Architecture
Prophecy operates as a distributed system built on microservices architecture, orchestrated by Kubernetes across multiple cloud platforms. The platform consists of several core components that work together to provide data transformation, orchestration, and management capabilities.
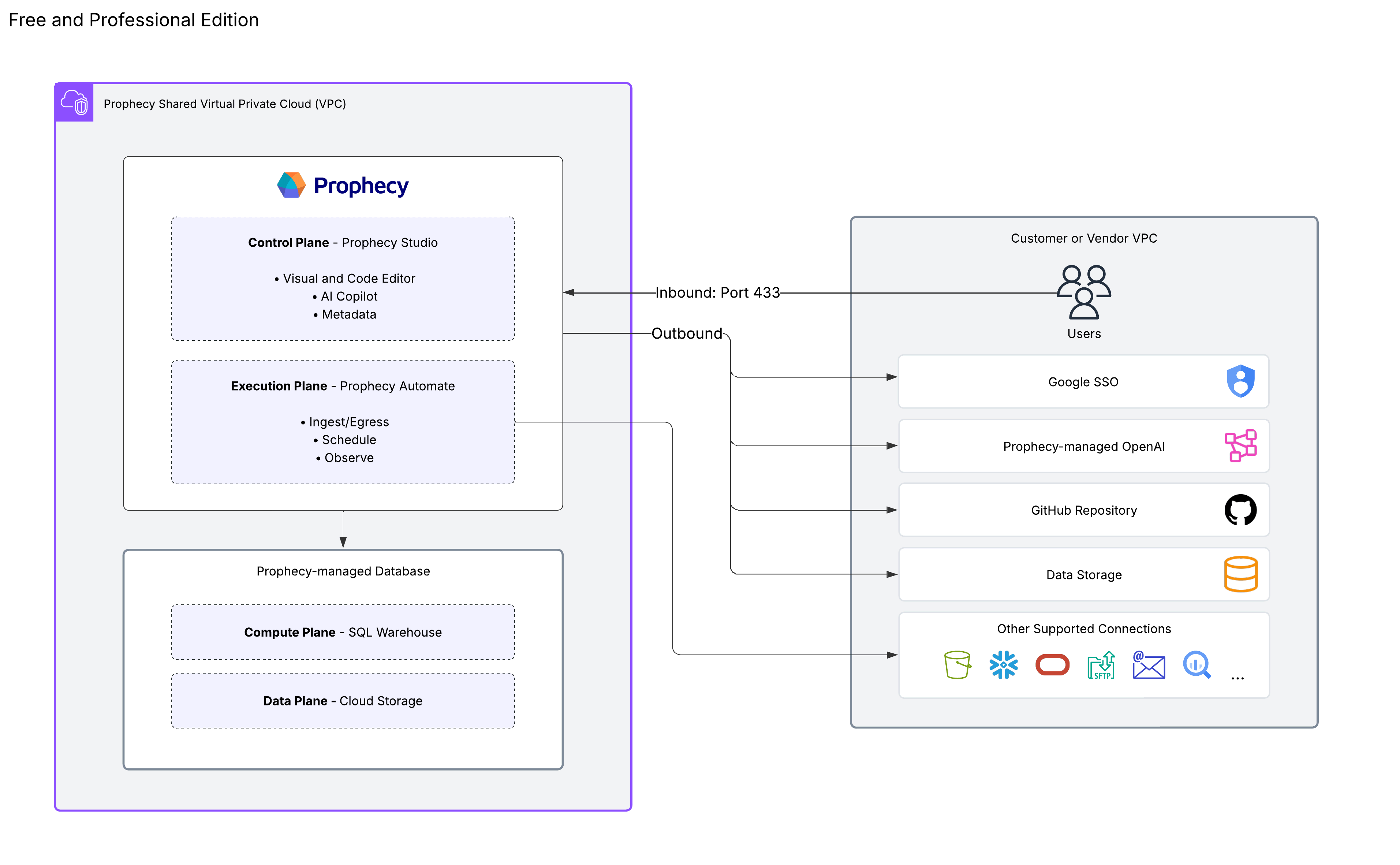
Free and Professional Edition
The Free and Professional Editions provide a complete data platform with managed components.
| Component | Description |
|---|---|
| Prophecy Studio | The control plane that provides the user interface for developing visual data pipelines and managing projects. |
| Prophecy Automate | The native runtime designed for data ingestion, egress, and built-in scheduling capabilities. |
| Prophecy In Memory | The Prophecy-managed SQL warehouse that processes data transformations. |
| Data storage | Data outside of the execution environment that will flow in and out of the pipeline. |
| AI endpoint | Prophecy-managed LLM subscription and endpoint. |
| Version control | Git integration supporting both Prophecy-managed and external Git repositories. |
| Deployment model | SaaS only. Learn more in Deployment models. |
Express Edition
The Express Edition provides enterprise-grade features scoped to leverage your existing SQL warehouse infrastructure.
| Component | Description |
|---|---|
| Prophecy Studio | The control plane that provides the user interface for developing visual data pipelines and managing projects. |
| Prophecy Automate | The native runtime designed for data ingestion, egress, and built-in scheduling capabilities. |
| External SQL Warehouse | Your own Databricks SQL engine that executes data transformations. |
| Data storage | Data outside of the execution environment that will flow in and out of the pipeline. |
| AI endpoint | Customer-managed LLM subscription and endpoint. |
| Version control | Git integration supporting both Prophecy-managed and external Git repositories. |
| Deployment model | Dedicated SaaS only. Learn more in Deployment models. |
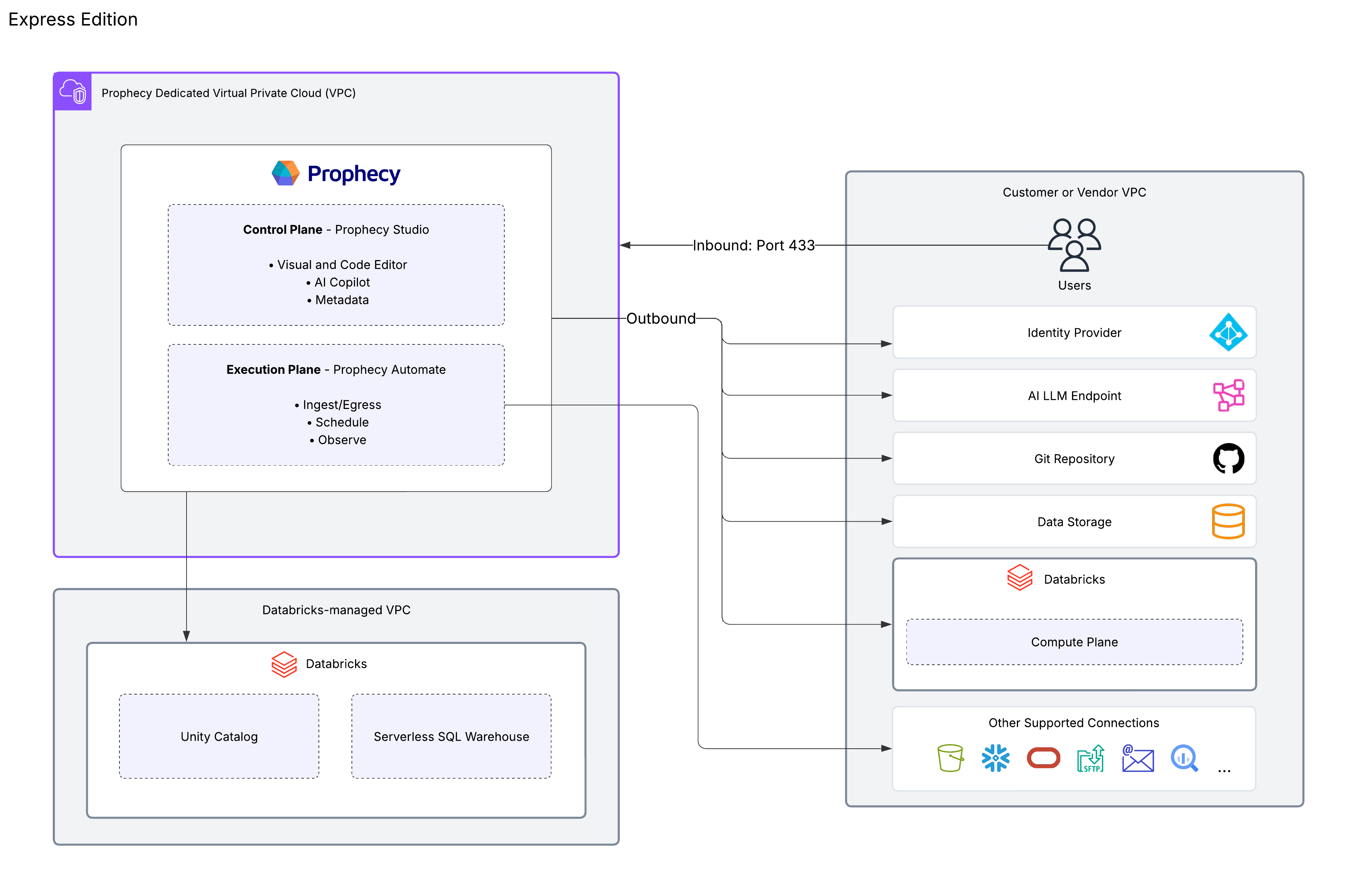
This diagram shows the architecture for the Express Edition. Users on the Enterprise Edition can also leverage this architecture. However, Enterprise users can also connect to additional SQL warehouses, like BigQuery.
Enterprise Edition
The Enterprise edition offers maximum flexibility with multiple execution engine options and deployment models.
| Component | Description |
|---|---|
| Prophecy Studio | The control plane that provides the user interface for developing visual data pipelines and managing projects across various data platforms. |
| Execution engine | Flexible compute options including Spark clusters or external SQL warehouses combined with Prophecy Automate. Prophecy executes data transformations on your chosen execution environment. Fabrics enable users to execute pipelines on these platforms. Prophecy does not persist your data. |
| Data storage | Data outside of the execution environment that will flow in and out of the pipeline. |
| AI | Customer-managed LLM subscription and endpoint. |
| Version control | Git integration supporting both Prophecy-managed and external Git repositories. |
| Deployment model | Dedicated SaaS preferred and SaaS available. Learn more in Deployment models. |
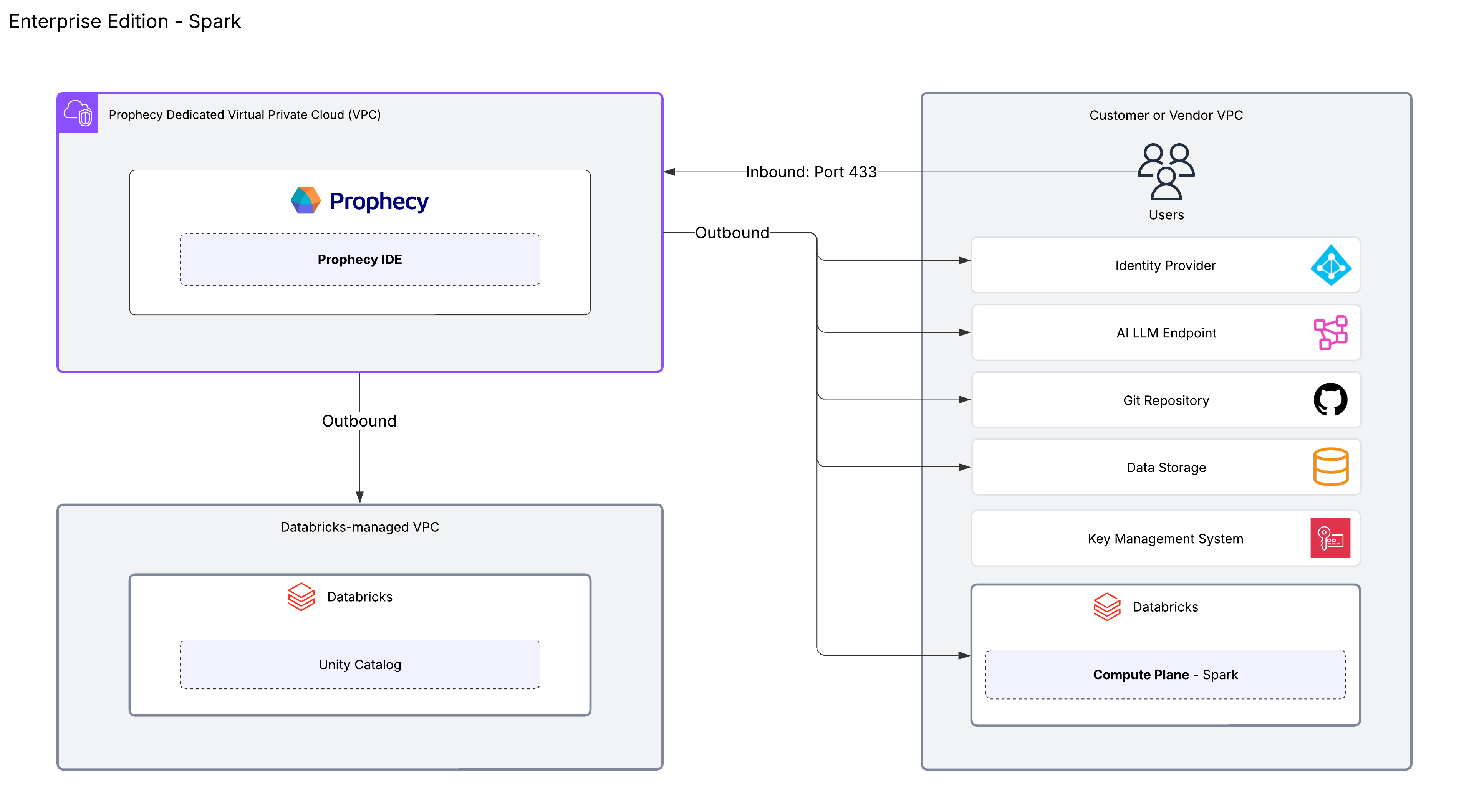
The Enterprise Edition supports both SQL-based and Spark-based architectures. The diagram above shows the architecture for a deployment using Spark.
Prophecy can accommodate a wide variety of architectures beyond this diagram. For example:
- The diagram demonstrates Databricks as the execution engine. You can connect to other platforms like Amazon EMR and Google Cloud Dataproc, or use another Spark engine through Apache Livy.
- The diagram displays a connection to an external Git repository. You can connect to a variety of providers such as GitHub, Bitbucket, GitLab, and more.
What is Prophecy Automate?
Prophecy Automate is the native runtime available across all Prophecy editions. This runtime provides the following core capabilities:
-
Ingress/Egress: Supports reading from and writing to databases (Snowflake, Oracle, etc.) and other data providers (SharePoint, Tableau, etc.).
-
Orchestration: Coordinates pipeline logic beyond what's possible in dbt core. Orchestration includes pipeline scheduling with time-based and trigger-based execution, orchestration APIs for programmatic control, and dynamic operations like the DynamicInput gem (which runs SQL queries that update automatically based on incoming data) and the Directory gem (which lists files and folders in a specified location).
-
Observe: Integrates monitoring and observability features that allow you to view preserve pipeline run history, track project deployments, and view active pipeline schedules.
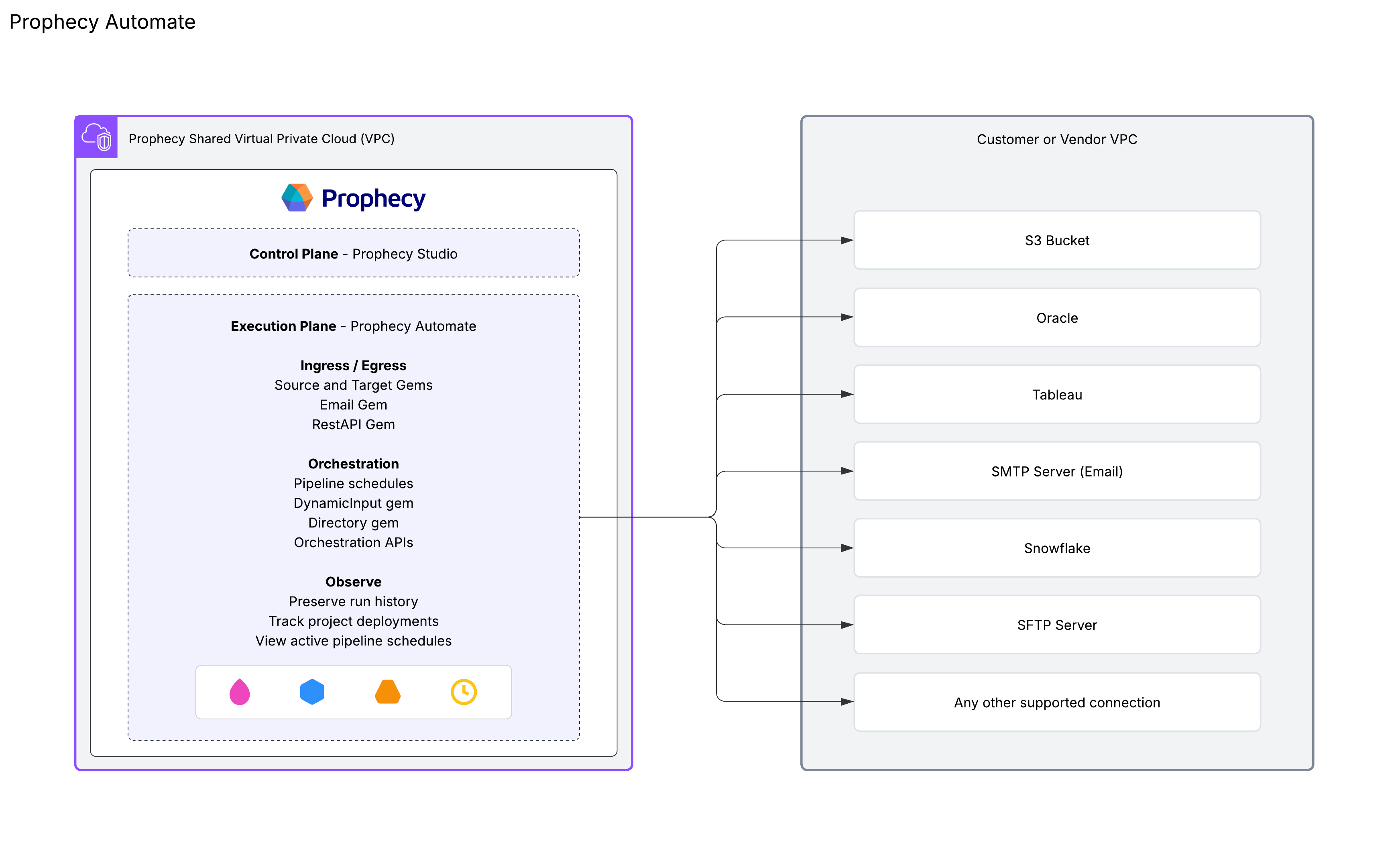
Prophecy Automate is only accessible via Prophecy fabrics for SQL projects and does not integrate with Spark-based projects.