SQL with Snowflake
If you store your data in Snowflake, you can use Prophecy to build SQL models and carry out data transformations. Use this tutorial to understand how to connect Snowflake and Prophecy, develop visual models, review optimized and open-source SQL code, and deploy projects.
Along the way, our Data Copilot will help! Prophecy has built our Data Copilot for SQL on top of dbt Core™️ , an open-source tool for managing SQL-based data transformations.
Requirements
For this tutorial, you will need:
- A Prophecy account.tip
If you do not already have access to Prophecy, you can sign up and start a 21 day free trial.
- A Snowflake account.
- A GitHub account.
Connect to Snowflake
Let's start by connecting Prophecy and Snowflake.
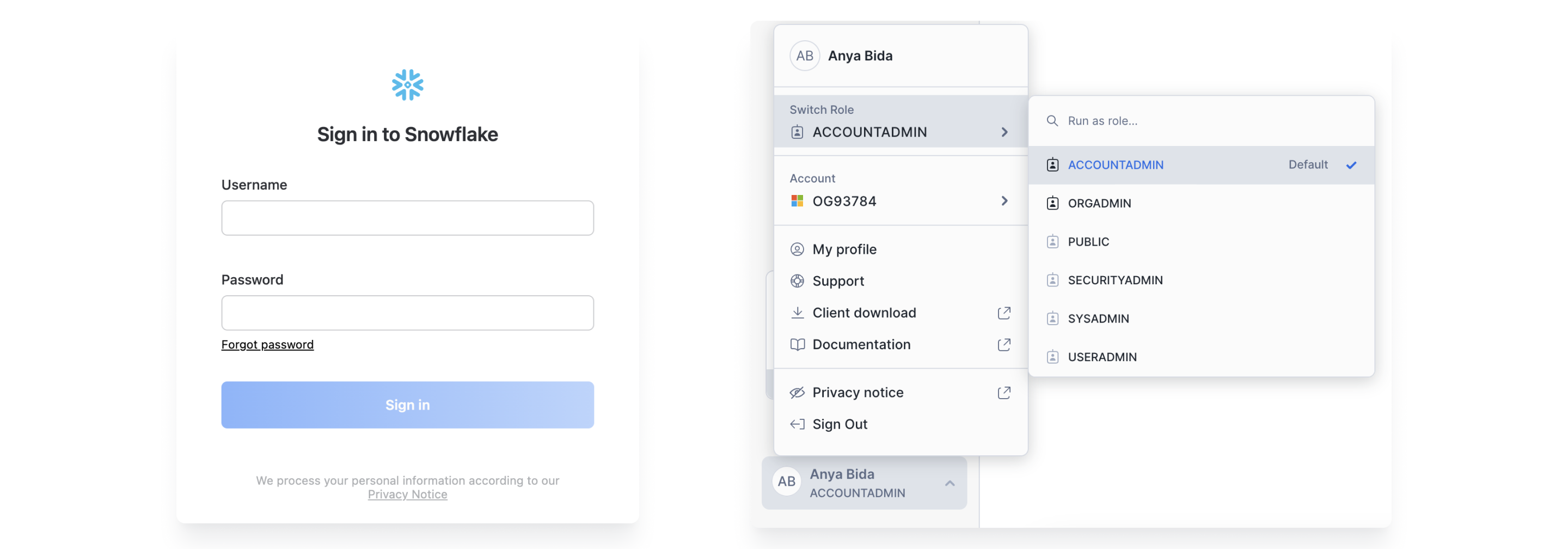
Get Snowflake Account URL and credentials
You'll first have to retrieve the following information from Snowflake to pass to Prophecy.
- Open Snowflake.
- Write down your SnowflakeURL. It should look like
https://<org-account>.snowflakecomputing.com. - Note your user's Role in Snowflake.
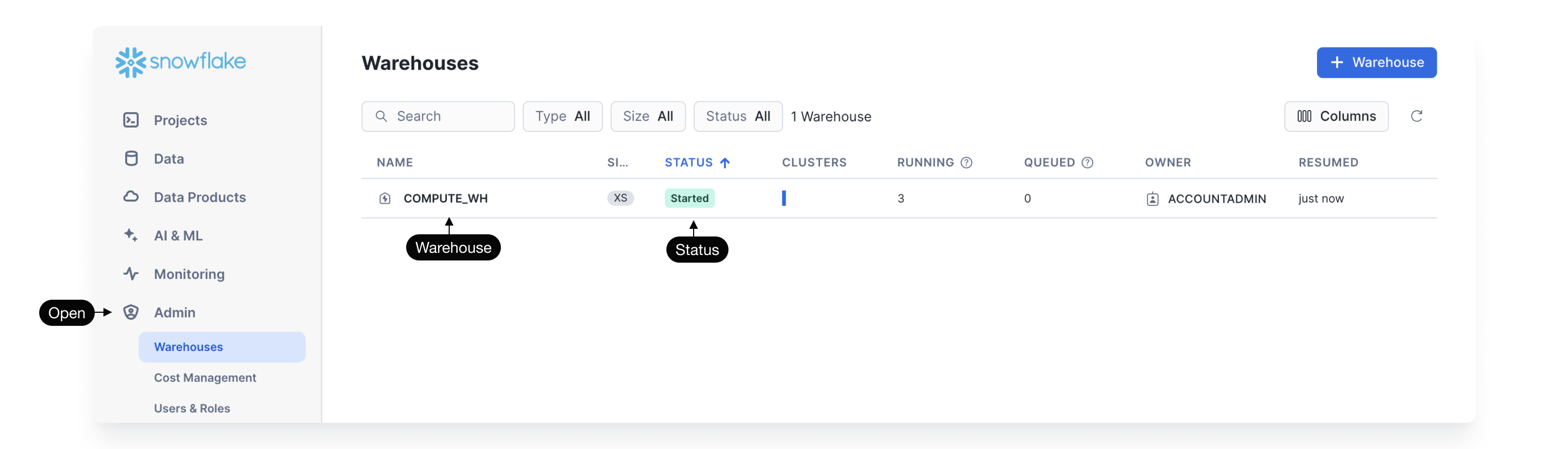
- Identify which warehouse you want to connect. Make sure the warehouse is started.
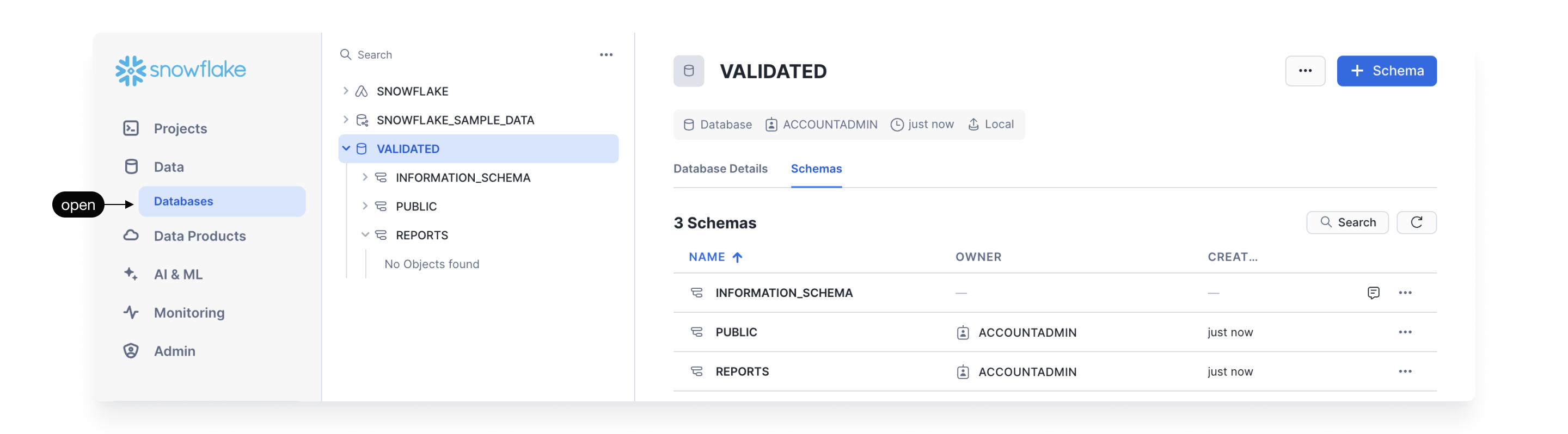
- Identify a database and schema that you want Prophecy to access.
Set up a fabric in Prophecy
A fabric in Prophecy is an execution environment. In this case, you already know you want to use Snowflake for your computation, so we'll make a Snowflake fabric!
Typically you should setup at least one fabric each for development and production environments. Use the development fabric for quick development with sample data, and use the production environment for daily runs with your production Snowflake warehouse data. Many Snowflake users will setup daily scheduled runs using Airflow as detailed below.
Let's use the information we identified previously to create the fabric.
- Click - to add a new entity.
- Create - a new fabric.
- Fabric Name - Specify a name, like devSnowflake, for your fabric. “dev” or “prod” are helpful descriptors for this environment setup. Also specify a description (optional)
- Team - Select a team to own this fabric. Click the dropdown to list the teams your user is a member. If you don’t see the desired team, ask a Prophecy Administrator to add you to a team.
- Continue - to the Provider step.
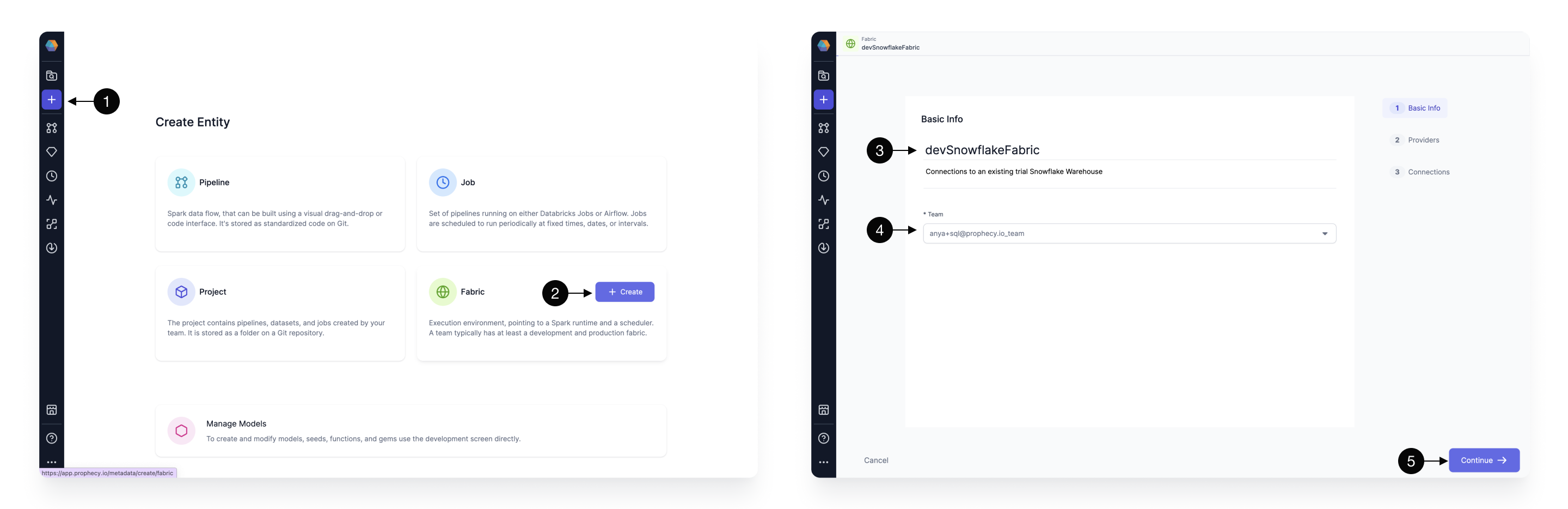
- Provider Type - Select SQL as the Provider type.
- Provider - Click the dropdown menu for the list of supported Provider types. Select Snowflake.
- URL - Add the Snowflake Account URL, which looks like this:
https://<org>-<account>.snowflakecomputing.com - Username - Add the username that Prophecy will use to connect to the Snowflake Warehouse.
- Password - Add the password that Prophecy will use to connect to the Snowflake Warehouse. These username/password credentials are encrypted for secure storage. Also, each Prophecy user will provide their own username/password credential upon login. Be sure these credentials are scoped appropriately; Prophecy respects the authorization granted to this Snowflake user.
- Role - Add the Snowflake role that Prophecy will use to read data and execute queries on the Snowflake Warehouse. The role must be already granted to the username/password provided above and should be scoped according to the permission set desired for Prophecy.
- Warehouse - Specify the Snowflake warehouse for default writes for this execution environment.
- Database - Specify the desired Snowflake database for default writes for this execution environment.
- Schema - Specify the desired Snowflake schema for default writes for this execution environment.
- Continue - to complete the fabric creation.
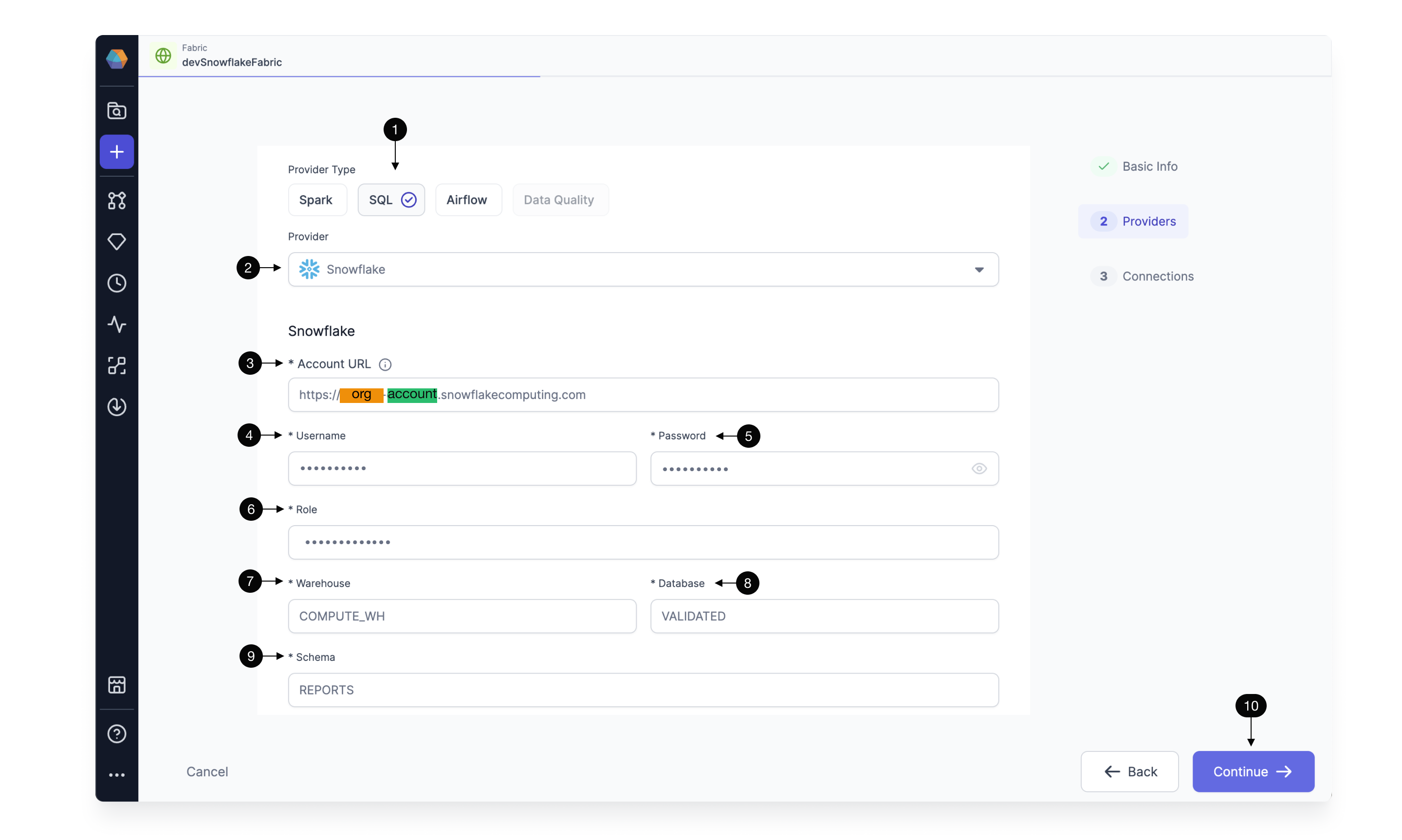
Each user can read tables from any database and schema for which they have access. The default write database and schema is set here in the fabric.
Create a new project
After you create your first SQL fabric, you'll see a project in Prophecy called HelloWorld_SQL. If you just want to play around with Prophecy, you can start there. However, for the purpose of this tutorial, let's build a new project from scratch.
To create a new project:
- Click the (1) Create Entity button on the sidebar and choose (2) Create on the project tile. The project creation screen will open.
- Fill in the project’s (3) Name, (4) Description (optional), and set the (5) Project Type to SQL.
- After that, select the (6) Team which is going to own the newly selected project. By default, you can leave the selected team to be your personal one.
- Finally, we choose the same (7) Provider as we selected in the previous step (Snowflake). Once all the details are filled out correctly, you can proceed to the next step by clicking (8) Continue.
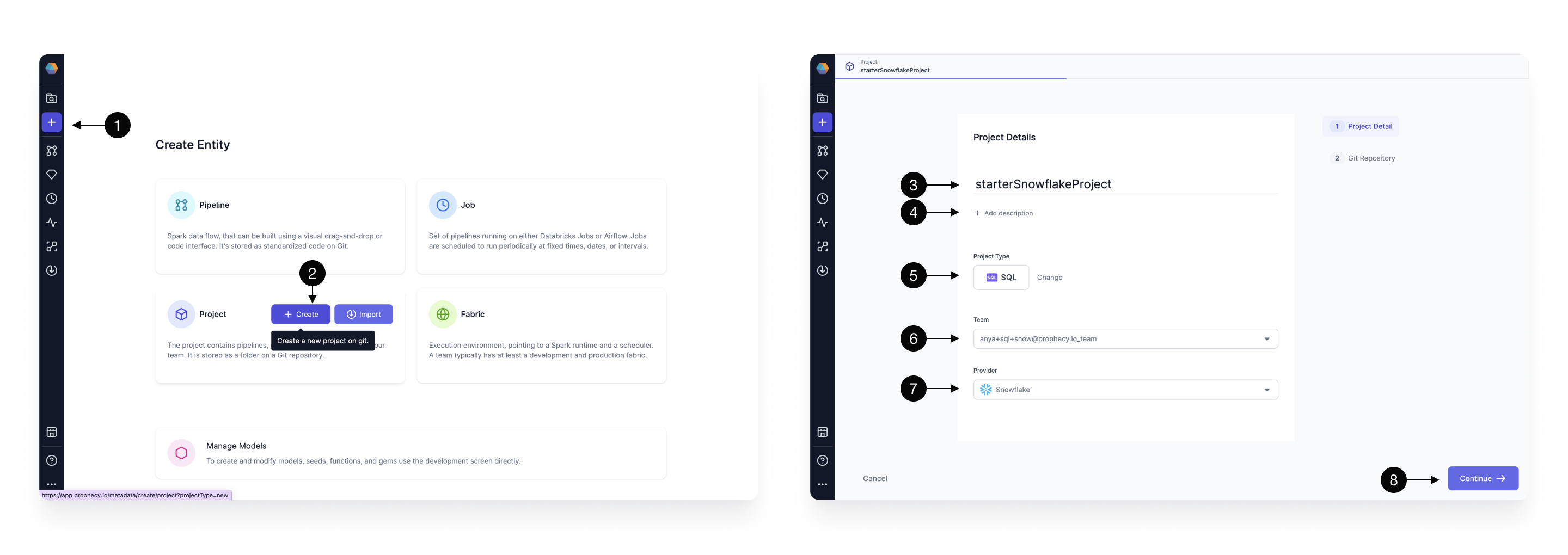
Once the basic project information is filled out, it’s time to configure the Git repository on which we’re going to store our project.
Connect to external Git repository
You'll see two options to connect to Git. (1) Prophecy Managed Git Credentials are not supported for this use case. You will need a GitHub account for this getting started guide. If you don't have one, create one by following these instructions. Select (2) Connect to External Git to connect to your external Git account.
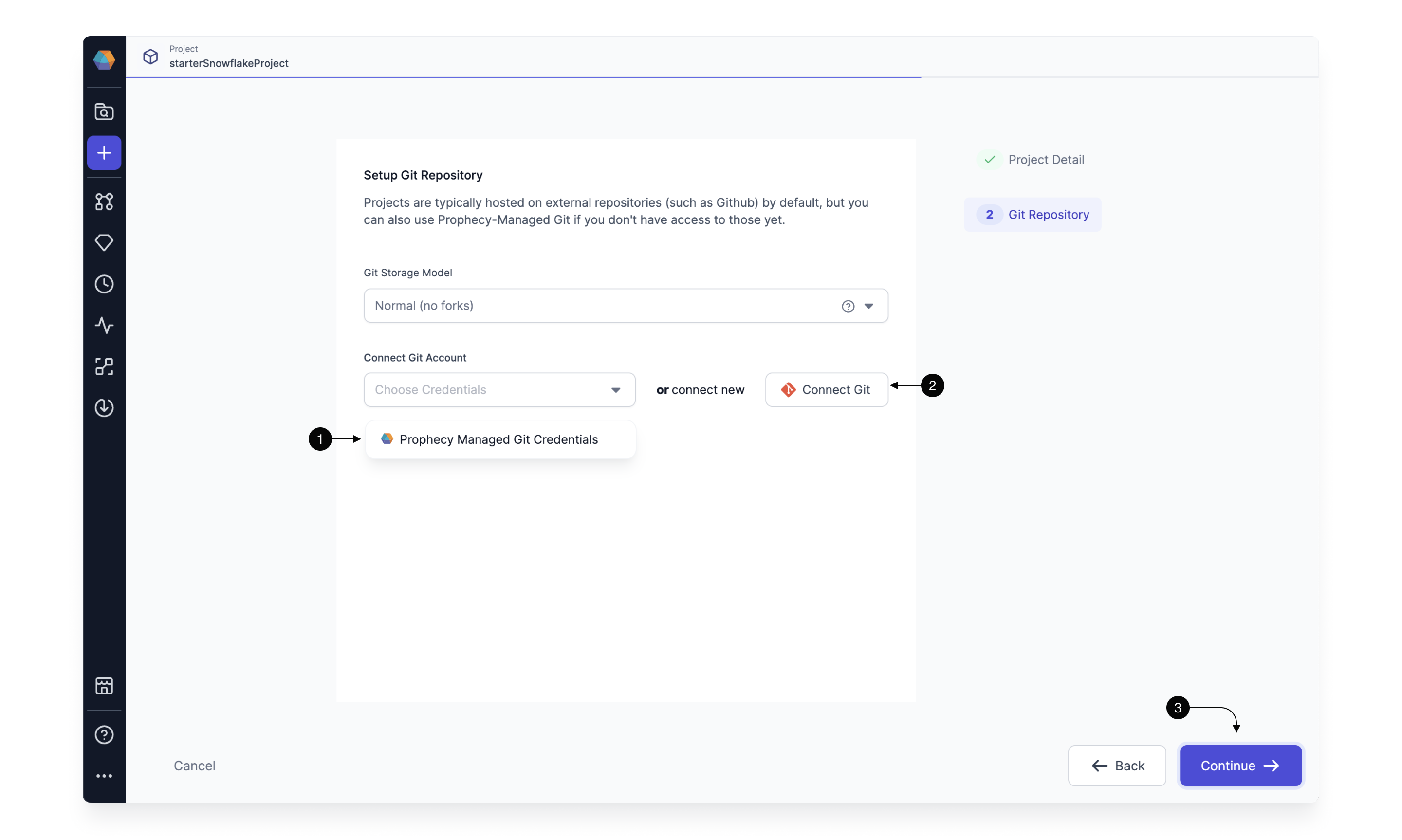
Now, you will use Prophecy's OAuth GitHub integration for authentication.
- Git Provider - Choose GitHub as the Git provider for this project.
- Alias - Each Git connection in Prophecy starts with an Alias that’s going to be used to allow you to identify the right Git account. In most cases, this can be left as default.
- Login with GitHub - redirects you to a GitHub login page (if you're not yet logged in).
- Sign in - or create a new GitHub account.
- Authorize - Authorize SimpleDataLabs (legal organization name of Prophecy.io). Here you are asked to approve Prophecy as a valid organization.
- Connect - to save the Git connection.
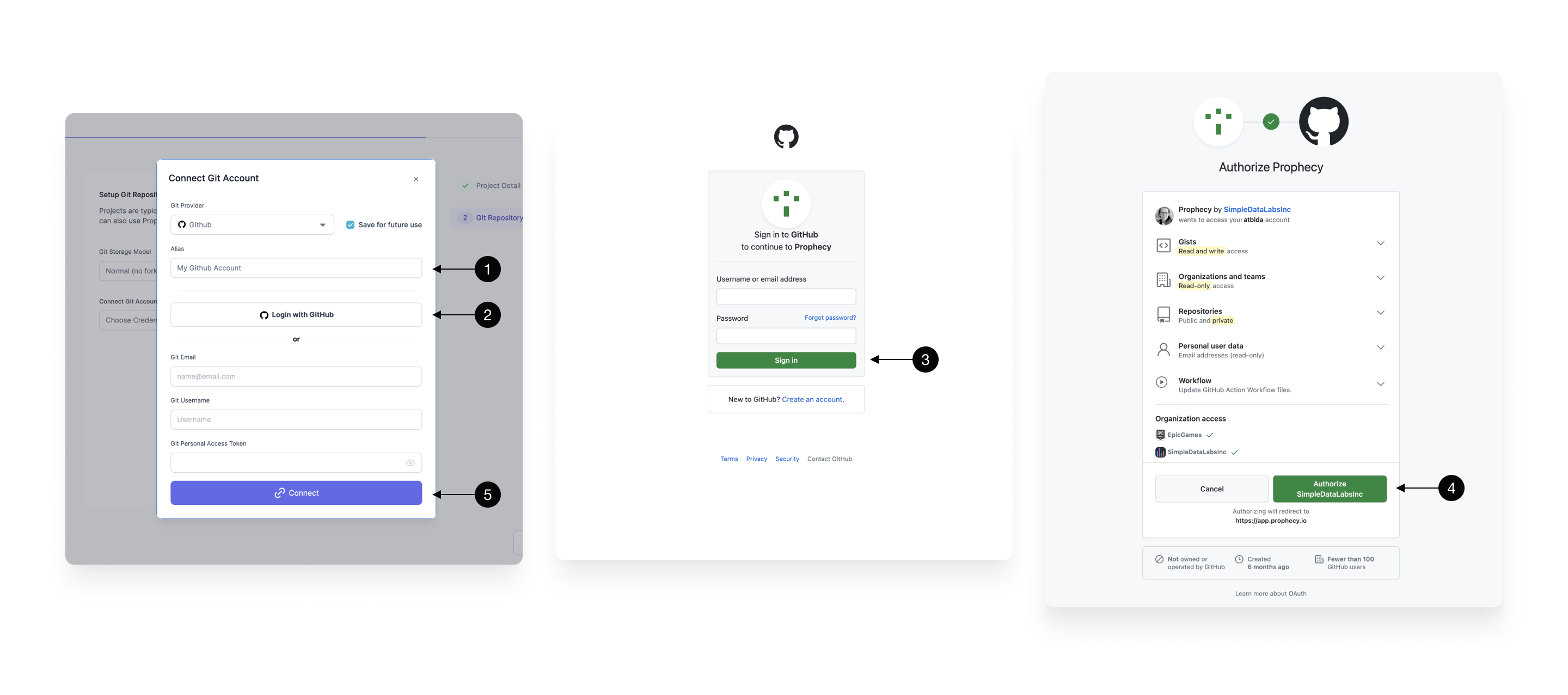
Note that Prophecy will not store any information beyond basic user details (like email) and repository content (only queried at your explicit permission for each repository).
If you’d like to connect Prophecy to one of your GitHub organizations, make sure those are approved in the Organization access section.
Once your GitHub account is setup, select a repository where Prophecy will store all the code for this project. Choose a (1) Repository from the dropdown available. If you’d like to create a new repository from scratch follow this guide.
(2) Default Branch field should populate automatically based on the repository’s default main branch - you can change if necessary. Default branch is a central point where all the code changes are merged, serving as the primary, up-to-date source for a project.
Sometimes, you might want to load a project that’s within a specific subpath of a repository as opposed to the root. In that case, you can specify that path in the (3) Path field. Note, that the selected path should be either empty (in which case, Prophecy is going to treat it as a new project) or contain a valid dbt Core project (in which case, Prophecy is going to import it).
Finally, click (4) Continue and your main project page will open. The project will be populated with our data sources, models, etc. Click Open in Editor to begin developing.
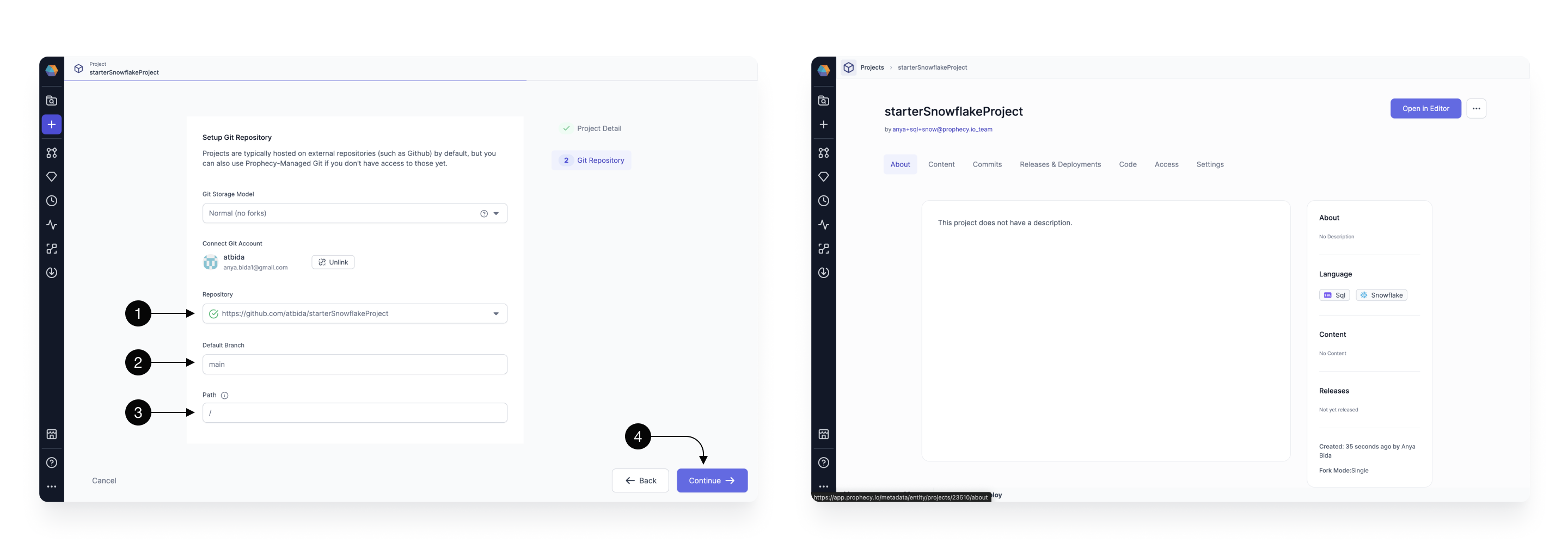
You can also connect to other external repositories like Bitbucket. Simply select a different Git provider and fill in the required credentials.
Start development
Congratulations! We’ve now successfully completed the one-time setup process of Prophecy with all the required dependencies. We can now execute queries on Snowflake's Warehouse and take advantage of Git’s source code versioning.
It’s time to start building our first data transformation project!
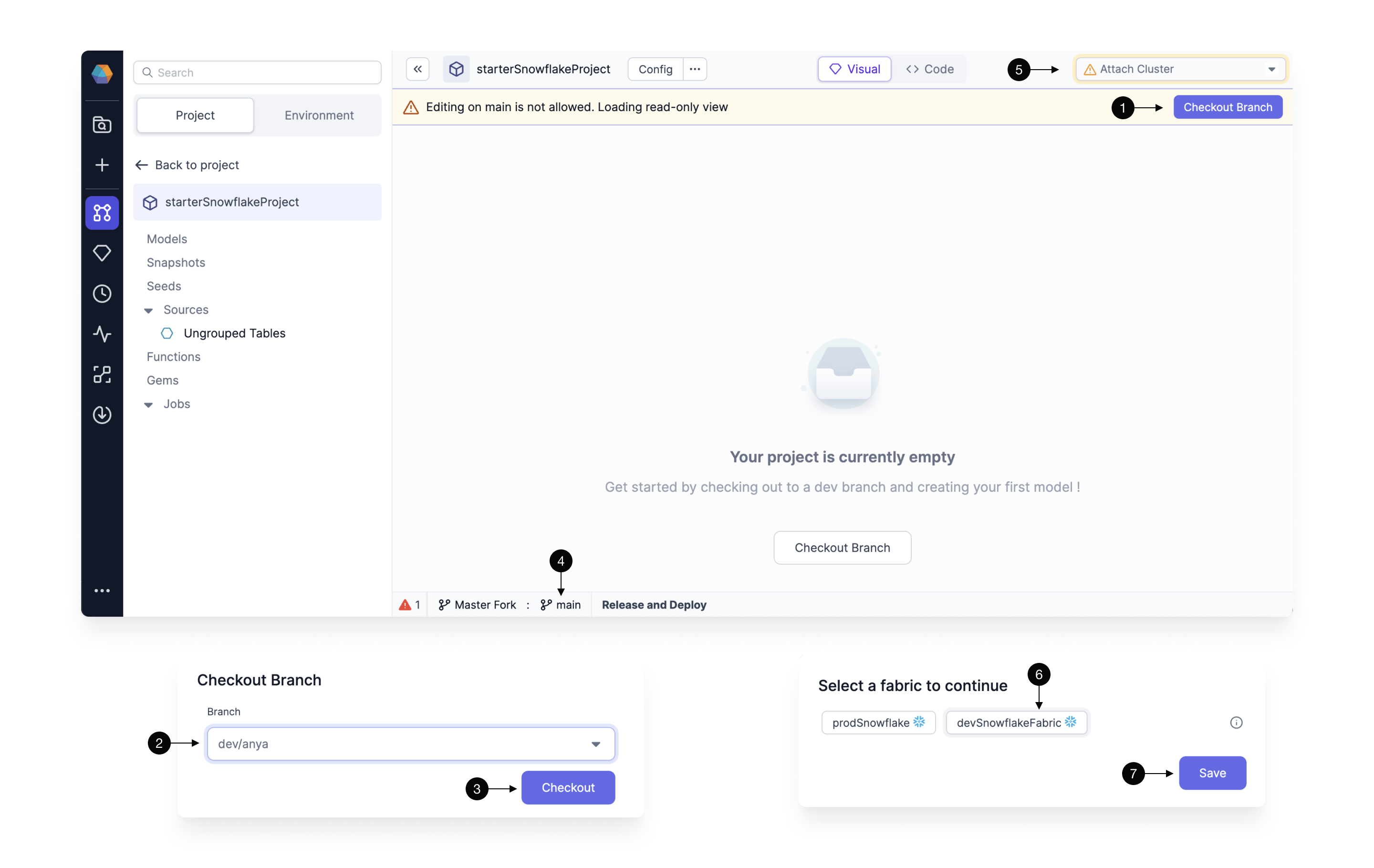
Checkout development branch
As a good teammate, we don’t want to write changes directly on the main branch of our Git repository. Every member should have their own branch on which they can freely build and play around with the project, without interrupting each other’s work. Prophecy enforces this best practice by ensuring that no changes can be made directly on the main branch.
Therefore, to start development we have to create our first development branch. Start by clicking on the (1) Checkout Branch and type in the desired name in the (2) Branch field. The best branch names should be representative of the changes that you’re making, so that your colleagues can quickly identify which changes are on which branch. The best branch names should be representative of the changes, and who made them, so that your colleagues can quickly identify which changes are on which branch. A good default name is dev/firstName. Once you decide on the name, click (3) Checkout. The new branch name will be displayed in the (4) Git footer.
Note, that if the branch doesn’t exist, Prophecy creates a new branch automatically by essentially cloning what’s on the currently selected branch - therefore make sure to usually create new branch (checkout) from main. If the branch exists, the code for that branch is pulled from Git into Prophecy.
Connect to a fabric
Prophecy allows for interactive execution of your modeling work. This allows you to run any SQL model directly on the fabric we’ve connected to and preview the resulting data. Fabric connection also allows Prophecy to introspect the schemas on your data warehouse and ensure that your development queries are correct.
After branch setup, fabric selection should pop-up automatically; if not, you can easily set the fabric by clicking on the (5) Choose cluster dropdown.
Choose the fabric of choice by clicking on it in the (6) Fabrics list, then simply (7) Save the settings.
Prophecy will quickly load all the available warehouses, databases, schemas, tables, and other metadata and shortly after to allow you to start running your transformations!
Define data sources
The first step, before building actual transformation logic, is definition of data sources. There are three primary ways to define data sources in a SQL project:
- seeds - which allow for loading small CSV datasets into your warehouse (useful for small test datasets or lookup mappings, like list of countries)
- Datasets - table pointer with schema and additional metadata
- other models - since each model defines a table, models can serve as inputs to another model (we’re going to cover models in the next section)
Create seeds
Seeds allow you to define small CSV-based datasets that are going to be automatically uploaded to your warehouse as tables, whenever you execute your models. This is particularly useful for business data tables or for integration testing on data samples.
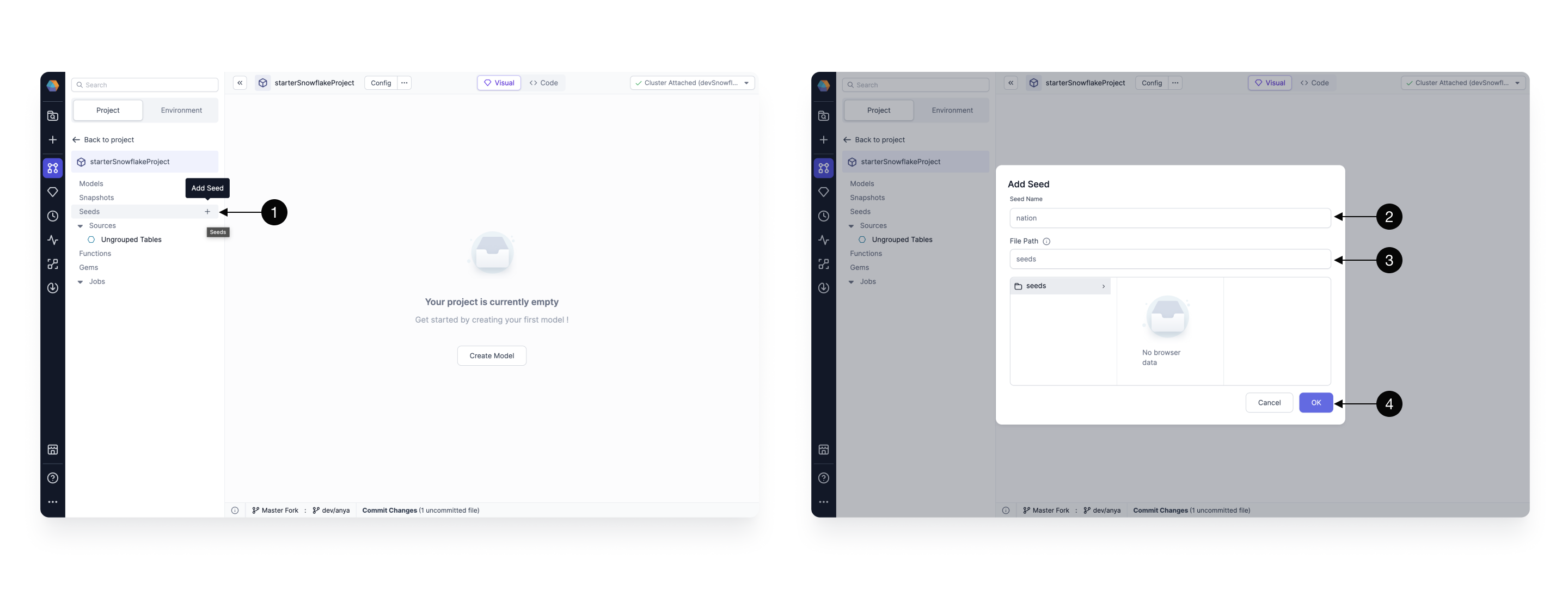
To create a seed click on the (1) + Add Seed button. A new pop-up window will appear where you can define metadata of the seed. There you can define the (2) Name of seed (which is going to be the same as the name of the table created) and the (3) Path for for it. When ready press (4) OK, to add.
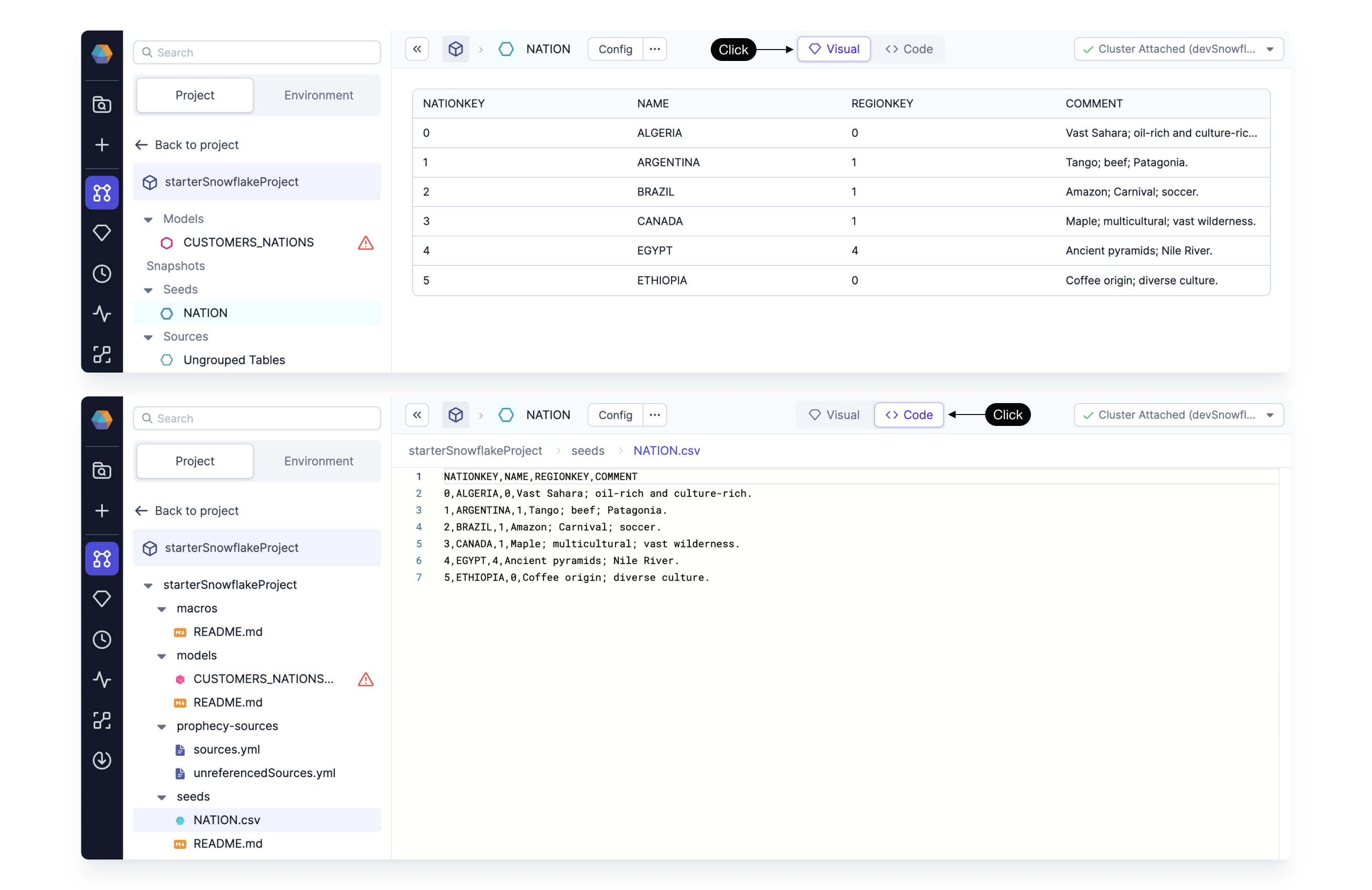
The seed initializes by default empty. To define the value simply copy and paste the content of desired CSV (each column separate by a comma, each row separated by a new line, with a header as the first line) into the (1) Code editor. To verify whether the seed is parsed correctly, you can see it after switching again to the (2) Visual editor.
For the purpose of this tutorial, create a nation seed, with the following content:
NATIONKEY,NAME,REGIONKEY,COMMENT
0,ALGERIA,0,Vast Sahara; oil-rich and culture-rich.
1,ARGENTINA,1,Tango; beef; Patagonia.
2,BRAZIL,1,Amazon; Carnival; soccer.
3,CANADA,1,Maple; multicultural; vast wilderness.
4,EGYPT,4,Ancient pyramids; Nile River.
5,ETHIOPIA,0,Coffee origin; diverse culture.
Define datasets
Importing datasets is really easy. Upload a file or drag-and-drop existing tables directly into a model. We’re going to demonstrate that in the next step.
Develop your first model
A model is an entity like a pipeline that contains a set of data transformations. However, a model defines a single output - a view or a table that will be created on the warehouse of choice. Each model is stored as a select statement in a SQL file within a project. Prophecy models are based on dbt Core models.
Here we create a customers_nations model that’s going to enrich our customers and produce a report of which customers show up in which geographic areas most commonly. Follow along with the customer table from your Snowflake Warehouse (Database: SAMPLE_DATA, Schema: TPCH).
The customers_nations model is stored as a .sql file on Git. The table or view defined by the model is stored on the SQL warehouse, database, and schema defined in the attached fabric.
Suggestions are provided each step of the way. If Copilot's suggestions aren't exactly what you need, just select and configure the gems as desired. Click here for details on configuring joins or here for aggregations.
Interactively Test
Now that our model is fully defined, with all the logic specified, it’s time to make sure it works (and keeps working)!
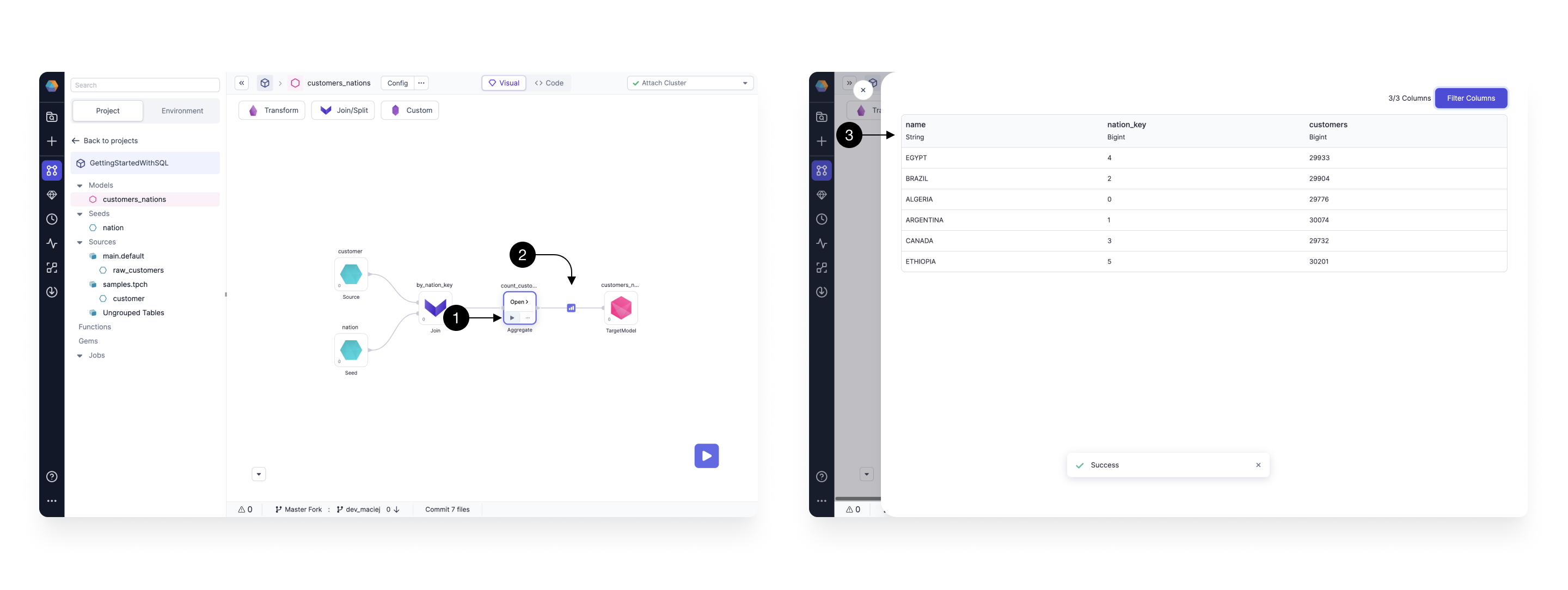
Prophecy makes interactively testing the models incredibly easy! Simply:
- Click the Play button on any of the gems and the model with all of it’s upstream dependencies will be executed.
- Once the model runs, the Result icon appears.
- Click the Result icon to view a Sample set of records.
Notice Copilot is offering suggested fixes when errors appear. See how Fix with AI works here. Explore suggested fixes in the canvas, inside each transformation gem, or inside gem expressions.
Code view
The visual developers will appreciate the drag-n-drop canvas, but sometimes it's also nice to view the code. Already Prophecy creates highly performant code behind the scenes. Just click the Code View to reveal the SQL queries we've generated using our visual design editor. Each gem is represented by a CTE or subquery. For example, the Join gem NATIONS_CUSTOMERS is highlighted in both visual and code views.
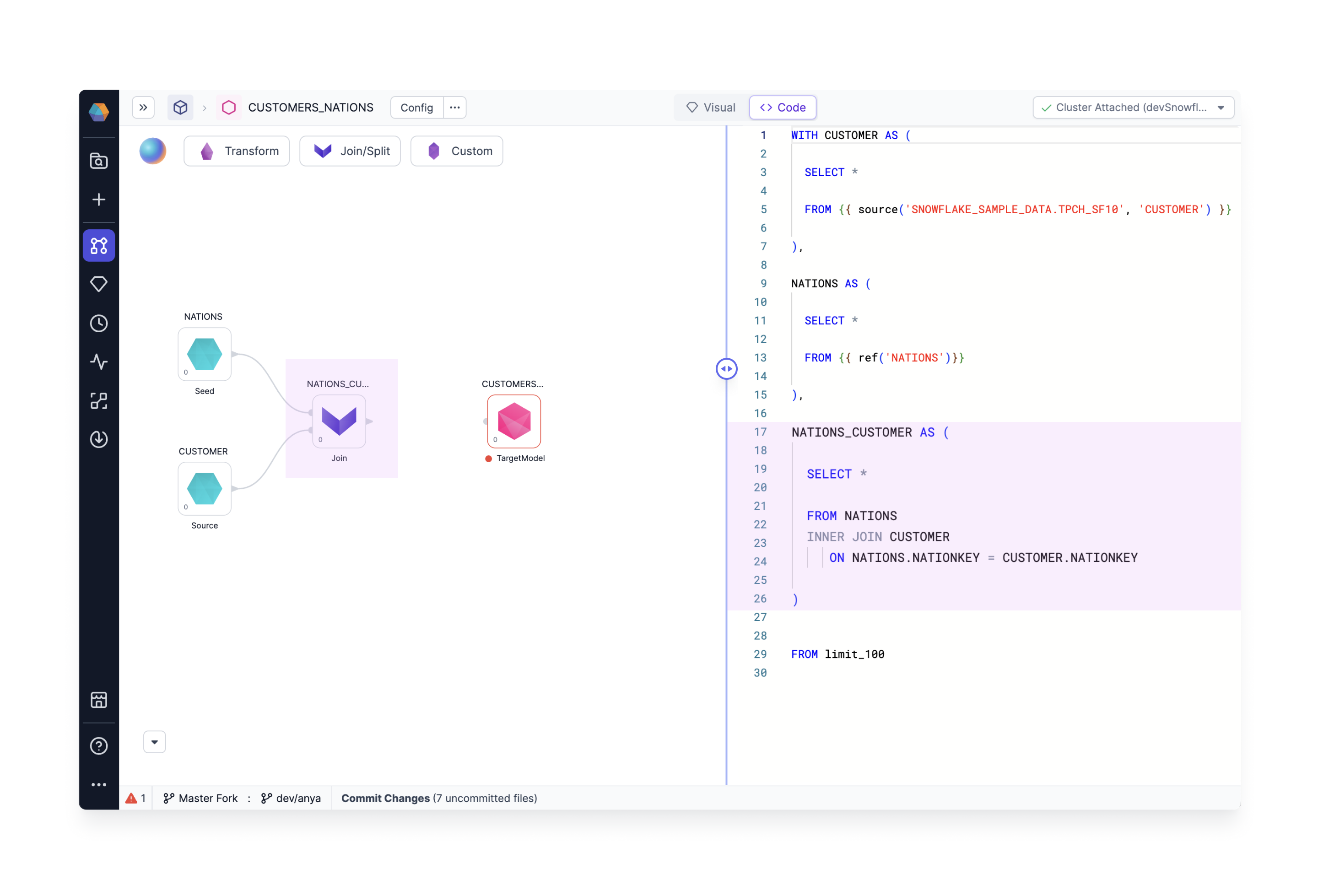
You may wish to edit the code view - give it a try! Add a SQL statement in the code view and notice the visual editor displays the updated code. For example, we've added a limit statement in the code view, and a new limit gem appears in the visual view.
Commit and Release with Git
It's a good thing you've been working on your "development branch" for this guide, because now you'll step through the process of integrating your hard work with the rest of your team on the "main branch." Integration with Git is easier than it sounds. Commit early and commit often! You will commit, pull, merge, and release by following the steps here.
Prophecy guides your team's code management - with version control, tagged releases, and lets multiple individuals contribute to the same project - so you can focus on solving your business problems.
Schedule Jobs with Airflow
Most Snowflake users want to schedule jobs using Airflow. Prophecy integrates with MWAA and Composer Airflows. Don't have an Airflow account? Prophecy also provides a managed Airflow option. Setup your favorite Airflow option and use this guide to schedule Airflow jobs. Now you can schedule SQL models integrated with your Spark pipelines, S3 file sensors, etc.
What's next
Great work! You've successfully set up, developed, and tested your first SQL project on a Snowflake warehouse. Integration and job scheduling put you on solid footing for production-readiness. Wherever you are in your data journey, know that Prophecy is here to encourage best practices to boost your productivity.
If you ever encounter any difficulties, don't hesitate to reach out to us (Contact.us@Prophecy.io) or join our Slack community for assistance. We're here to help!