Gem builder
Please contact us to learn more about the Enterprise offering.
Each Prophecy Pipeline is composed of individual operations, or Gems, that perform actions on data. While Prophecy offers dozens of Gems out-of-the-box, some data practitioners want to extend this idea and create their own Gems. Gem Builder allows enterprise users to add custom Gems. Create custom source, target, and transformation Gems, publish, and your team can utilize your custom Gem.
Getting Started
Custom Gem logic can be shared with other users within the Team and Organization. Navigate to the Gem listing to review Prophecy-defined and User-defined Gems. Add a new Gem or modify an existing Gem. Specify Gem name, preferred language, and Gem category. Paste/Write your code specification at the prompt. Click Preview to review the UX. Fill in some values and click save to check the Python or Scala code generated. When the Gem is ready, Publish! The new Custom Gem is available to use in Pipelines!
Please refer below video for a step-by-step example:
Tutorial
The Gem builder is a tool that enables users to create any custom Gems or modify existing ones. There are two types of Gems:
- DataSource Gems: These Gems enable the reading and writing of data from or to various data sources
- Transform Gems: These Gems apply transformations/joins/any other custom logic onto any DataFrame(s) that are passed into them.
Programmatically, a Gem is a component with the following parts:
- The Gem UI Component to get user information from the screen (This code is rendered on the Prophecy UI)
- The Gem Code Logic which is how the Gem acts within the context of a Pipeline.
Gem code can be written using either Python or Scala.
Defining a Gem
Example
- Python
- Scala
from prophecy.cb.server.base.ComponentBuilderBase import *
from pyspark.sql import *
from pyspark.sql.functions import *
from prophecy.cb.ui.UISpecUtil import getColumnsToHighlight2, validateSColumn
from prophecy.cb.ui.uispec import *
from prophecy.cb.util.StringUtils import isBlank
class Filter(ComponentSpec):
name: str = "Filter"
category: str = "Transform"
def optimizeCode(self) -> bool:
return True
@dataclass(frozen=True)
class FilterProperties(ComponentProperties):
columnsSelector: List[str] = field(default_factory=list)
condition: SColumn = SColumn("lit(True)")
def dialog(self) -> Dialog:
return Dialog("Filter").addElement(
ColumnsLayout(height="100%")
.addColumn(PortSchemaTabs(selectedFieldsProperty=("columnsSelector")).importSchema(), "2fr")
.addColumn(StackLayout(height=("100%"))
.addElement(TitleElement("Filter Condition"))
.addElement(
Editor(height=("100%")).withSchemaSuggestions().bindProperty("condition.expression")
), "5fr"))
def validate(self, component: Component[FilterProperties]) -> List[Diagnostic]:
return validateSColumn(component.properties.condition, "condition", component)
def onChange(self, oldState: Component[FilterProperties], newState: Component[FilterProperties]) -> Component[
FilterProperties]:
newProps = newState.properties
usedColExps = getColumnsToHighlight2([newProps.condition], newState)
return newState.bindProperties(replace(newProps, columnsSelector=usedColExps))
class FilterCode(ComponentCode):
def __init__(self, newProps):
self.props: Filter.FilterProperties = newProps
def apply(self, spark: SparkSession, in0: DataFrame) -> DataFrame:
return in0.filter(self.props.condition.column())
package io.prophecy.core.instructions.all
import io.prophecy.core.instructions.spec._
import io.prophecy.core.program.WorkflowContext
import org.apache.spark.sql.{DataFrame, SparkSession}
object Filter extends ComponentSpec {
val name: String = "Filter"
val category: String = "Transform"
override def optimizeCode: Boolean = true
type PropertiesType = FilterProperties
case class FilterProperties(
@Property("Columns selector")
columnsSelector: List[String] = Nil,
@Property("Filter", "Predicate expression to filter rows of incoming dataframe")
condition: SColumn = SColumn("lit(true)")
) extends ComponentProperties
def dialog: Dialog = Dialog("Filter")
.addElement(
ColumnsLayout(height = Some("100%"))
.addColumn(
PortSchemaTabs(selectedFieldsProperty = Some("columnsSelector")).importSchema(),
"2fr"
)
.addColumn(
StackLayout(height = Some("100%"))
.addElement(TitleElement("Filter Condition"))
.addElement(
Editor(height = Some("100%"))
.withSchemaSuggestions()
.bindProperty("condition.expression")
),
"5fr"
)
)
def validate(component: Component)(implicit context: WorkflowContext): List[Diagnostic] = {
val diagnostics =
validateSColumn(component.properties.condition, "condition", component)
diagnostics.toList
}
def onChange(oldState: Component, newState: Component)(implicit context: WorkflowContext): Component = {
val newProps = newState.properties
val portId = newState.ports.inputs.head.id
val expressions = getColumnsToHighlight(List(newProps.condition), newState)
newState.copy(properties = newProps.copy(columnsSelector = expressions))
}
class FilterCode(props: PropertiesType)(implicit context: WorkflowContext) extends ComponentCode {
def apply(spark: SparkSession, in: DataFrame): DataFrame = {
val out = in.filter(props.condition.column)
out
}
}
}
Parent Class
Every Gem class needs to extend a parent class from which it inherits the representation of the overall Gem. This includes the UI and the logic.
For transform Gems, you need to extend ComponentSpec (like in the example above), and for Source/Target Gems you need to extend DatasetSpec. We will see the difference between the two at the end.
First thing you give after this is the name and category of your Gem, "Filter" and "Transform" in this example.
Another thing to note here is optimizeCode. This flag can be set to True or False value depending on whether we want the Prophecy Optimizer to run on this code to simplify it.
In most cases, it's best to leave this value as True.
- Python
- Scala
class Filter(ComponentSpec):
name: str = "Filter"
category: str = "Transform"
def optimizeCode(self) -> bool:
return True
object Filter extends ComponentSpec {
val name: String = "Filter"
val category: String = "Transform"
override def optimizeCode: Boolean = true
Properties Classes
There is one class (seen here as FilterProperties) that contains a list of the properties to be made available to the user for this particular Gem. Think of these as all the values a user fills out within the template of this Gem, or any other UI state that you need to maintain (seen here as columnsSelector and condition).
The content of these Properties classes is persisted in JSON and stored in Git.
These properties can be set in the dialog function by taking input from user-controlled UI elements.
The properties are then available for reading in the following functions:
validate, onChange, apply
- Python
- Scala
@dataclass(frozen=True)
class FilterProperties(ComponentProperties):
columnsSelector: List[str] = field(default_factory=list)
condition: SColumn = SColumn("lit(True)")
case class FilterProperties(
@Property("Columns selector")
columnsSelector: List[String] = Nil,
@Property("Filter", "Predicate expression to filter rows of incoming dataframe")
condition: SColumn = SColumn("lit(true)")
) extends ComponentProperties
Additional information on these functions are available in the following sections.
Dialog (UI)
The dialog function contains code specific to how the Gem UI should look to the user.
- Python
- Scala
def dialog(self) -> Dialog:
return Dialog("Filter").addElement(
ColumnsLayout(height="100%")
.addColumn(PortSchemaTabs(selectedFieldsProperty=("columnsSelector")).importSchema(), "2fr")
.addColumn(StackLayout(height=("100%"))
.addElement(TitleElement("Filter Condition"))
.addElement(
Editor(height=("100%")).withSchemaSuggestions().bindProperty("condition.expression")
), "5fr"))
def dialog: Dialog = Dialog("Filter")
.addElement(
ColumnsLayout(height = Some("100%"))
.addColumn(
PortSchemaTabs(selectedFieldsProperty = Some("columnsSelector")).importSchema(),
"2fr"
)
.addColumn(
StackLayout(height = Some("100%"))
.addElement(TitleElement("Filter Condition"))
.addElement(
Editor(height = Some("100%"))
.withSchemaSuggestions()
.bindProperty("condition.expression")
),
"5fr"
)
)
The above Dialog code in the filter is rendered on UI like this:
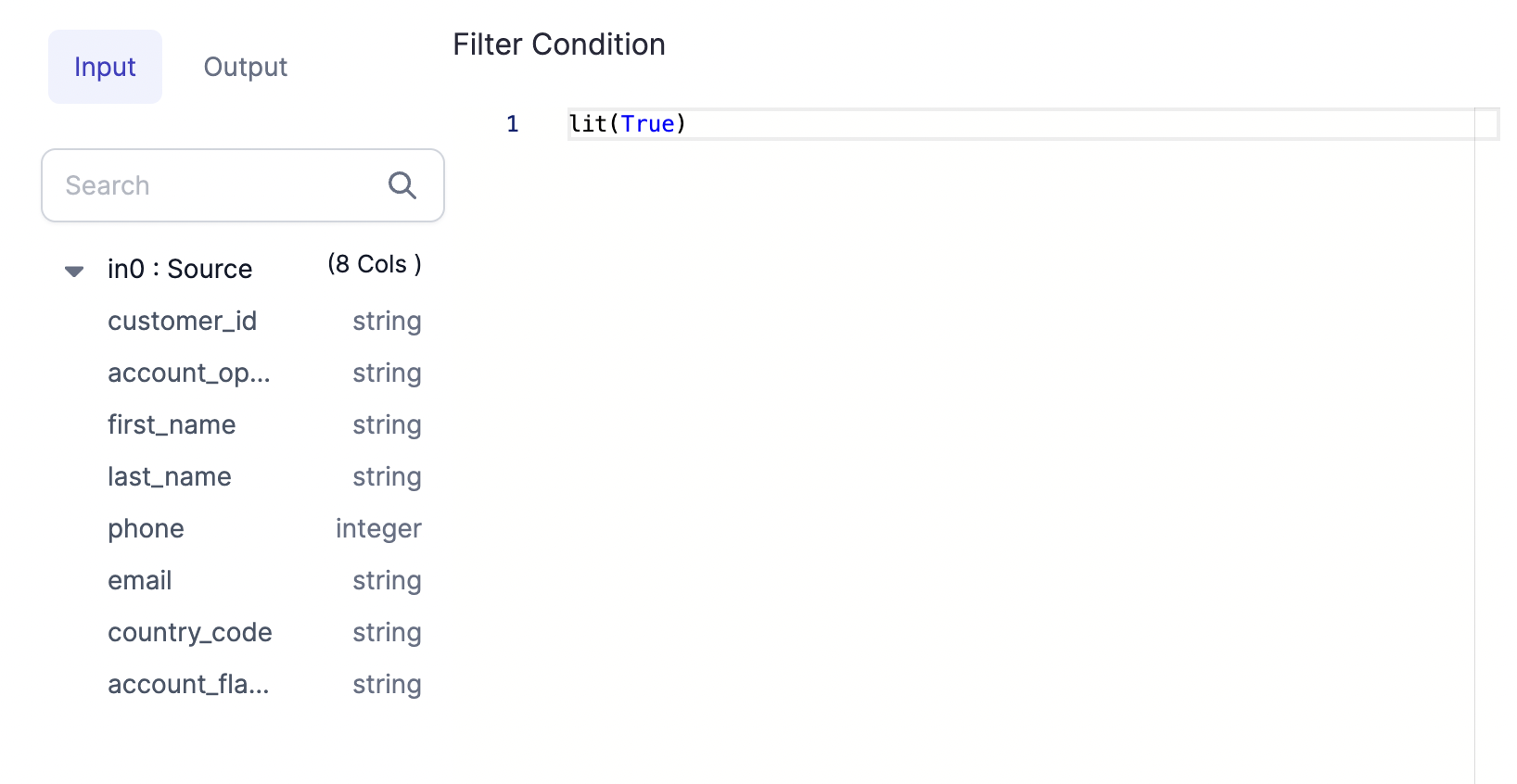
There are various UI components that can be defined for custom Gems such as scroll boxes, tabs, buttons, and more! These UI components can be grouped together in various types of panels to create a custom user experience when using the Gem.
After the Dialog object is defined, it's serialized as JSON, sent to the UI, and rendered there.
Depending on what kind of Gem is being created, either a Dialog or a DatasetDialog needs to be defined.
The Transformation Dialog: The Dialog for Transformation Gems (any Gem that is not a Dataset Gem) is created using the
dialogmethod, which must return a Dialog object.The Dataset Dialog: The Dialog for a Source/Target Gem is a
DatasetDialogobject. You will need to havesourceandtargetmethods defined.
Column Selector: This is a special property that you should add if you want to select the columns from UI and then highlight the used columns using the onChange function.
It is recommended to try out this dialogue code in Gem builder UI and see how each of these elements looks in UI.
Validation
The validate method performs validation checks so that in the case where there's any issue with any inputs provided for the user an Error can be displayed. In our example case, this would happen if the Filter condition is empty. Similarly, you can add any validation on your properties.
- Python
- Scala
def validate(self, component: Component[FilterProperties]) -> List[Diagnostic]:
return validateSColumn(component.properties.condition, "condition", component)
def validate(component: Component)(implicit context: WorkflowContext): List[Diagnostic] = {
val diagnostics =
validateSColumn(component.properties.condition, "condition", component)
diagnostics.toList
}
State Changes
The onChange method is given for the UI State transformations. You are given both the previous and the new incoming state and can merge or modify the state as needed. The properties of the Gem are also accessible to this function, so functions like selecting columns, etc. are possible to add from here.
- Python
- Scala
def onChange(self, oldState: Component[FilterProperties], newState: Component[FilterProperties]) -> Component[
FilterProperties]:
newProps = newState.properties
usedColExps = getColumnsToHighlight2([newProps.condition], newState)
return newState.bindProperties(replace(newProps, columnsSelector=usedColExps))
def onChange(oldState: Component, newState: Component)(implicit context: WorkflowContext): Component = {
val newProps = newState.properties
val portId = newState.ports.inputs.head.id
val expressions = getColumnsToHighlight(List(newProps.condition), newState)
newState.copy(properties = newProps.copy(columnsSelector = expressions))
}
Component Code
The last class used here is FilterCode which is inherited from ComponentCode class. This class contains the actual Spark code that needs to run on your Spark cluster. Here the above User Defined properties are accessible using self.props.{property}. The Spark code for the Gem logic is defined in the apply function. Input/Output of apply method can only be DataFrame or list of DataFrames or empty.
For example, we are calling the .filter() method in this example in the apply function.
- Python
- Scala
class FilterCode(ComponentCode):
def __init__(self, newProps):
self.props: Filter.FilterProperties = newProps
def apply(self, spark: SparkSession, in0: DataFrame) -> DataFrame:
return in0.filter(self.props.condition.column())
class FilterCode(props: PropertiesType)(implicit context: WorkflowContext) extends ComponentCode {
def apply(spark: SparkSession, in: DataFrame): DataFrame = {
val out = in.filter(props.condition.column)
out
}
}
You can preview the component in the Gem Builder to see how it looks. You can modify the properties and then save it to preview the generated Spark code which will eventually run on your cluster.
To assist the Spark Catalyst Optimizer to build scalable code, Prophecy performs some minor optimizations to the code
generated by the apply() method.
For details on our optimization functions, see Optimization functions.
Source/Target Gems
Source/Target Gems are Gems that you use to read/write your Datasets into DataFrames. There are certain differences between how you define a Source/Target Gem and a Transformation Gem. For example, a Source/Target Gem will have two dialog and two apply functions each for Source and Target respectively. Let's look at them with an example.
- Python
- Scala
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql.types import StructType
from prophecy.cb.server.base.ComponentBuilderBase import ComponentCode, Diagnostic, SeverityLevelEnum
from prophecy.cb.server.base.DatasetBuilderBase import DatasetSpec, DatasetProperties, Component
from prophecy.cb.ui.uispec import *
class ParquetFormat(DatasetSpec):
name: str = "parquet"
datasetType: str = "File"
def optimizeCode(self) -> bool:
return True
@dataclass(frozen=True)
class ParquetProperties(DatasetProperties):
schema: Optional[StructType] = None
description: Optional[str] = ""
useSchema: Optional[bool] = False
path: str = ""
mergeSchema: Optional[bool] = None
datetimeRebaseMode: Optional[str] = None
int96RebaseMode: Optional[str] = None
compression: Optional[str] = None
partitionColumns: Optional[List[str]] = None
writeMode: Optional[str] = None
pathGlobFilter: Optional[str] = None
modifiedBefore: Optional[str] = None
modifiedAfter: Optional[str] = None
recursiveFileLookup: Optional[bool] = None
def sourceDialog(self) -> DatasetDialog:
return DatasetDialog("parquet") \
.addSection("LOCATION", TargetLocation("path")) \
.addSection(
"PROPERTIES",
ColumnsLayout(gap=("1rem"), height=("100%"))
.addColumn(
ScrollBox().addElement(
StackLayout(height=("100%"))
.addElement(
StackItem(grow=(1)).addElement(
FieldPicker(height=("100%"))
.addField(
TextArea("Description", 2, placeholder="Dataset description..."),
"description",
True
)
.addField(Checkbox("Use user-defined schema"), "useSchema", True)
.addField(Checkbox("Merge schema"), "mergeSchema")
.addField(
SelectBox("Datetime Rebase Mode")
.addOption("EXCEPTION", "EXCEPTION")
.addOption("CORRECTED", "CORRECTED")
.addOption("LEGACY", "LEGACY"),
"datetimeRebaseMode"
)
.addField(
SelectBox("Int96 Rebase Mode")
.addOption("EXCEPTION", "EXCEPTION")
.addOption("CORRECTED", "CORRECTED")
.addOption("LEGACY", "LEGACY"),
"int96RebaseMode"
)
.addField(Checkbox("Recursive File Lookup"), "recursiveFileLookup")
.addField(TextBox("Path Global Filter").bindPlaceholder(""), "pathGlobFilter")
.addField(TextBox("Modified Before").bindPlaceholder(""), "modifiedBefore")
.addField(TextBox("Modified After").bindPlaceholder(""), "modifiedAfter")
)
)
),
"auto"
)
.addColumn(SchemaTable("").bindProperty("schema"), "5fr")
) \
.addSection(
"PREVIEW",
PreviewTable("").bindProperty("schema")
)
def targetDialog(self) -> DatasetDialog:
return DatasetDialog("parquet") \
.addSection("LOCATION", TargetLocation("path")) \
.addSection(
"PROPERTIES",
ColumnsLayout(gap=("1rem"), height=("100%"))
.addColumn(
ScrollBox().addElement(
StackLayout(height=("100%")).addElement(
StackItem(grow=(1)).addElement(
FieldPicker(height=("100%"))
.addField(
TextArea("Description", 2, placeholder="Dataset description..."),
"description",
True
)
.addField(
SelectBox("Write Mode")
.addOption("error", "error")
.addOption("overwrite", "overwrite")
.addOption("append", "append")
.addOption("ignore", "ignore"),
"writeMode"
)
.addField(
SchemaColumnsDropdown("Partition Columns")
.withMultipleSelection()
.bindSchema("schema")
.showErrorsFor("partitionColumns"),
"partitionColumns"
)
.addField(
SelectBox("Compression Codec")
.addOption("none", "none")
.addOption("uncompressed", "uncompressed")
.addOption("gzip", "gzip")
.addOption("lz4", "lz4")
.addOption("snappy", "snappy")
.addOption("lzo", "lzo")
.addOption("brotli", "brotli")
.addOption("zstd", "zstd"),
"compression"
)
)
)
),
"auto"
)
.addColumn(SchemaTable("").isReadOnly().withoutInferSchema().bindProperty("schema"), "5fr")
)
def validate(self, component: Component) -> list:
diagnostics = super(ParquetFormat, self).validate(component)
if len(component.properties.path) == 0:
diagnostics.append(
Diagnostic("properties.path", "path variable cannot be empty [Location]", SeverityLevelEnum.Error))
return diagnostics
def onChange(self, oldState: Component, newState: Component) -> Component:
return newState
class ParquetFormatCode(ComponentCode):
def __init__(self, props):
self.props: ParquetFormat.ParquetProperties = props
def sourceApply(self, spark: SparkSession) -> DataFrame:
reader = spark.read.format("parquet")
if self.props.mergeSchema is not None:
reader = reader.option("mergeSchema", self.props.mergeSchema)
if self.props.datetimeRebaseMode is not None:
reader = reader.option("datetimeRebaseMode", self.props.datetimeRebaseMode)
if self.props.int96RebaseMode is not None:
reader = reader.option("int96RebaseMode", self.props.int96RebaseMode)
if self.props.modifiedBefore is not None:
reader = reader.option("modifiedBefore", self.props.modifiedBefore)
if self.props.modifiedAfter is not None:
reader = reader.option("modifiedAfter", self.props.modifiedAfter)
if self.props.recursiveFileLookup is not None:
reader = reader.option("recursiveFileLookup", self.props.recursiveFileLookup)
if self.props.pathGlobFilter is not None:
reader = reader.option("pathGlobFilter", self.props.pathGlobFilter)
if self.props.schema is not None and self.props.useSchema:
reader = reader.schema(self.props.schema)
return reader.load(self.props.path)
def targetApply(self, spark: SparkSession, in0: DataFrame):
writer = in0.write.format("parquet")
if self.props.compression is not None:
writer = writer.option("compression", self.props.compression)
if self.props.writeMode is not None:
writer = writer.mode(self.props.writeMode)
if self.props.partitionColumns is not None and len(self.props.partitionColumns) > 0:
writer = writer.partitionBy(*self.props.partitionColumns)
writer.save(self.props.path)
package io.prophecy.core.instructions.all.datasets
import io.prophecy.core.instructions.all._
import io.prophecy.core.instructions.spec._
import io.prophecy.core.program.WorkflowContext
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types.StructType
import io.prophecy.libs._
object ParquetFormat extends DatasetSpec {
val name: String = "parquet"
val datasetType: String = "File"
type PropertiesType = ParquetProperties
case class ParquetProperties(
@Property("Schema")
schema: Option[StructType] = None,
@Property("Description")
description: Option[String] = Some(""),
@Property("useSchema")
useSchema: Option[Boolean] = Some(false),
@Property("Path")
path: String = "",
@Property(
"",
"(default is the value specified in spark.sql.parquet.mergeSchema(false)): sets whether we should merge schemas collected from all Parquet part-files. This will override spark.sql.parquet.mergeSchema."
)
mergeSchema: Option[Boolean] = None,
@Property(
"datetimeRebaseMode",
"The datetimeRebaseMode option allows to specify the rebasing mode for the values of the DATE, TIMESTAMP_MILLIS, TIMESTAMP_MICROS logical types from the Julian to Proleptic Gregorian calendar."
)
datetimeRebaseMode: Option[String] = None,
@Property(
"int96RebaseMode",
"The int96RebaseMode option allows to specify the rebasing mode for INT96 timestamps from the Julian to Proleptic Gregorian calendar."
)
int96RebaseMode: Option[String] = None,
@Property("compression", "(default: none) compression codec to use when saving to file.")
compression: Option[String] = None,
@Property("partitionColumns", "Partitioning column.")
partitionColumns: Option[List[String]] = None,
@Property("Write Mode", """(default: "error") Specifies the behavior when data or table already exists.""")
writeMode: Option[String] = None,
@Property(
"",
"an optional glob pattern to only include files with paths matching the pattern. The syntax follows org.apache.hadoop.fs.GlobFilter. It does not change the behavior of partition discovery."
)
pathGlobFilter: Option[String] = None,
@Property(
"",
"(batch only): an optional timestamp to only include files with modification times occurring before the specified Time. The provided timestamp must be in the following form: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)"
)
modifiedBefore: Option[String] = None,
@Property(
"",
"(batch only): an optional timestamp to only include files with modification times occurring after the specified Time. The provided timestamp must be in the following form: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)"
)
modifiedAfter: Option[String] = None,
@Property("", "recursively scan a directory for files. Using this option disables partition discovery")
recursiveFileLookup: Option[Boolean] = None
) extends DatasetProperties
def sourceDialog: DatasetDialog = DatasetDialog("parquet")
.addSection("LOCATION", TargetLocation("path"))
.addSection(
"PROPERTIES",
ColumnsLayout(gap = Some("1rem"), height = Some("100%"))
.addColumn(
ScrollBox().addElement(
StackLayout(height = Some("100%"))
.addElement(
StackItem(grow = Some(1)).addElement(
FieldPicker(height = Some("100%"))
.addField(
TextArea("Description", 2, placeholder = "Dataset description..."),
"description",
true
)
.addField(Checkbox("Use user-defined schema"), "useSchema", true)
.addField(Checkbox("Merge schema"), "mergeSchema")
.addField(
SelectBox("Datetime Rebase Mode")
.addOption("EXCEPTION", "EXCEPTION")
.addOption("CORRECTED", "CORRECTED")
.addOption("LEGACY", "LEGACY"),
"datetimeRebaseMode"
)
.addField(
SelectBox("Int96 Rebase Mode")
.addOption("EXCEPTION", "EXCEPTION")
.addOption("CORRECTED", "CORRECTED")
.addOption("LEGACY", "LEGACY"),
"int96RebaseMode"
)
.addField(Checkbox("Recursive File Lookup"), "recursiveFileLookup")
.addField(TextBox("Path Global Filter").bindPlaceholder(""), "pathGlobFilter")
.addField(TextBox("Modified Before").bindPlaceholder(""), "modifiedBefore")
.addField(TextBox("Modified After").bindPlaceholder(""), "modifiedAfter")
)
)
),
"auto"
)
.addColumn(SchemaTable("").bindProperty("schema"), "5fr")
)
.addSection(
"PREVIEW",
PreviewTable("").bindProperty("schema")
)
def targetDialog: DatasetDialog = DatasetDialog("parquet")
.addSection("LOCATION", TargetLocation("path"))
.addSection(
"PROPERTIES",
ColumnsLayout(gap = Some("1rem"), height = Some("100%"))
.addColumn(
ScrollBox().addElement(
StackLayout(height = Some("100%")).addElement(
StackItem(grow = Some(1)).addElement(
FieldPicker(height = Some("100%"))
.addField(
TextArea("Description", 2, placeholder = "Dataset description..."),
"description",
true
)
.addField(
SelectBox("Write Mode")
.addOption("error", "error")
.addOption("overwrite", "overwrite")
.addOption("append", "append")
.addOption("ignore", "ignore"),
"writeMode"
)
.addField(
SchemaColumnsDropdown("Partition Columns")
.withMultipleSelection()
.bindSchema("schema")
.showErrorsFor("partitionColumns"),
"partitionColumns"
)
.addField(
SelectBox("Compression Codec")
.addOption("none", "none")
.addOption("uncompressed", "uncompressed")
.addOption("gzip", "gzip")
.addOption("lz4", "lz4")
.addOption("snappy", "snappy")
.addOption("lzo", "lzo")
.addOption("brotli", "brotli")
.addOption("zstd", "zstd"),
"compression"
)
)
)
),
"auto"
)
.addColumn(SchemaTable("").isReadOnly().withoutInferSchema().bindProperty("schema"), "5fr")
)
override def validate(component: Component)(implicit context: WorkflowContext): List[Diagnostic] = {
import scala.collection.mutable.ListBuffer
val diagnostics = ListBuffer[Diagnostic]()
diagnostics ++= super.validate(component)
if (component.properties.path.isEmpty) {
diagnostics += Diagnostic("properties.path", "path variable cannot be empty [Location]", SeverityLevel.Error)
}
if (component.properties.schema.isEmpty) {
// diagnostics += Diagnostic("properties.schema", "Schema cannot be empty [Properties]", SeverityLevel.Error)
}
diagnostics.toList
}
def onChange(oldState: Component, newState: Component)(implicit context: WorkflowContext): Component = newState
class ParquetFormatCode(props: ParquetProperties) extends ComponentCode {
def sourceApply(spark: SparkSession): DataFrame = {
var reader = spark.read
.format("parquet")
.option("mergeSchema", props.mergeSchema)
.option("datetimeRebaseMode", props.datetimeRebaseMode)
.option("int96RebaseMode", props.int96RebaseMode)
.option("modifiedBefore", props.modifiedBefore)
.option("modifiedAfter", props.modifiedAfter)
.option("recursiveFileLookup", props.recursiveFileLookup)
.option("pathGlobFilter", props.pathGlobFilter)
if (props.useSchema.isDefined && props.useSchema.get)
props.schema.foreach(schema ⇒ reader = reader.schema(schema))
reader.load(props.path)
}
def targetApply(spark: SparkSession, in: DataFrame): Unit = {
var writer = in.write
.format("parquet")
.option("compression", props.compression)
props.writeMode.foreach { mode ⇒
writer = writer.mode(mode)
}
props.partitionColumns.foreach(pcols ⇒
writer = pcols match {
case Nil ⇒ writer
case _ ⇒ writer.partitionBy(pcols: _*)
}
)
writer.save(props.path)
}
}
}
Here you can see the differences between a Transform Gem and a DataSource Gem.
- The Source/Target Gem extends
DatasetSpec. - It has two Dialog functions:
sourceDialogandtargetDialog. They return both aDatasetDialogobject, whereas for any Transform Gem, the dialog function returns aDialogobject. - The
ComponentCodeclass has two apply functions:sourceApplyandtargetApplyfor Source and Target modes respectively.
There is no change in onChange and validate functions.
What's next
To learn more about the Gem builder and additional optimization options, see the following page:
📄️ Optimization functions
Optimization functions