Spark with Databricks
When you build pipelines in Prophecy, you can connect to a variety of execution engines to run those pipelines. Complete the tutorial below to learn about using Databricks to compute with Spark and try it yourself!
Requirements
For this tutorial, you will need:
- A Prophecy account.
- A Databricks account.
- Permission to create Spark clusters in Databricks.
Create a Databricks Spark fabric
A fabric in Prophecy is an execution environment. In this tutorial, you'll see how to use Databricks as your execution environment in Prophecy. Let's begin!
- Open Prophecy.
- Click on the Create Entity button in the left navigation bar.
- Select the Fabric tile.
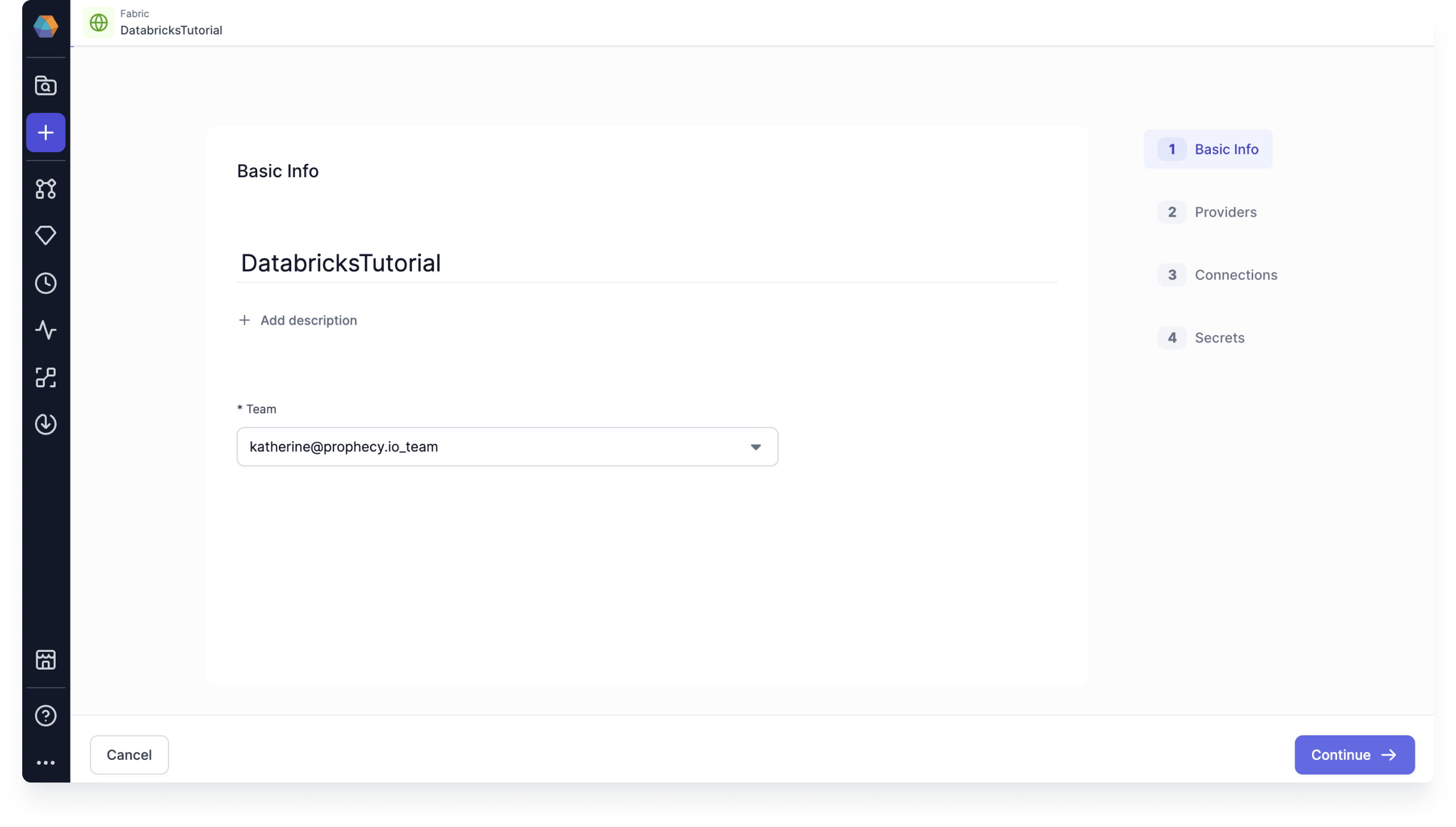
- Give the fabric any name, like
DatabricksTutorial. - Select the team that will be able to use the fabric. For this tutorial, you might want to select your personal team. (It will match your individual user email.)
- Click Continue.
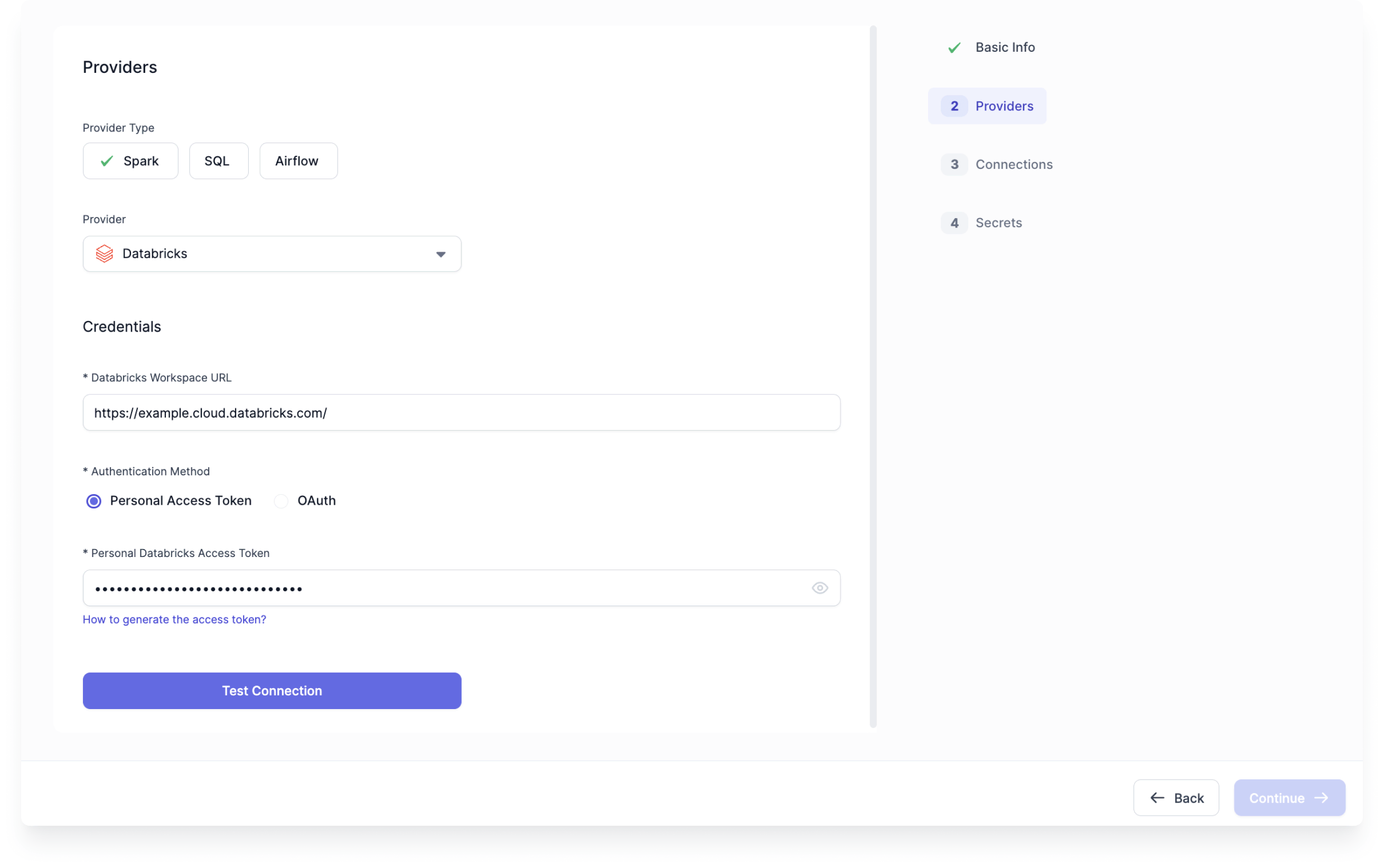
Now, you will enter your Databricks credentials.
- Choose Spark as the Provider Type.
- Select Databricks under Provider.
- Enter your Databricks Workspace URL. This will be the URL that you use to open your Databricks Workspace.
- For this tutorial, we'll use a Personal Access Token for authentication. Visit the Databricks documentation to learn how to generate a personal access token.
- Paste your Databricks Personal Access Token.
- Now, click Test Connection. This test must be successful to continue with fabric creation.
- After the test succeeds, click Continue.
You are almost done setting up your Databricks fabric!
- We'll skip the Connection section for now. Click Continue.
- We don't need to add any secrets at this point. Click Complete.
Create a Prophecy project
After you create your first Spark fabric, you'll see a project in Prophecy called HelloWorld. If you just want to play around with Prophecy, you can start there. However, for the purpose of this tutorial, let's build a new project from scratch.
- Once again, click on the Create Entity button in the left navigation bar.
- Hover over the Project tile and select Create.
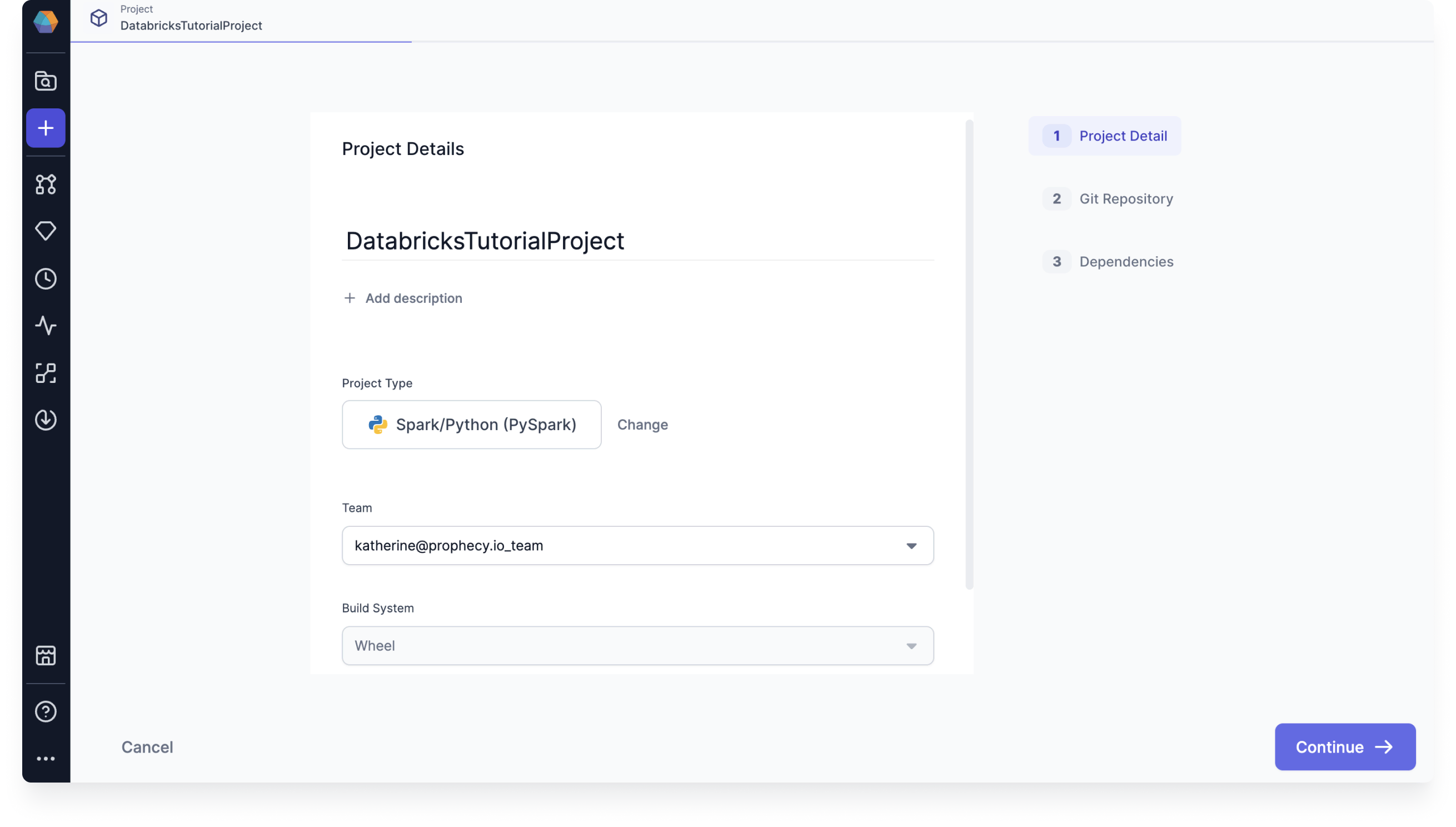
- Give your project a name.
- For the Project Type, choose Spark/Python (PySpark).
- Select the team that will have access to your project. Again, you might want to use your personal team.
Set up Git repository
Prophecy uses Git for version control. Each project in Prophecy is stored as code in its own repository or folder in a repository. For this project, we suggest that you use Prophecy-managed Git. When you are ready to use Prophecy for a production use case, connect to an external Git provider. This provides extra functionality for you to work with.
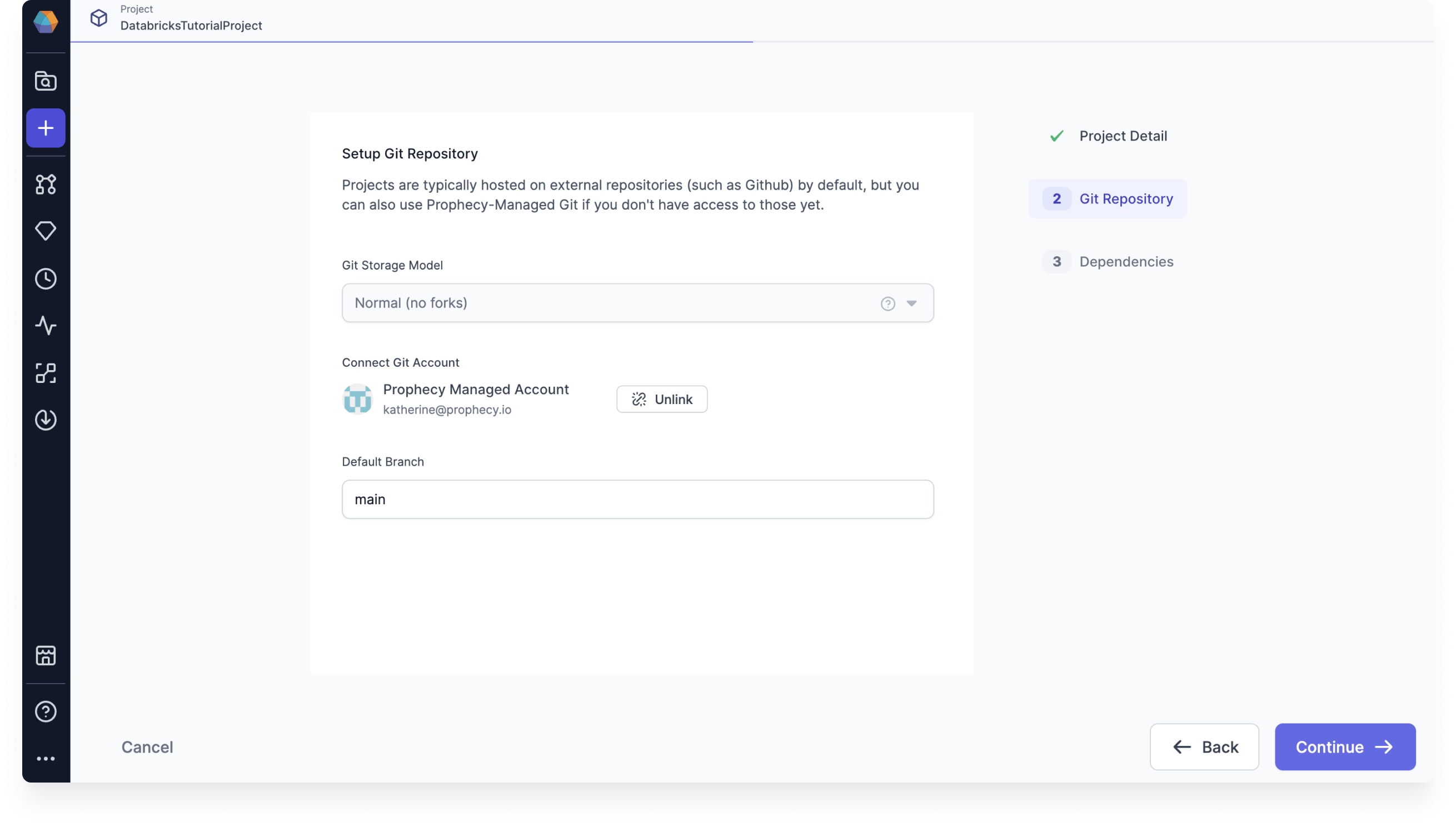
Once you have set up your Git repository, click Continue.
Select project dependencies
In the Project Dependencies section, you have the option to include additional functionality in your project. A few dependencies are added by default, and these are all we will need to get started. Click Complete, and then View Project.
Project metadata and editor
You should see the project metadata page. Project metadata includes information about the contents, dependencies, settings, and more related to your project. We want to start editing the project, so click Open in Editor.
Develop a pipeline
You should now see your empty project. Let's add a pipeline!
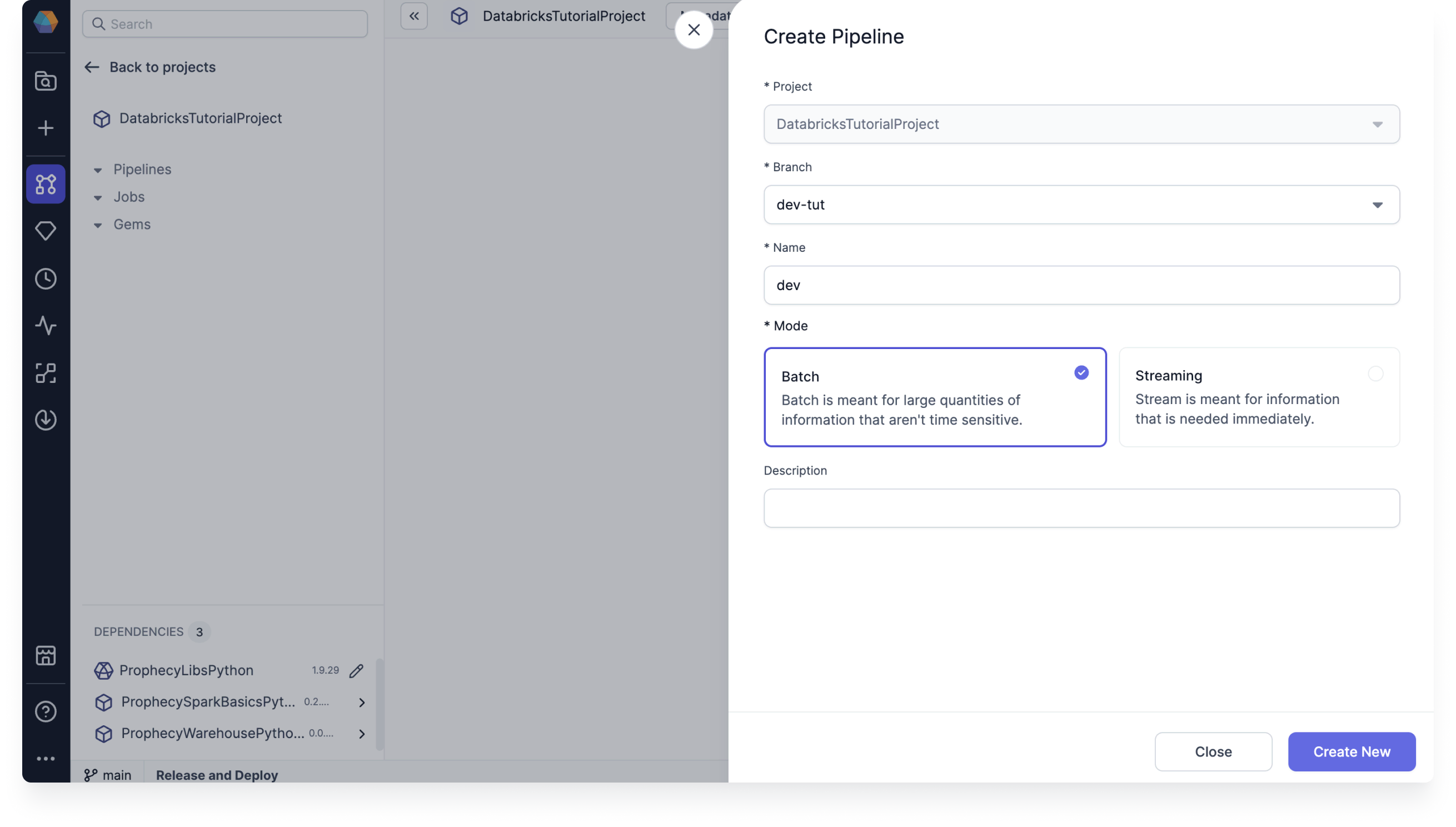
- To get started, click the Create Pipeline button.
- Create a new Git branch where you will begin developing this pipeline.
- Give the pipeline a name, like
dev. - Choose Batch mode.
- Click Create New.
Next, we can start building the pipeline. If you want to run the pipeline as you develop it, you need to attach your Databricks fabric now.
- In the upper right corner of the pipeline editor, click on the Attach a cluster dropdown.
- Select the fabric you created earlier.
- Choose a cluster to attach to. If you don't have any clusters, or if your clusters aren't running, you can choose to create a new cluster from the Prophecy UI.
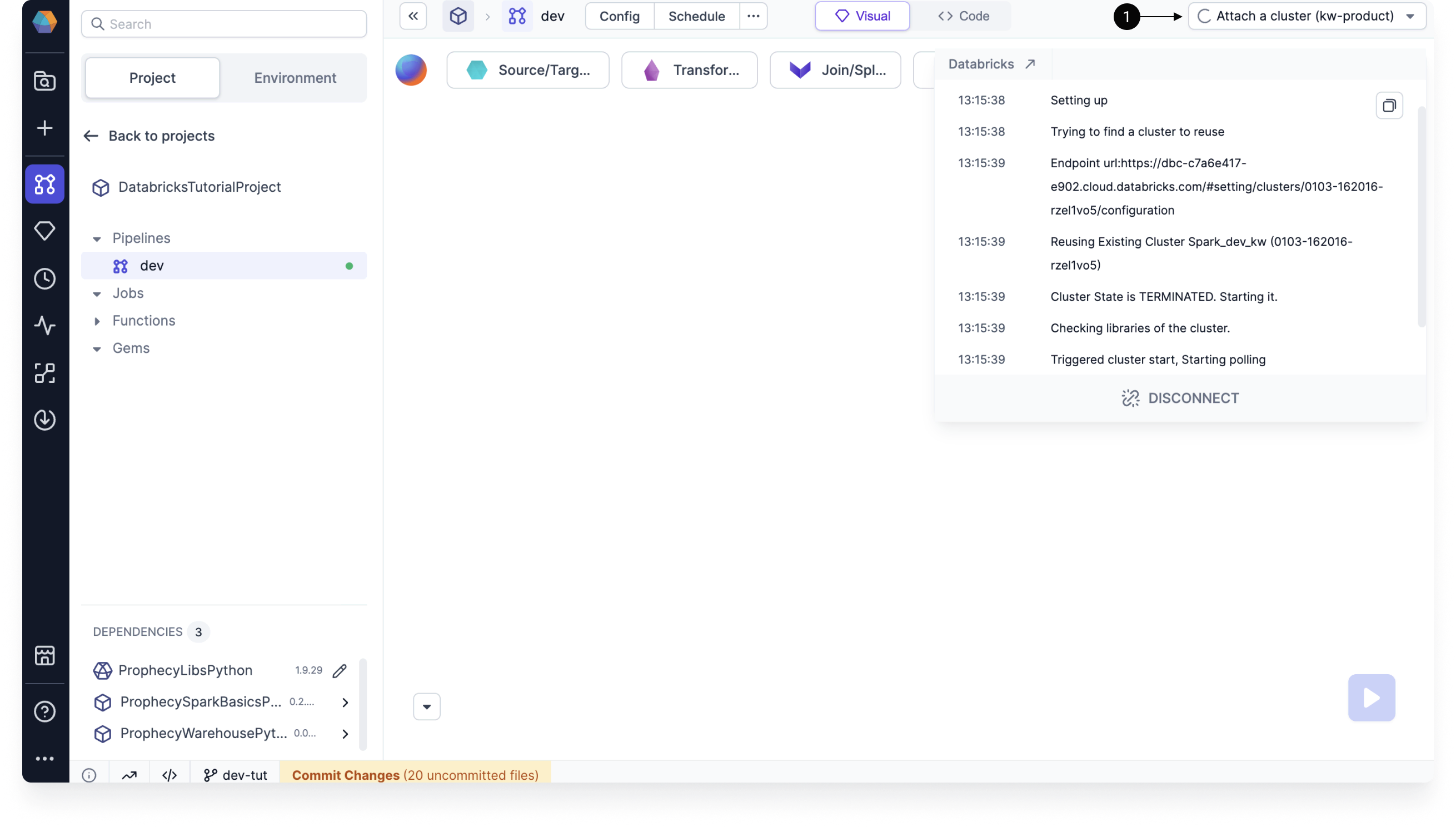
The cluster may take some time to start up. Once the cluster is up and running, you can move on to the next section.
Source gem
The first thing we need in the pipeline is a data source.
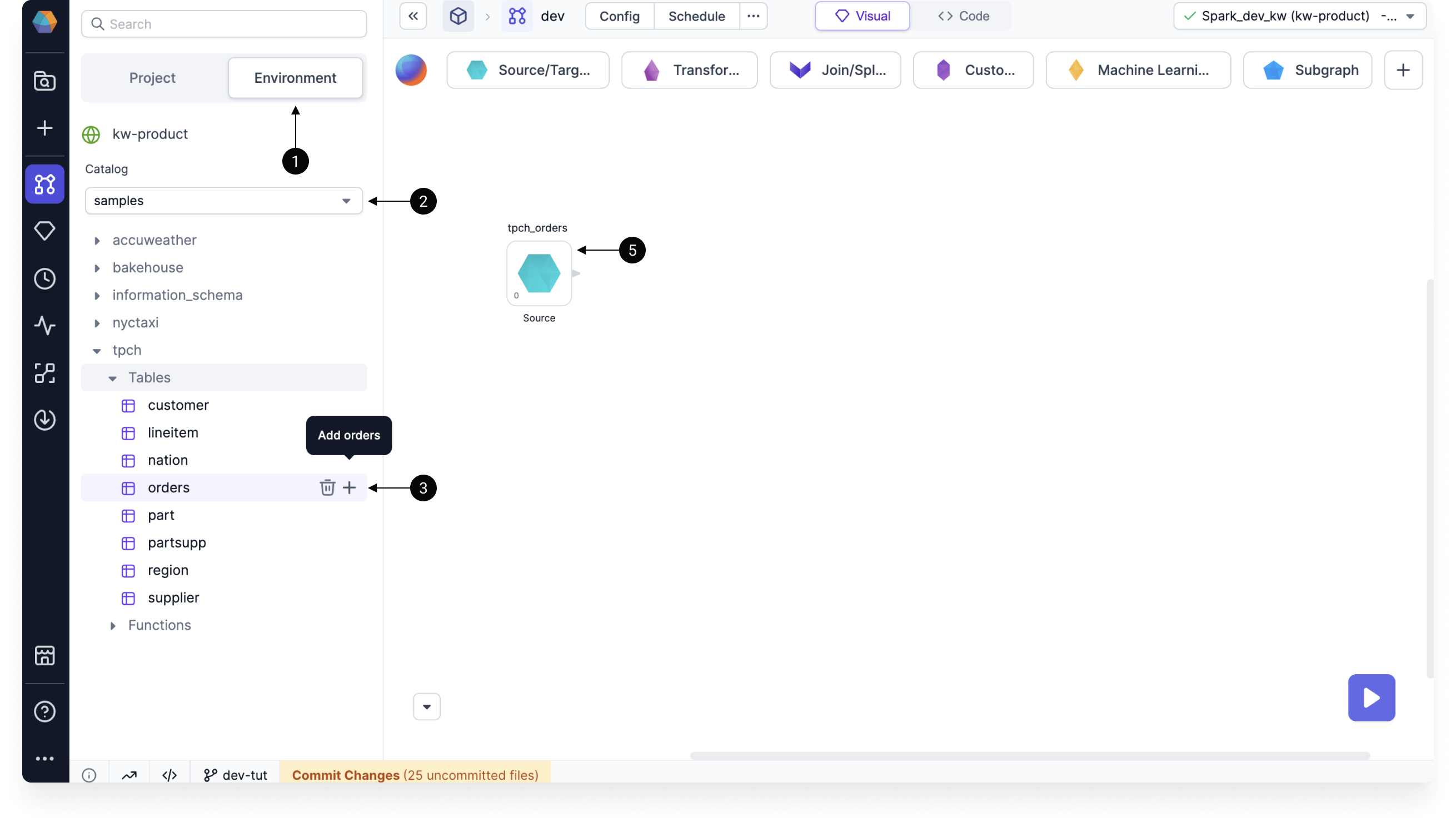
When you are connected to a Databricks fabric, you can browse the Databricks catalogs in the Environment tab of the left sidebar. From here, you can drag and drop tables onto the pipeline canvas. To make things easy, we'll use one of Databricks' sample tables.
- Open the Environment tab of the left sidebar.
- Select the samples catalog.
- Under tpch > Tables, click the plus sign next to the orders table.
- In the dialog, choose Source gem and name the gem. Then, click Add.
- A Source gem should be added to the pipeline canvas.
Reformat gem
Next, let's add a new column to the dataset using the Reformat gem to extract the month and year from the order date.
- Click on Transformations to see the transformation gems.
- Select Reformat. This adds the gem to the canvas.
- Connect the Source gem output to the Reformat gem input.
- Hover the Reformat gem and click Open.
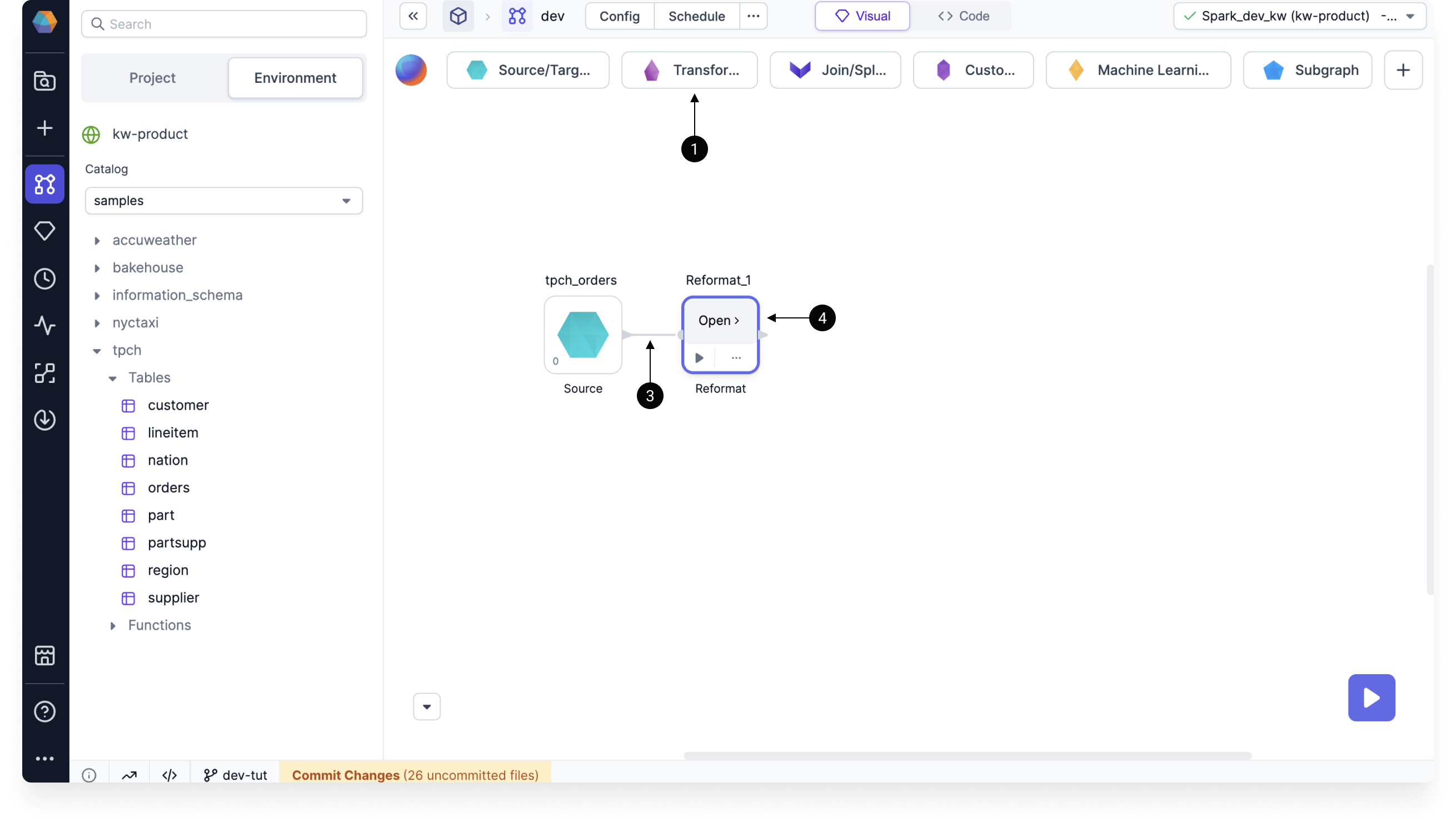
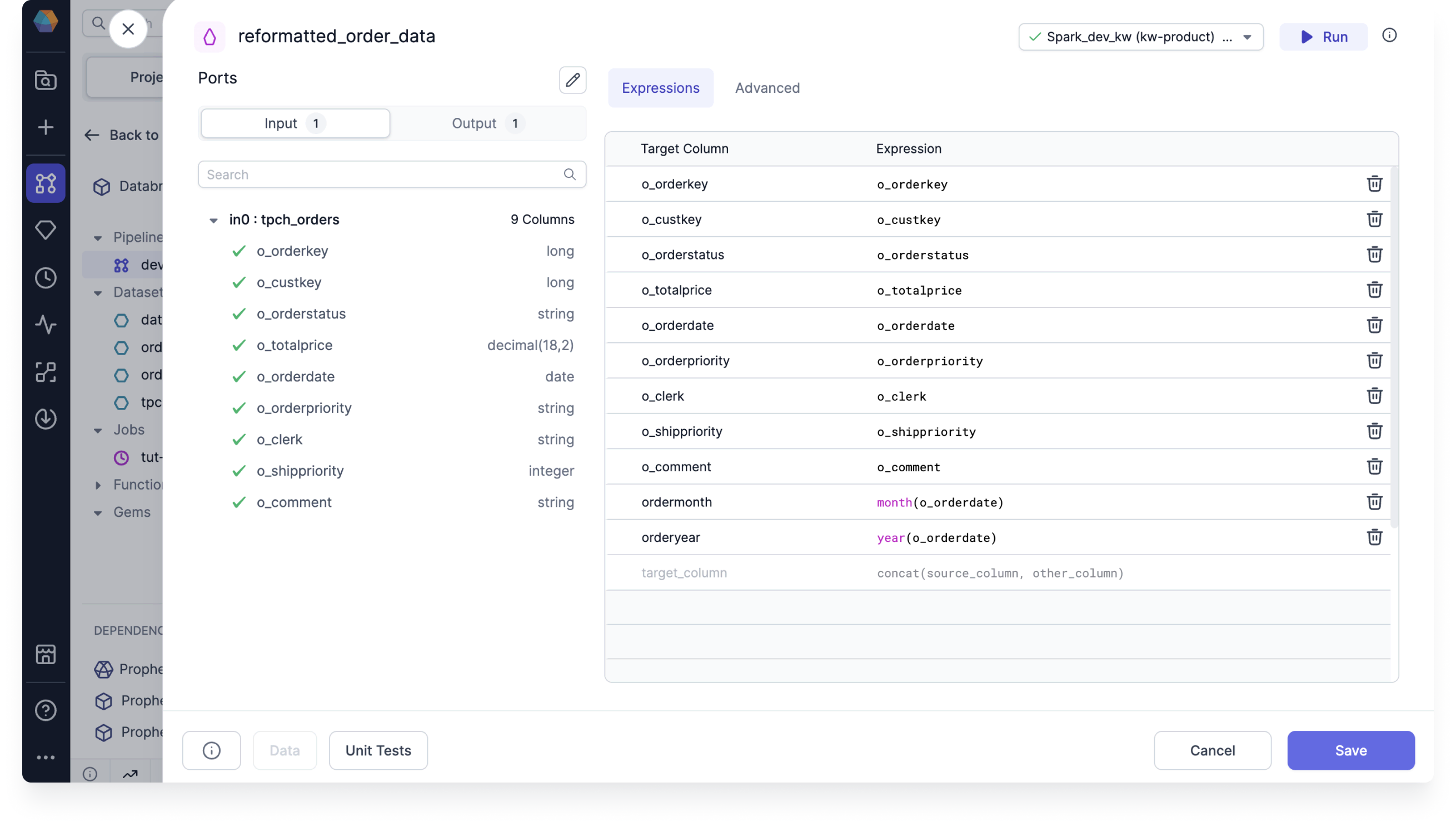
Add the following configurations:
- Hover in0:tpch_orders and click Add 9 columns.
- In the next available row, type
ordermonthin the Target Column. - In the Expression cell, paste
month(o_orderdate). - In the next available row, type
orderyearas the target column andyear(o_orderdate)as the expression. - Review the new output schema in the Output tab of the gem.
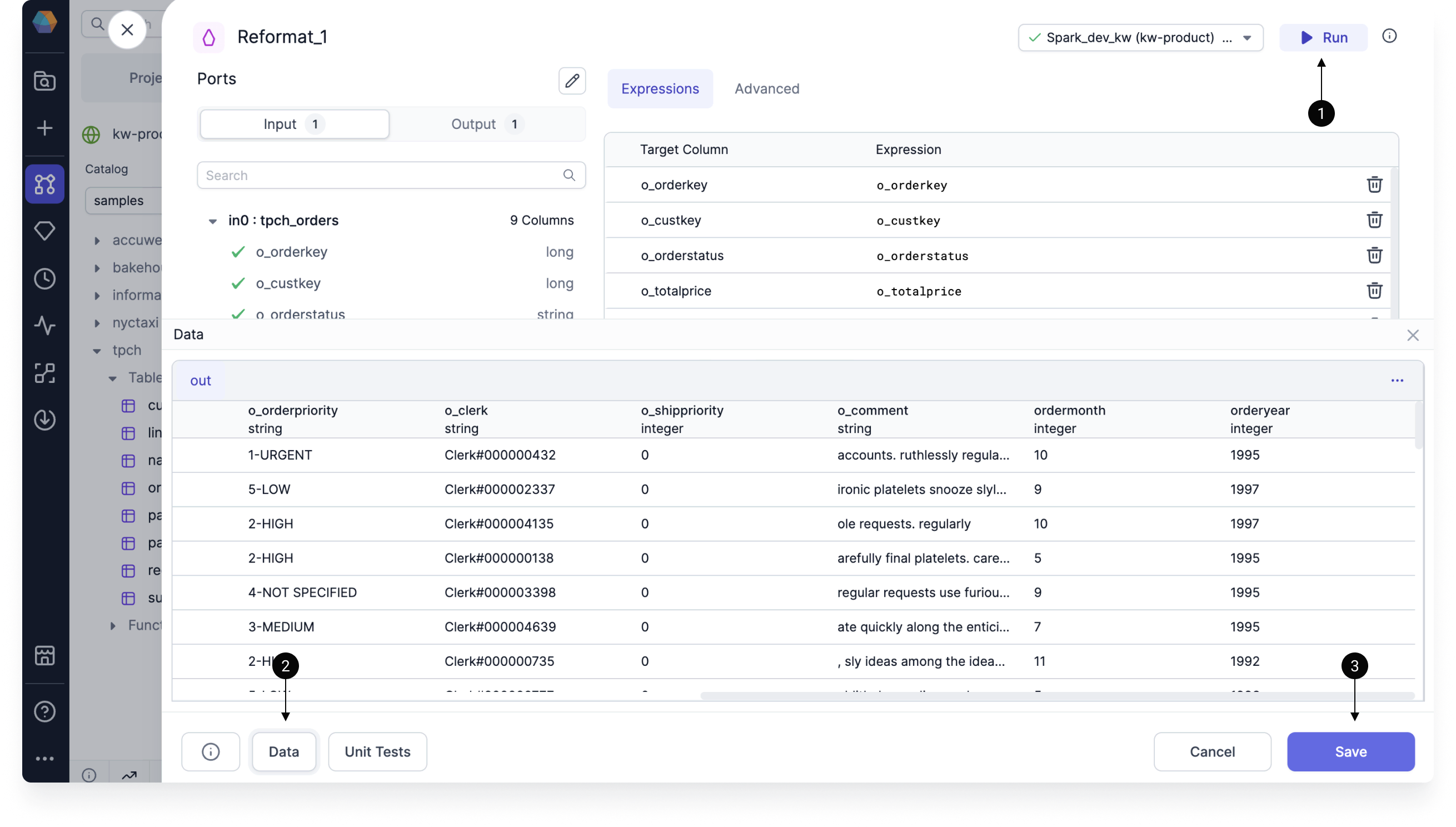
To preview the output of the gem:
- Click Run in the top right corner. This will execute the pipeline up to and including the gem.
- You'll be able to see a sample output dataset under Data in the gem footer.
- If you Save and close the gem, you will also be able to see a new small icon in the output of the Reformat gem. You can click on this to open the interim data sample.
- To learn more about running pipelines, visit Interactive Execution.
- To learn more about Spark SQL expressions in gems, visit Expression Builder.
Aggregate gem
Another common gem to use is the Aggregate gem. Let's use it to find the total sales amount per month each year.
- Select Transformations > Aggregate to add the Aggregate gem to the canvas.
- Connect the output of Reformat to the input of Aggregate. Then, open the Aggregate gem.
- Add the o_totalprice column to the Aggregate table.
- Next to amount, write
sum(o_totalprice)as the expression. - Switch to the Group By tab, and add the orderyear and ordermonth columns.
- Save the gem.

Target gem
Once you know how to use a couple of gems, you can experiment with others in the pipeline. When you are finished transforming your data, you should write the final table to a target location:
- Select Source/Target > Target to add the Target gem to the canvas.
- Connect the Target gem after the Aggregate gem and open it.
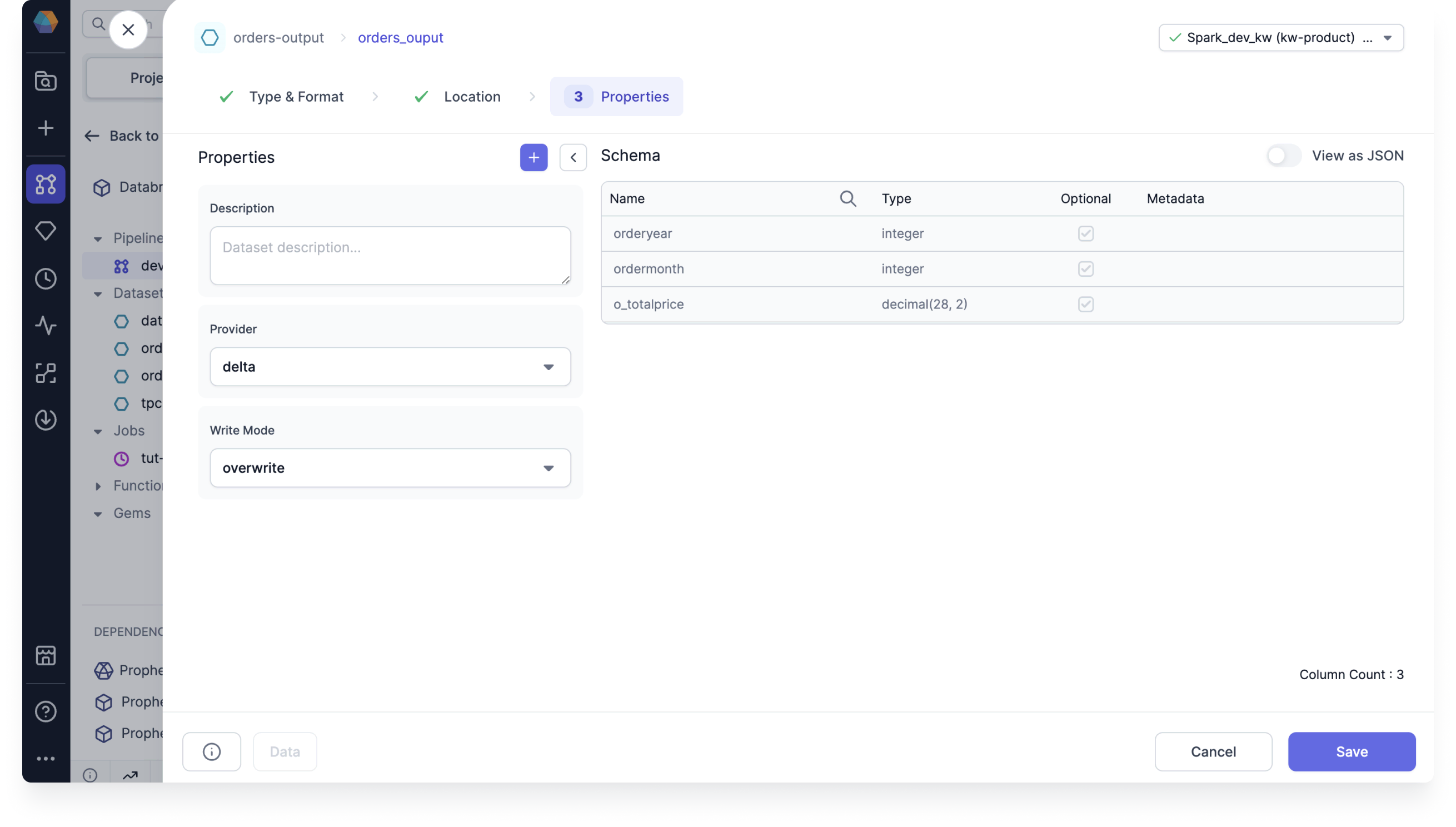
- Click + New Dataset and give the new dataset a name.
- Choose the format to save the dataset, then click Next.
- Choose the location to save the dataset, then click Next.
- In the Properties tab, under Write Mode, select overwrite.
- Confirm the schema, and then click Create Dataset.
To write the data, we should run the whole pipeline. Click on the big play button in the bottom right corner to do so.
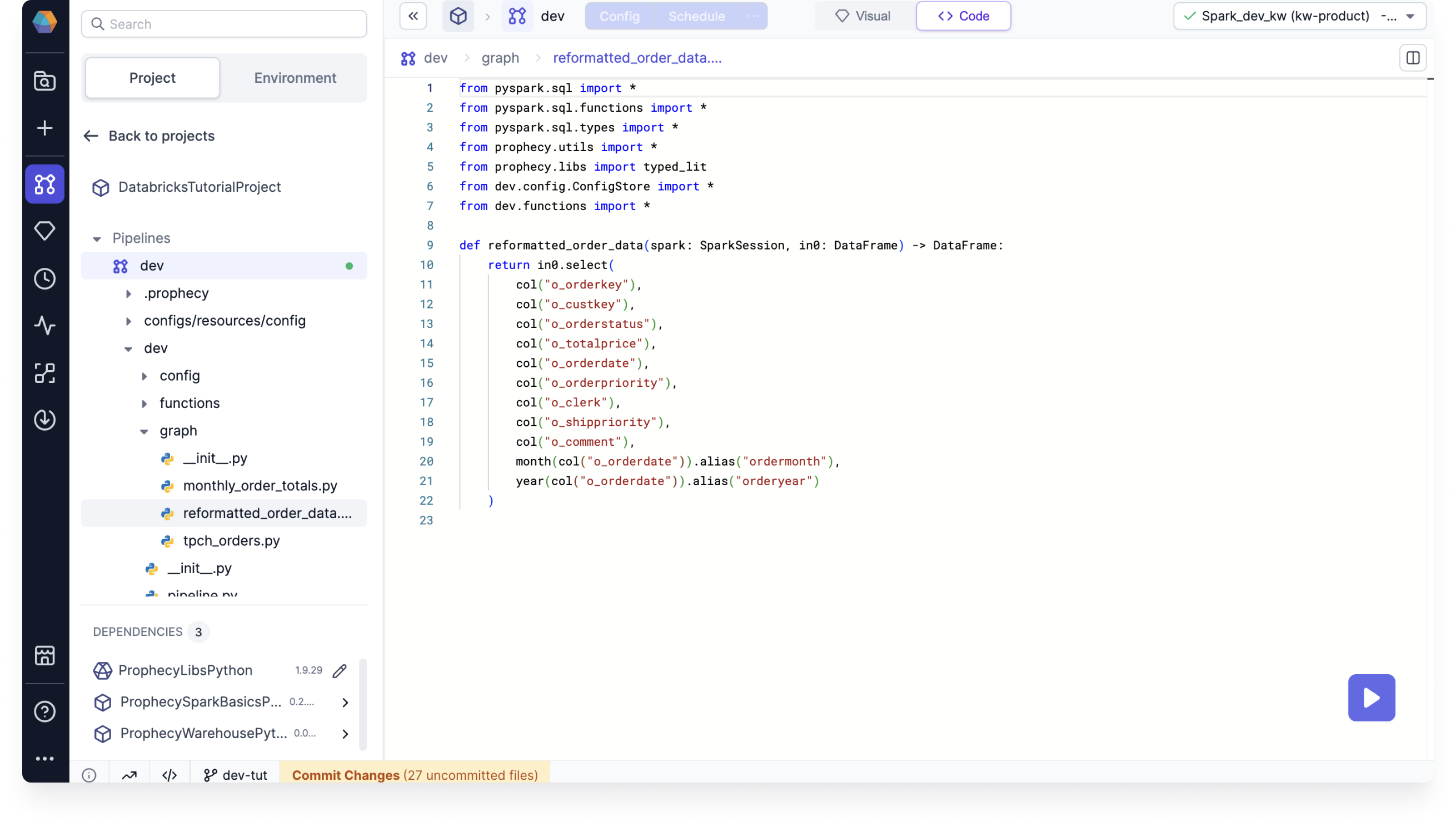
Review the code
This far, we've only made changes in the visual editor of the project. If you want to see how your pipeline looks in code, switch to the Code view. Since we made a Python project in this tutorial, the code is in Python.
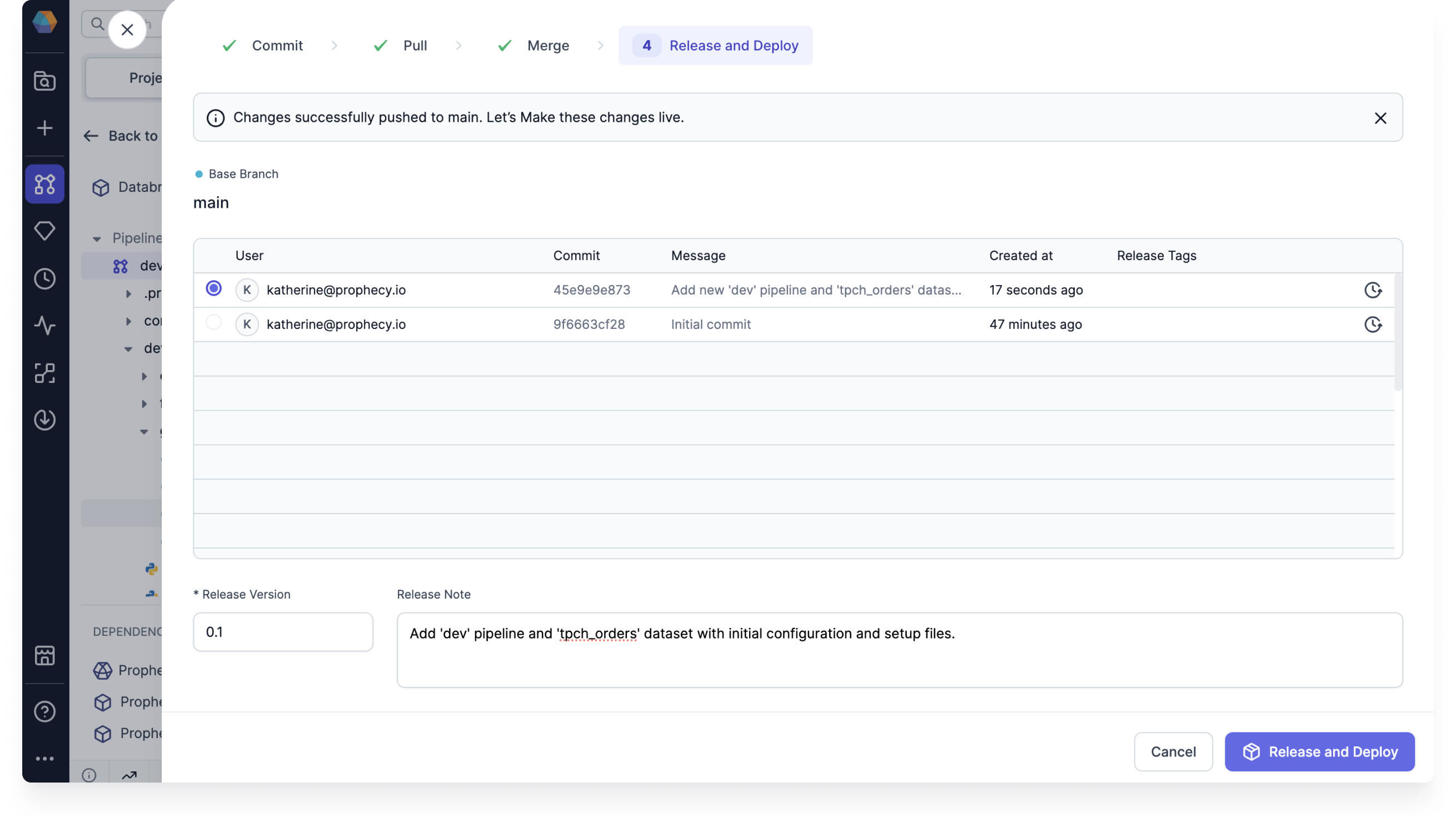
Release and deploy the project
- In the project footer, click Commit Changes. This will open the Git dialog.
- Review your changes and the auto-generated commit message. Then, select Commit.
- Because there were no changes made to remote or source branches, we can skill the Pull step.
- Merge your current branch into the main branch by clicking Merge.
- Lastly, you can Release and Deploy your project. This makes a certain version of your project available for use (in a CI/CD workflow, for example).
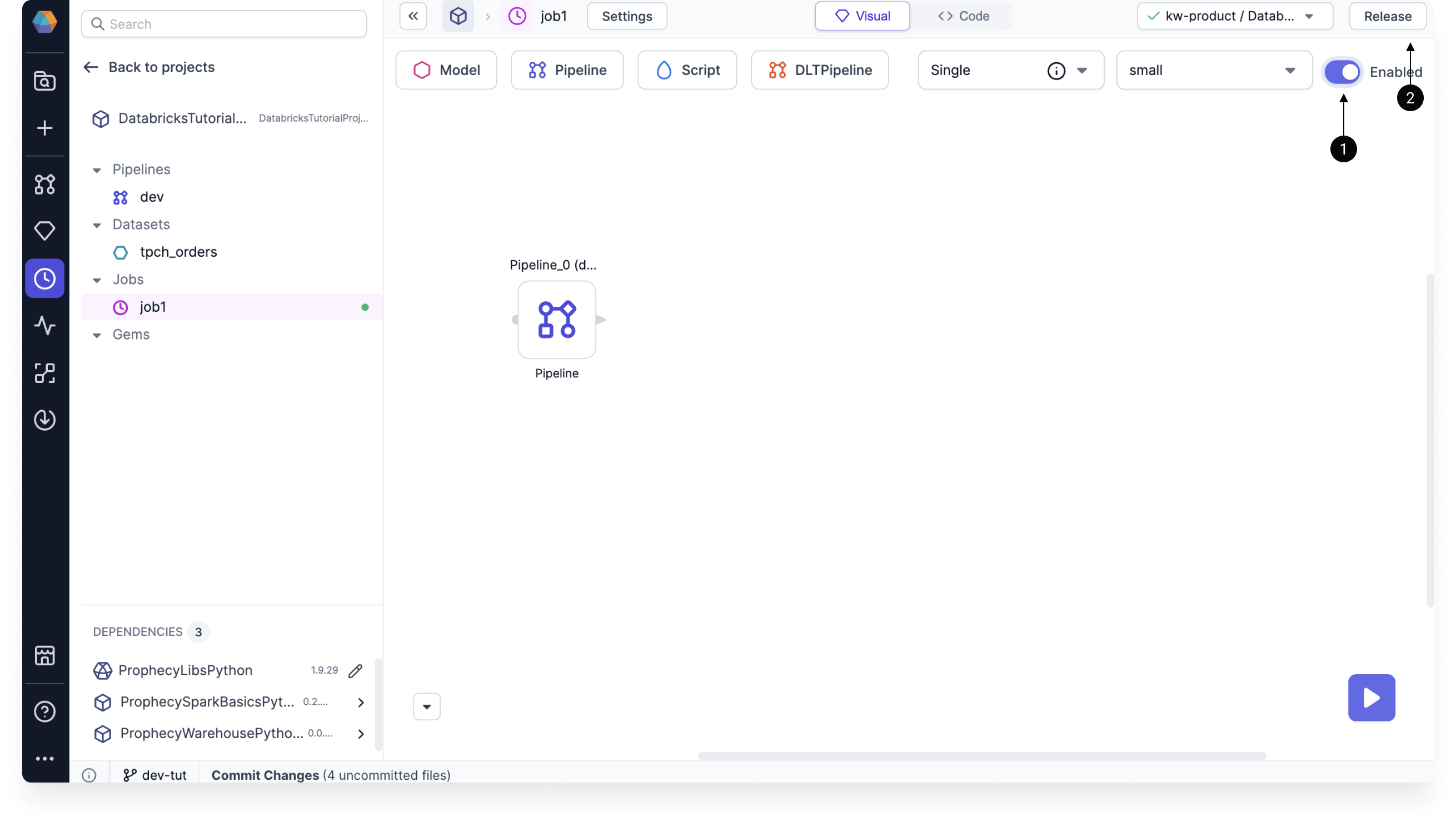
Create a Databricks job
If you want to schedule your pipeline to run periodically, you can create a job to do so.
- In the left sidebar, hover over Jobs and click the plus sign.
- Fill in the required fields. For this project, use the Databricks scheduler.
- Leave the schedule interval blank for now. This is where you define the job run frequency.
- Click Create New.
Now, you can configure the flow of your job.
- Click on Pipeline to add it to the canvas.
- Under Pipeline to schedule, choose the pipeline you created in this tutorial.
- Click Save.
Enable the job
To enable this job, you must complete the following two steps:
- Turn on the Enabled toggle.
- Release your project.
If you do not release your project, the Databricks scheduler will not see that you have enabled this job.
What's next
Great work! You've successfully set up, developed, run, and deployed your first Spark project using a Databricks execution environment. Take a moment to appreciate your accomplishment!
To continue learning and expanding your skills with Prophecy, keep exploring our documentation and apply your newfound knowledge to address real-world business challenges!
If you ever encounter any difficulties, don't hesitate to reach out to us (Contact.us@Prophecy.io) or join our Slack community for assistance. We're here to help!