Models
Models are based on SQL-native code and use the dbt Core™️ build system. Models define a single dataset, typically a table or view, and are useful for transforming data directly in a data warehouse or for existing dbt users. They are best suited for data analytics and transformation needs.
You can build models from a visual or code interface. When using the visual interface, model components are automatically compiled into SQL select statements that you can reuse and customize.
Prophecy’s visual interface supports SQL models only. If you’d like to define Python models you can still use them within the code interface.
Data modeling
Data modeling refers to shaping your data from its raw state to its transformed final state. In Prophecy and dbt, data models are SQL statements that build a single table or view and enable better management. Data models incorporate step-by-step logic, compatible with Prophecy gems. Each model is stored as a SQL file on Git as open-source code. Models can also be reused through Prophecy packages.
Model development
In the Project Editor of a SQL project, Prophecy displays models using a lineage view, a visual view, and a code view. As you develop your models, you can commit and release your changes via Git.
- Lineage view. When you open a SQL project, you first see the lineage view. The lineage provides a high-level view of the project's models with dependencies displayed from left to right.
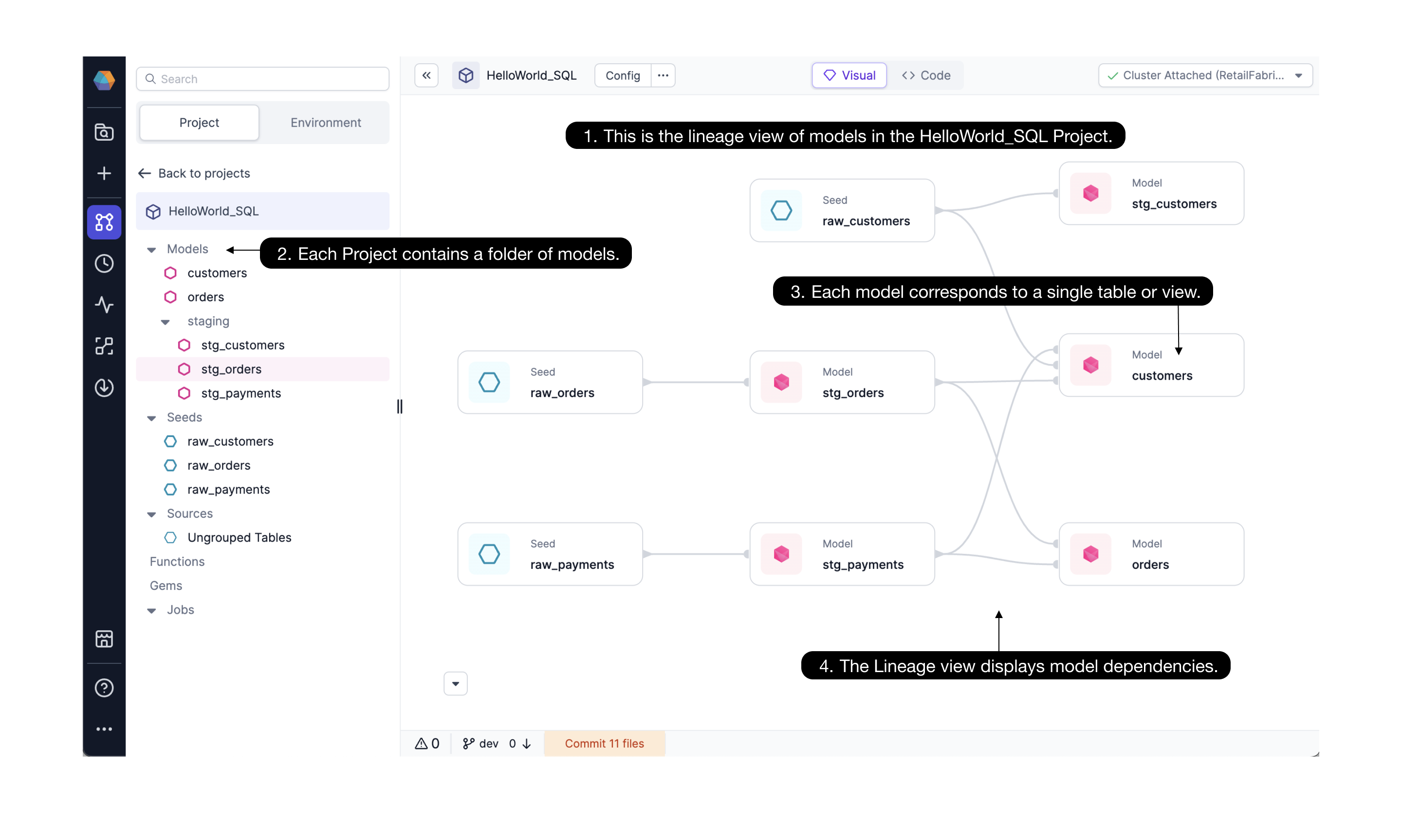
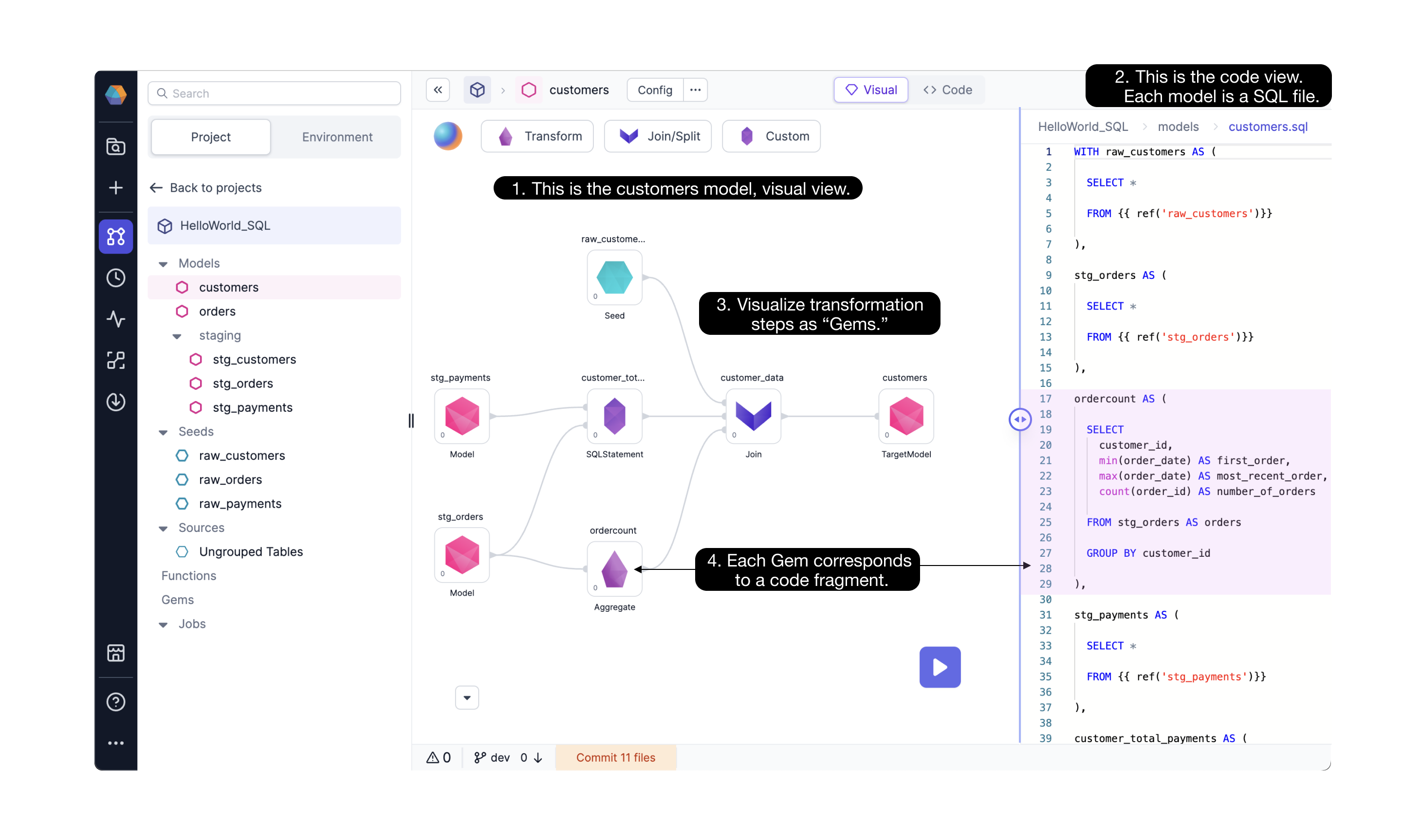
Visual view. If you open a specific model, you are taken to the model visual canvas. The visual canvas shows each step needed to move from the referenced tables/seeds/models to the final model. Gems drive data transformations in Prophecy.
Code view. Any changes that you make in the visual view are automatically compiled into code (and vice-versa).
Models vs pipelines
If you’re already familiar with Prophecy pipelines, models are very similar. The major difference is that each pipeline can create an arbitrary number of outputs, whereas a model only defines one output. Where pipelines can exist only within Spark-based projects, models can exist within SQL-based ones.
What's next
Visit the SQL documentation to learn more. You can also get started with SQL on Databricks or Snowflake.