PBT on Jenkins
Example GitHub Repo
Context of the Jenkins CI/CD Example
In this section we will explore how to set up separate "testing" and "deploying" Jenkins Jobs using declarative Pipelines. These Jobs will be triggered when items are merged into the following protected branches
prod, qa, develop. Each of these three branches represents a different Databricks Workspace environment. We
want to be able to test and deploy our Pipelines into each of these three workspaces during our release workflow.
The release process on GitHub is defined as merging and testing to branches in the following
order: feature-branch > develop > qa > prod
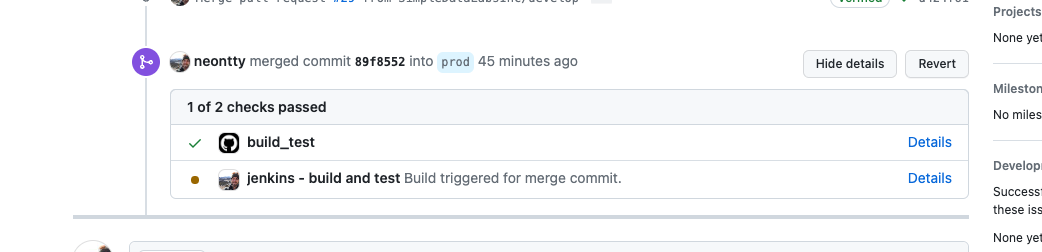 When PRs are made to a protected branch, the unit tests must pass before the PR can be merged
When PRs are made to a protected branch, the unit tests must pass before the PR can be merged
Once the PR is merged successfully, we deploy the artifacts and Job definitions to Databricks.
The Git project for this example will soon be made publicly available. To keep as much of the CICD logic attached to the Git project itself, we will store the Jenkinsfiles directly in the repo and only store the Jenkins Triggers and Credentials in the Jenkins server.
This example is currently designed for Pyspark Pipelines. To use the same recipe
for Scala Pipelines, just make sure JDK 11 is installed on your Jenkins nodes.
Preparation
You should have access to:
- a Git repo with an existing Prophecy Project
- a Jenkins Server where you can create new pipelines and credentials
Jenkins plugins
The following plugins were used for this example:
- GitHub Pull Request Builder
- for the build/test Job
- GitHub
- for the deploy Job
These plugins may have published vulnerabilities for older versions of Jenkins. Please make sure to check with your Jenkins server admin or security admin before installing any plugins.
Jenkins Secrets
You may require more or less secrets depending on the number of workspaces you are deploying to.
- DEMO_DATABRICKS_HOST
- the hostname for our Databricks workspace that houses our
qaanddevenvironments.
- the hostname for our Databricks workspace that houses our
- DEMO_DATBRICKS_TOKEN
- the token for DATABRICKS_HOST
- PROD_DATABRICKS_HOST
- the hostname for our Databricks workspace that houses our
prodenvironment.
- the hostname for our Databricks workspace that houses our
- PROD_DATBRICKS_TOKEN
- the token for PROD_DATABRICKS_HOST
FABRIC_ID
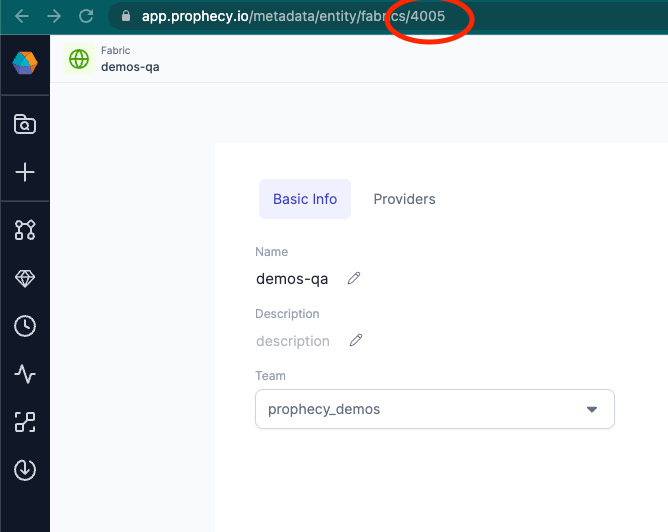
Find the Fabric IDs for your Fabrics by navigating to the Metadata page of that Fabric and observing the URL.
Metadata > Fabrics > <your Fabric>
Testing Pipeline
This Pipeline uses PBT to validate the pipelines and run all Prophecy unit tests.
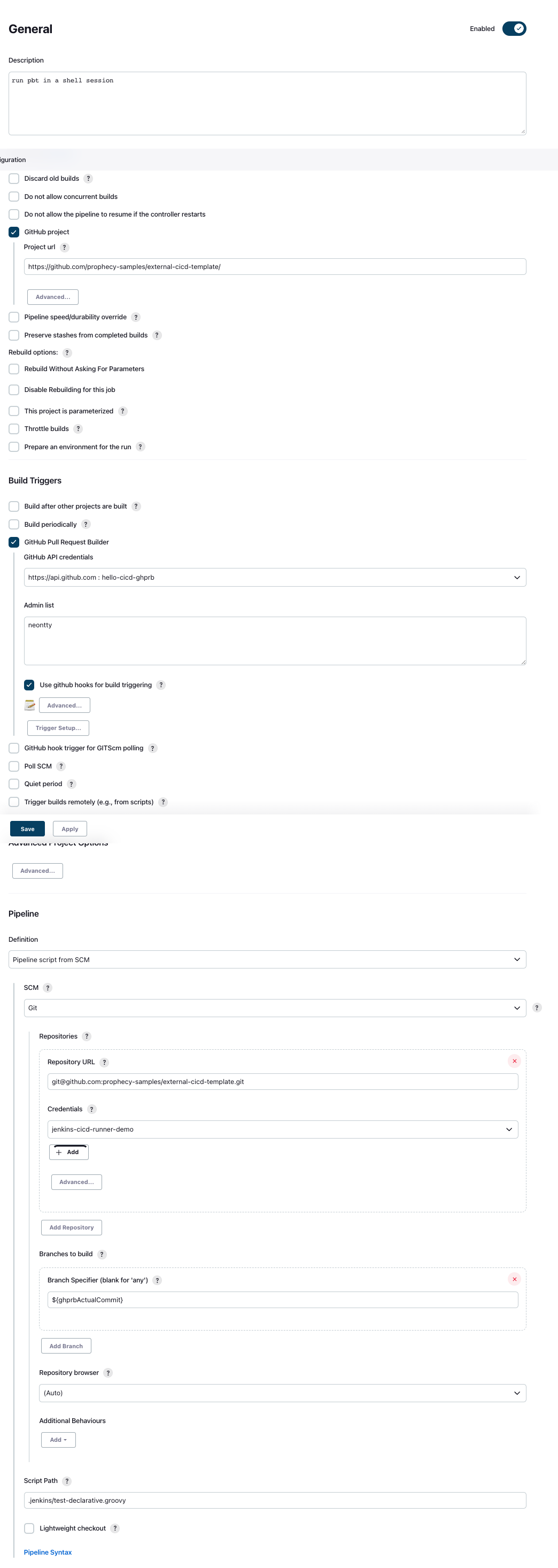
Testing Pipeline - Pipeline Creation
- Create a Jenkins Pipeline

- Configure the GitHub Project URL
- Choose GitHub Pull Request Builder as the trigger type.
- Provide credentials to GitHub
- creating a fine-grained Personal Acces Token (PAT) in GitHub. The PAT should be
scoped to yourself or your Organization, have access to the repository containing the Prophecy project, and
appropriate permissions:
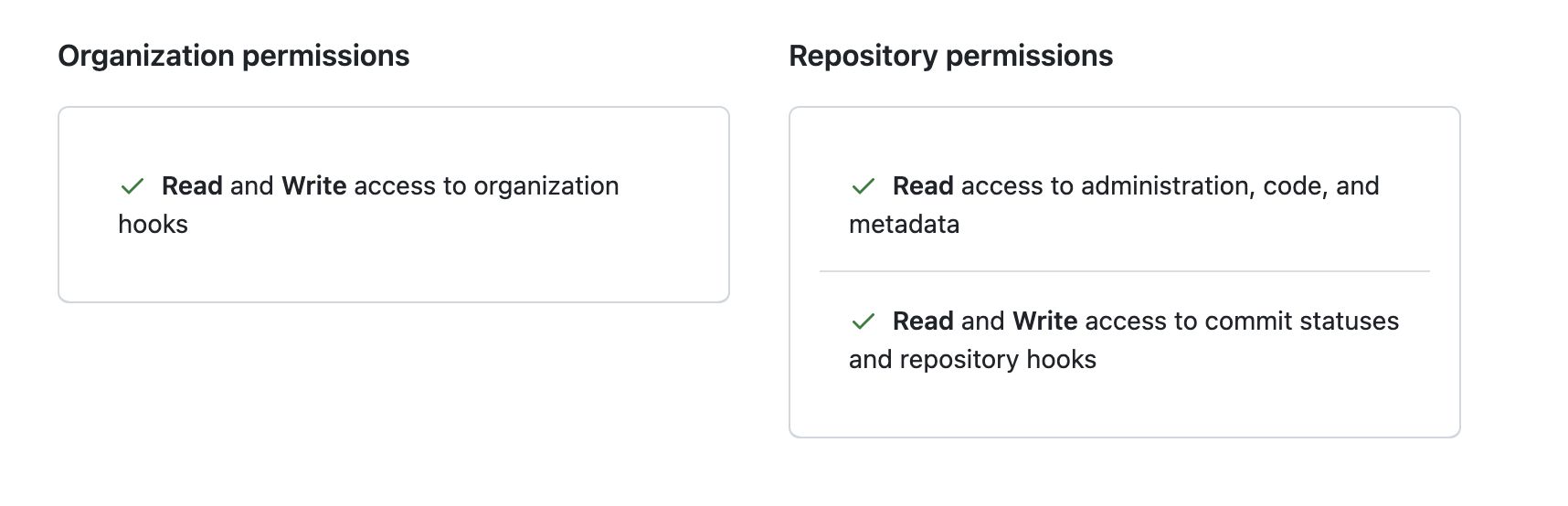
- creating a fine-grained Personal Acces Token (PAT) in GitHub. The PAT should be
scoped to yourself or your Organization, have access to the repository containing the Prophecy project, and
appropriate permissions:
- Choose Pipeline Script from SCM
- Provide the path to our Jenkinsfile within the repo
Refer to this image for all settings.
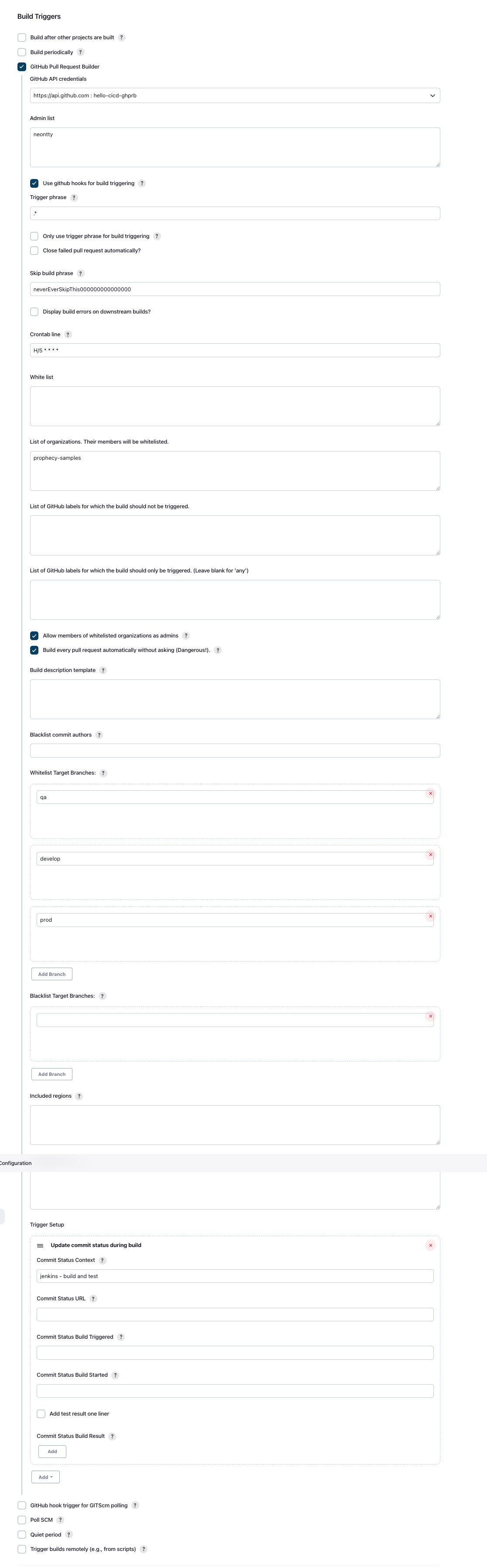
Testing Pipeline - Trigger
We use the GitHub Pull Request Builder to trigger any time there is a new pull request or a change
on a pull request (comment or new commit) to our special branches: develop, qa, prod.
By providing GitHub credentials to the GHPRB plugin it will be able to automatically create webhooks in GitHub.
Refer to this image for all settings.
Testing Pipeline - Pipeline Code
Create a Groovy Jenkinsfile in the project repository at the below location (relative to root)
.jenkins/deploy-declarative.groovy
Use the following code as a template, replacing the URLs as necessary:
pipeline {
agent any
environment {
PROJECT_PATH = "./hello_project"
VENV_NAME = ".venv"
}
stages {
stage('checkout') {
steps {
git branch: '${ghprbSourceBranch}', credentialsId: 'jenkins-cicd-runner-demo', url: 'git@github.com:prophecy-samples/external-cicd-template.git'
sh "apt-get install -y python3-venv"
}
}
stage('install pbt') {
steps {
sh """#!/bin/bash -xe
python3 --version
if [[ ! -d "$VENV_NAME" ]]; then
python3 -m venv $VENV_NAME
fi
source ./$VENV_NAME/bin/activate
python3 -m pip install -U pip
python3 -m pip install -U build pytest wheel pytest-html pyspark prophecy-build-tool
"""
}
}
stage('validate') {
steps {
sh """
. ./$VENV_NAME/bin/activate
python3 -m pbt validate --path $PROJECT_PATH
"""
}
}
stage('test') {
steps {
sh """
. ./$VENV_NAME/bin/activate
python3 -m pbt test --path $PROJECT_PATH
"""
}
}
}
}
Testing Pipeline - Explanation of Stages
The Pipeline performs the following actions in order:
- ('checkout') SCM checkout of the Prophecy project from Git
- Since we are using the GHRPB plugin to trigger this Pipeline, it will checkout the code
the source branch that triggered the PR with the special provided environment variable
${ghprbSourceBranch}.
- Since we are using the GHRPB plugin to trigger this Pipeline, it will checkout the code
the source branch that triggered the PR with the special provided environment variable
- ('install pbt') Install PBT and its dependencies to our Jenkins worker node
- ('valiadate') Use PBT to validate the Pipelines do not have any syntactical errors.
- ('test') Use PBT to run unit tests defined in the Prophecy Pipelines
Each invocation of sh in the Jenkins Pipeline runs in its own shell context. For this reason we
source the venv containing the pbt tool at the beginning of each sh command.
Deploy Pipeline
This Pipeline uses PBT to deploy the Prophecy Pipelines to their appropriate Fabrics.
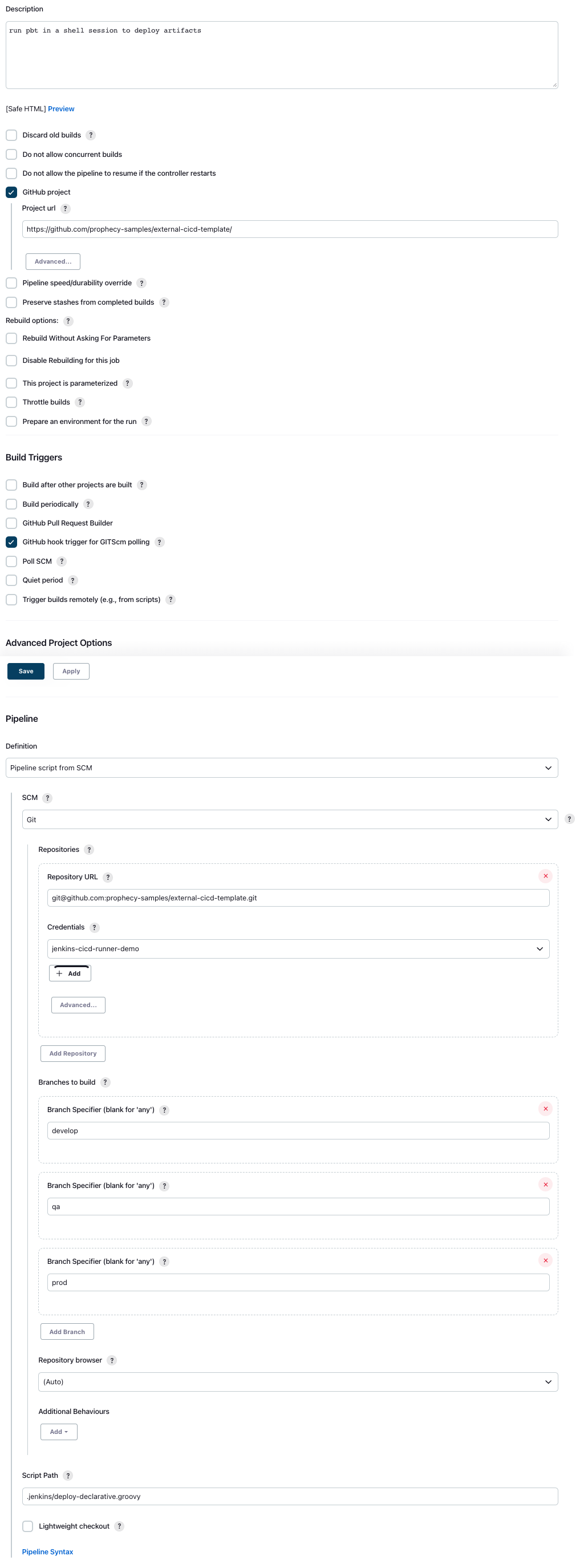
Deploy Pipeline - Pipeline Creation
- Create a Jenkins Pipeline
- Choose "GitHub hook for GITScm polling" as the trigger.
- Choose "Pipeline from SCM" with our GitHub repo as the repository
- Choose the branches to trigger on (
develop,qa,prod) - Point the "Script path" to our Jenkinsfile containing the deploy logic
Refer to this image for all settings.
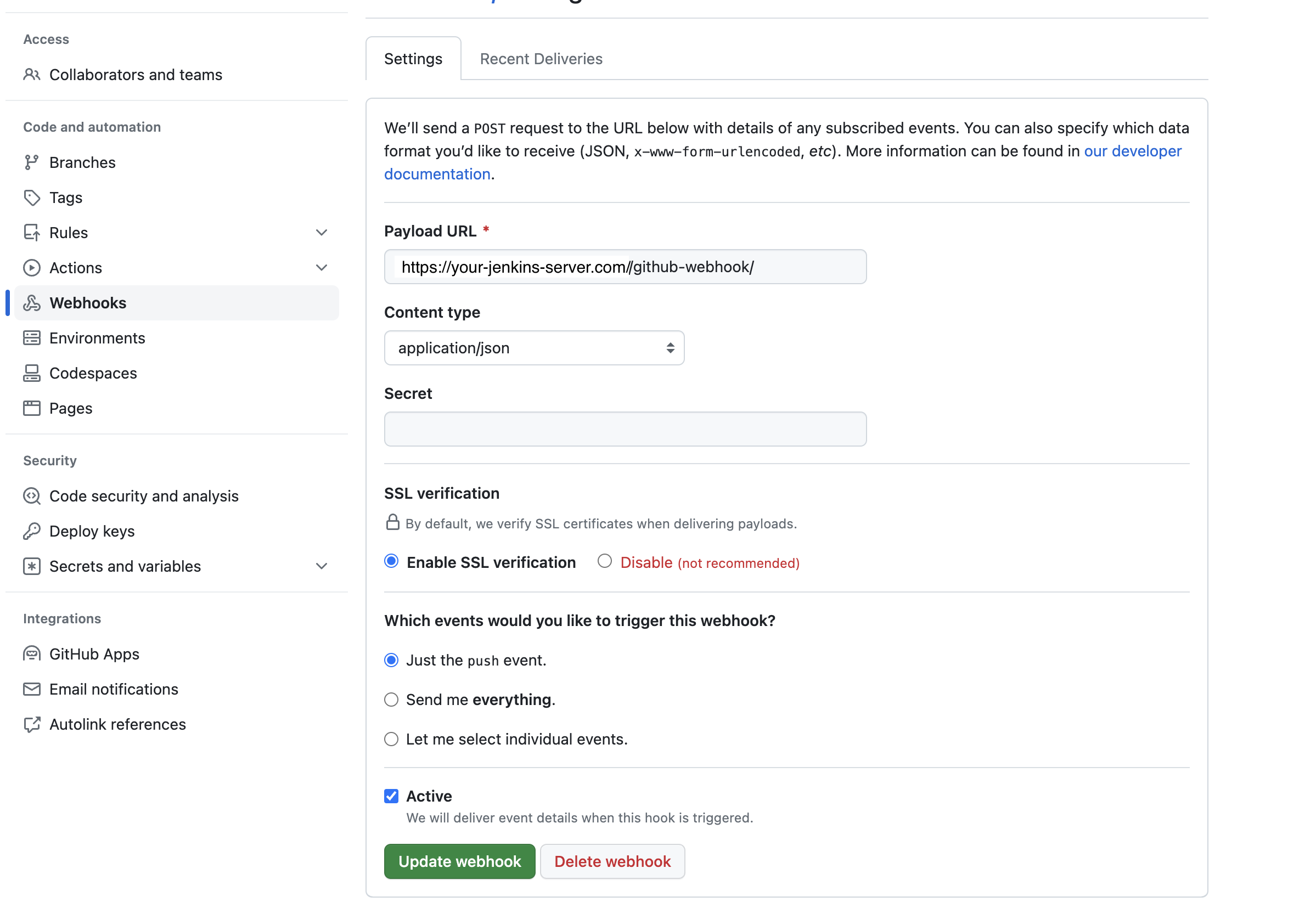
Deploy Pipeline - Trigger
Set up a simple webhook trigger for this Job inside of GitHub.
- Navigate to
Settings > Webhooks > Add Webhook - Create a new webhook like this:
Deploy Pipeline - Pipeline Code
Create a Groovy Jenkinsfile in the project repository at the below location (relative to root)
.jenkins/test-declarative.groovy
Use the following code as a template, replacing the Fabric IDs and URLs as necessary:
def DEFAULT_FABRIC = "1174"
def fabricPerBranch = [
prod: "4004",
qa: "4005",
develop: DEFAULT_FABRIC
]
pipeline {
agent any
environment {
DATABRICKS_HOST = credentials("${env.GIT_BRANCH == "prod" ? "DEMO_PROD_DATABRICKS_HOST" : "DEMO_DATABRICKS_HOST"}")
DATABRICKS_TOKEN = credentials("${env.GIT_BRANCH == "prod" ? "DEMO_PROD_DATABRICKS_TOKEN" : "DEMO_DATABRICKS_TOKEN"}")
PROJECT_PATH = "./hello_project"
VENV_NAME = ".venv"
FABRIC_ID = fabricPerBranch.getOrDefault("${env.GIT_BRANCH}", DEFAULT_FABRIC)
}
stages {
stage('prepare system') {
steps {
sh "apt-get install -y python3-venv"
}
}
stage('install pbt') {
steps {
sh """#!/bin/bash -xe
python3 --version
if [[ ! -d "$VENV_NAME" ]]; then
python3 -m venv $VENV_NAME
fi
source ./$VENV_NAME/bin/activate
python3 -m pip install -U pip
python3 -m pip install -U build pytest wheel pytest-html pyspark prophecy-build-tool
"""
}
}
stage('deploy') {
steps {
sh """
. ./$VENV_NAME/bin/activate
python3 -m pbt deploy --fabric-ids $FABRIC_ID --path $PROJECT_PATH
"""
}
}
}
}
Deploy Pipeline - Explanation of Pipeline
- ('environment' block) - Choose which Prophecy Fabric / Databricks Workspace to deploy jobs to.
The DATABRICKS_HOST and DATABRICKS_TOKEN env variables must match the configuration of the Fabric we are attempting to deploy.
- ('prepare system') - Ensure python3 is available on worker nodes. You can skip this if your Jenkins nodes already have
python3-venvinstalled. - ('install pbt') - Ensure PBT and its dependencies are installed
- ('deploy') - use PBT to deploy the Databricks jobs for our chosen Fabric
- Builds all the Pipelines present in the project and generates a .jar/.whl artifact for each Pipeline
- Uploads the Pipeline .jar/.whl artifacts for each of the deployed Jobs (next step)
- Creates or Updates the Databricks Jobs based on
databricks-job.jsonfiles for the Prophecy Project (only those that use$FABRIC_ID)