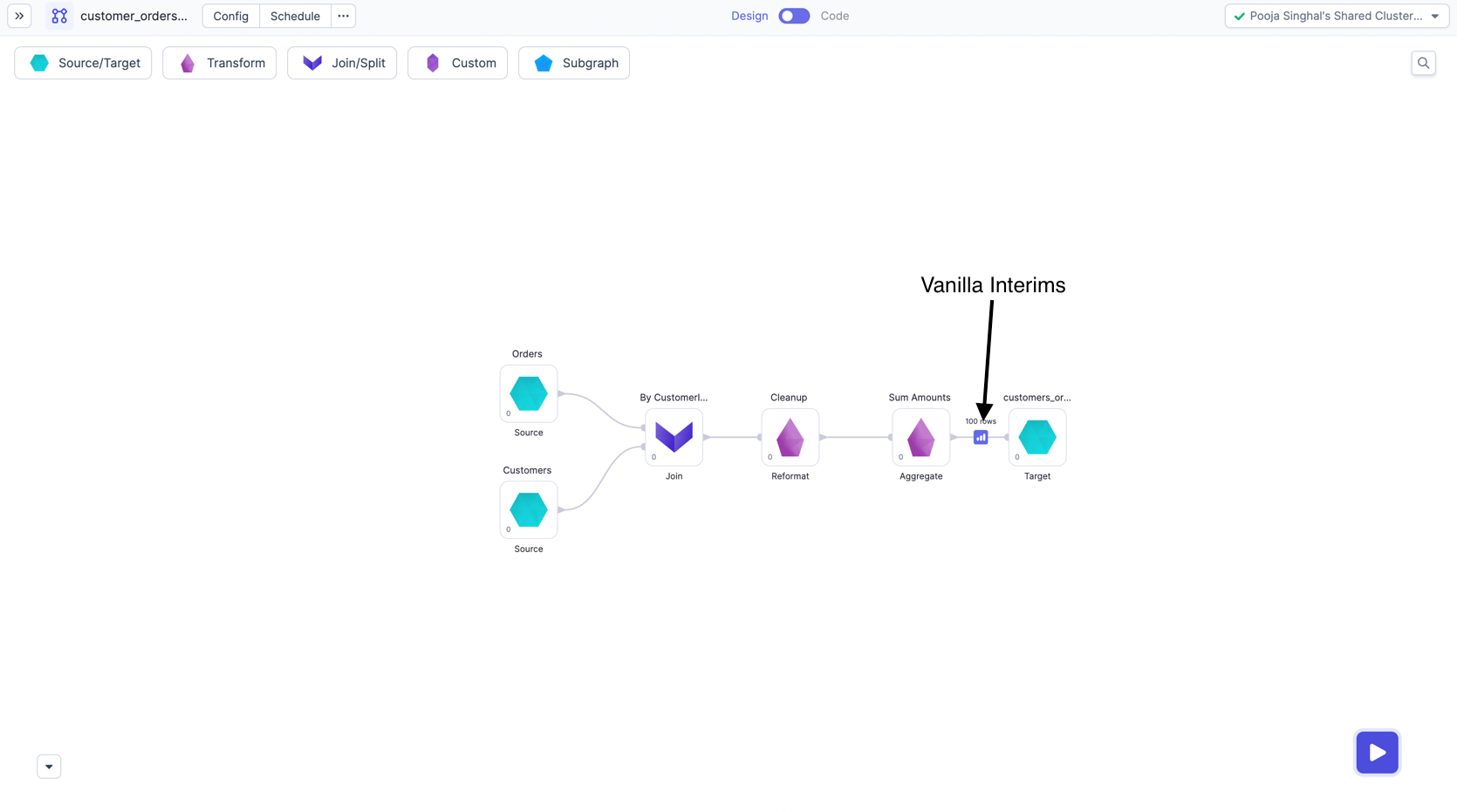
For Shared mode clusters, we have added interims on all Tail nodes of the pipeline.
These interims will come Just before Target gems, and if there is no Target gem, then as a dangling edge after last gem. See below images for the same.
Execution Metrics
When running pipelines and jobs, you may be interested to know few metrics related to execution like records read/written, bytes read/written, total time taken and Data samples b/w components. These dataset, pipeline-run and Job-run related metrics are accumulated and stored on your data plane and can be viewed later from Prophecy UI. For more details, refer here.
These metrics are not available for Shared mode clusters (both normal workspaces and Unity catalog workspaces). You should see a proper error when trying to get historical runs of pipelines/jobs executed on Shared mode clusters.
Refer below images for Execution Metrics on pipelines page.
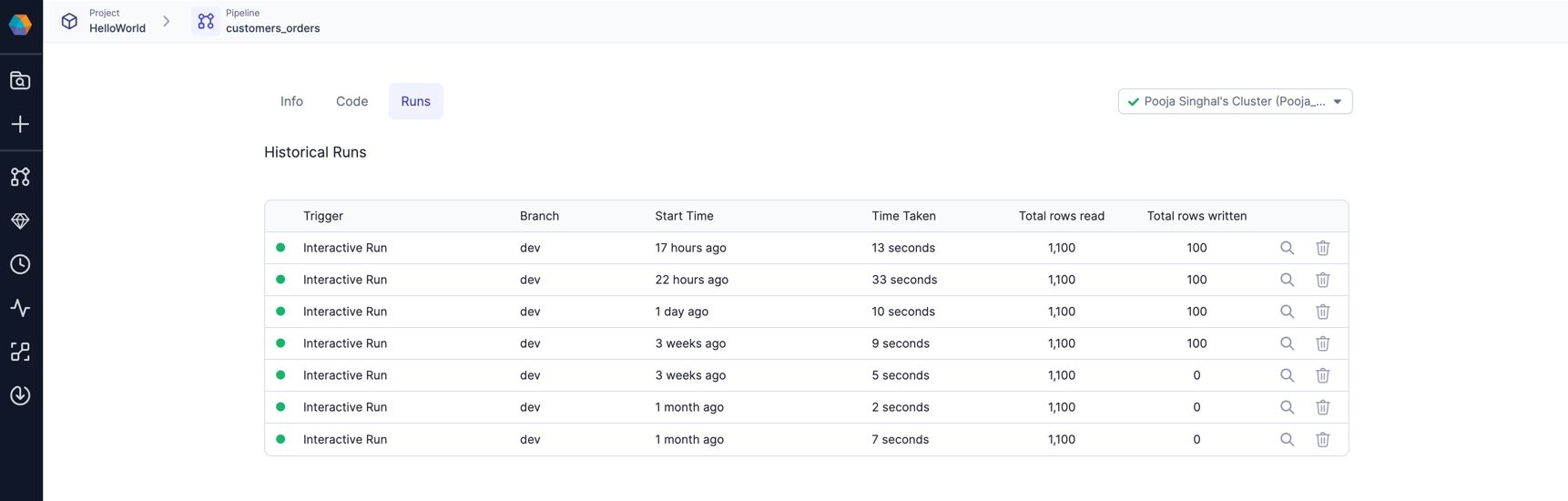
Each row here is one run of the pipeline. You can click and go to a particular run and see the interims for that run or metrics like Rows read/written, time taken, etc.
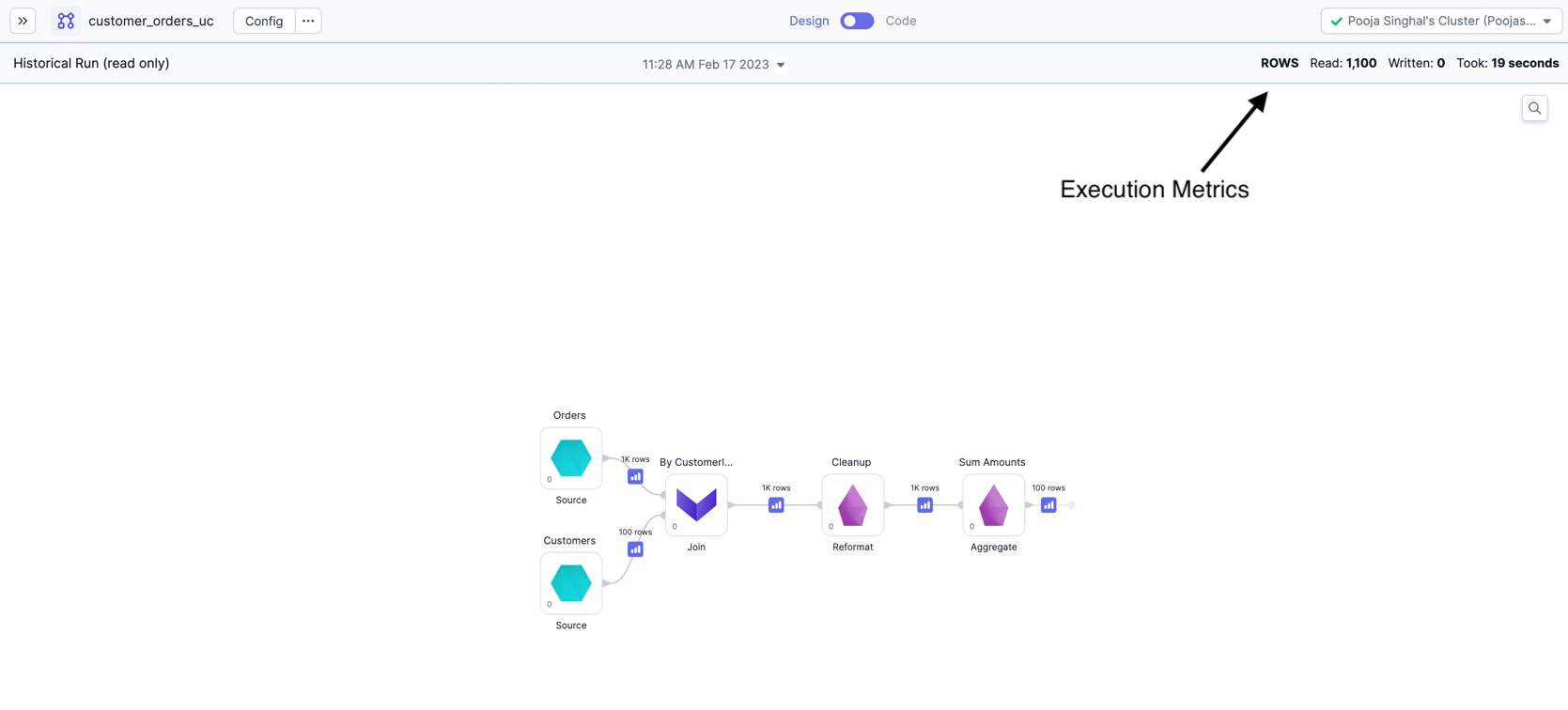
You can also see Execution Metrics for each dataset in the pipeline.
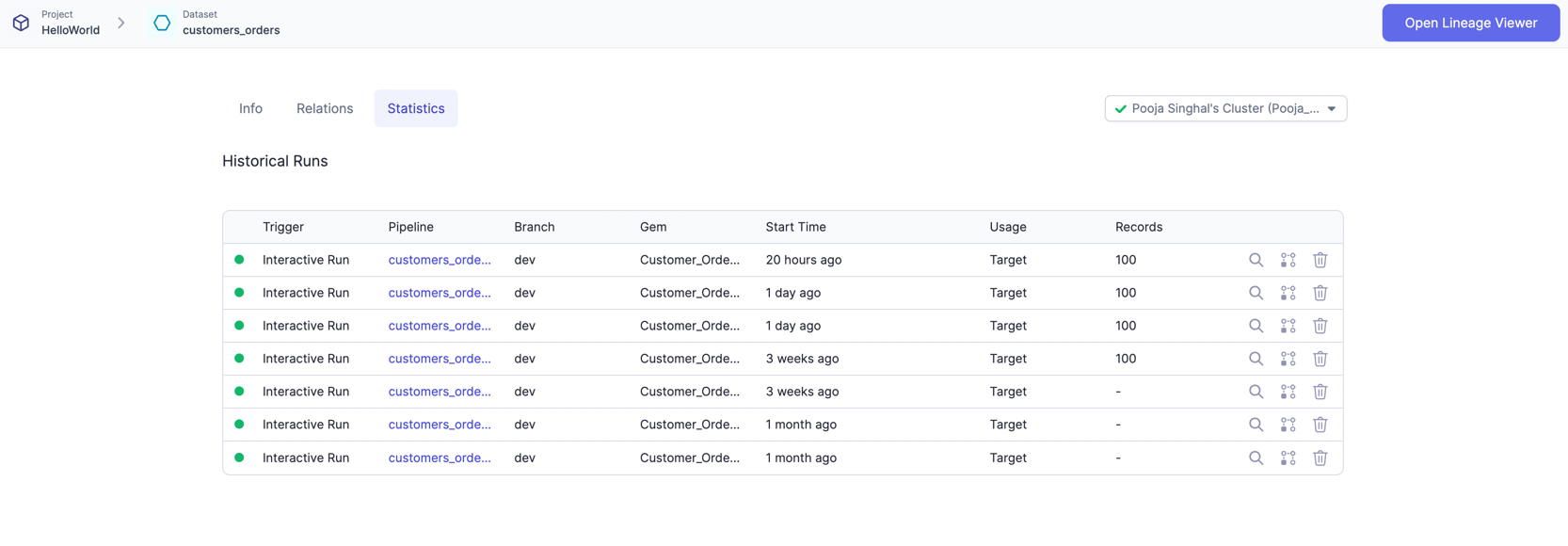
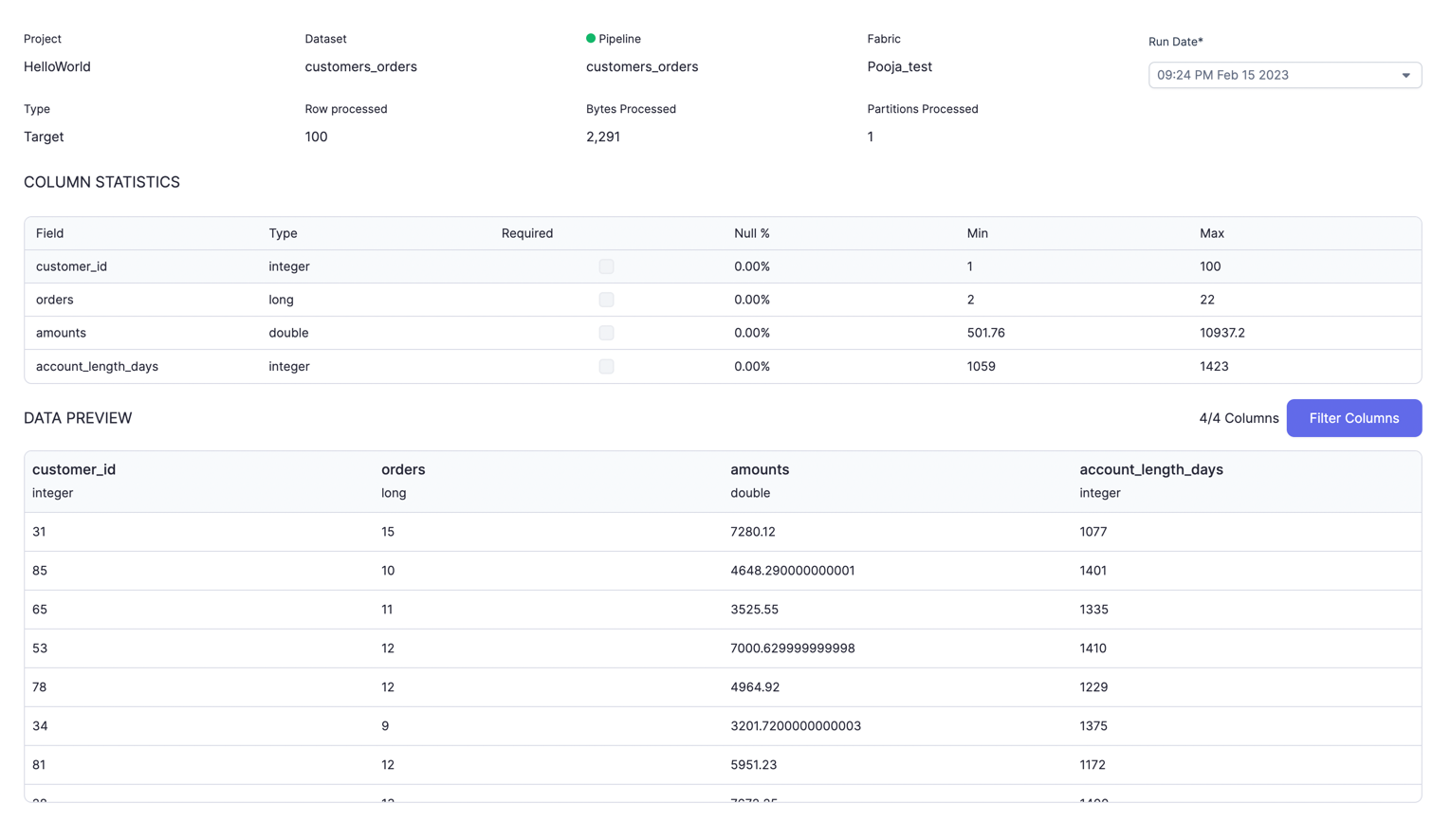
Each row here is one run where this dataset was used. You can click and go to a particular run and see more detailed insights on your data along with preview.
When using High Concurrency or Shared Mode Databricks Clusters you may notice a delay when running the first command, or when your cluster is scaling up to meet demand. This delay is due to Prophecy and pipeline dependencies (Maven or Python packages) being installed. For the best performance, it is recommended that you cache packages in an Artifactory or on DBFS. Please contact us to learn more about this.