Secrets for Spark pipelines
Available only in Enterprise Edition.
A secret is sensitive information—such as an API key, password, or encryption key—that you want to use in a pipeline without exposing its value. A secret provider is a storage system that manages those secrets securely (for example, Databricks Secrets, HashiCorp Vault, or environment variables).
To leverage secrets and external secret providers in Prophecy, secrets must be stored in a fabric. This ensures that the compute attached to that fabric can access the secret at runtime while keeping the value hidden from users. By linking providers to fabrics, you can safely pass credentials and keys into Spark pipelines without hardcoding them.
Access control
Secrets belong to the fabric where they are created. Anyone with access to the fabric can reference them in projects.
- Users can use secrets in gems or configurations.
- Users cannot see the raw secret values.
Using secrets in pipelines
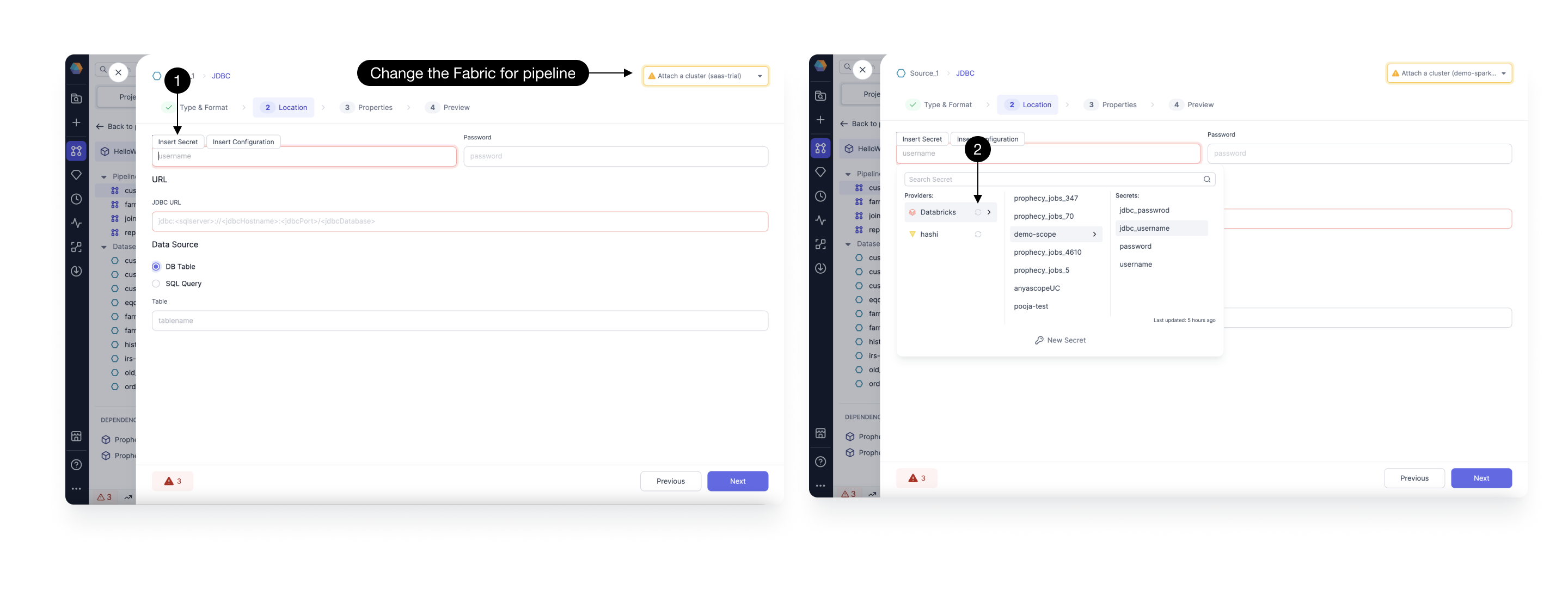
When a gem requires authentication fields (for example, username or password), you can insert a secret instead of entering plain text.
- Click Insert Secret in the gem field. A dropdown lists all secrets from the selected fabric.
- If a secret is missing, check the fabric selection (top-right corner).
- Attach a cluster to enable Refresh Secrets for the provider.
Typing credentials directly into fields triggers a warning diagnostic.
If you want to populate secrets dynamically in your pipeline, you can set up secrets in pipeline configurations.
Secret providers
Each fabric can be linked to one or more providers through the Providers tab. From Prophecy, you can add, edit, or remove both providers and secrets.
| Secret Provider | Details | Platform |
|---|---|---|
| Databricks Secrets | Recommended if you are a Databricks user | Databricks |
| HashiCorp Vault | Recommended if your organization privileges HashiCorp Vault | Any Spark |
| Environment Variables | Recommended if your organization privileges environment variables | Any Spark |
If your organization uses another system, you can fetch secrets by calling its API from a Script gem, which runs PySpark code.
Databricks
Databricks is the most commonly used secret provider in Prophecy. By default, a Databricks secret provider is added to all Databricks fabrics. You can remove this if required.
If you add new secrets in Databricks, you can refresh secrets in Prophecy to fetch them. You can also add new secrets directly in Prophecy. To refresh or add secrets, you must be attached to a cluster. You can only access secrets that you also can access in Databricks.
If you are using a free trial Databricks fabric, you can use Databricks as the secret provider. Your secrets will be automatically cleaned up after the trial expires. While Prophecy assigns a separate scope to each trial fabric, it is not recommended to use your production data tools for trials.
HashiCorp Vault
Prophecy supports HashiCorp Vault as a secret provider. When you set up HashiCorp Vault, you'll see a few additional configuration fields.
- Namespace: An optional field to specify the namespace within a multi-tenant Vault.
- Address: Auto-filled from Spark cluster. You must first set up a
VAULT_ADDRenvironment variable in the Spark cluster. - Token: Auto-filled from Spark cluster. You must first set up a
VAULT_TOKENenvironment variable in the Spark cluster.
If you add new secrets to your vault, you can refresh secrets in Prophecy to fetch them. You can also add new secrets directly in Prophecy. To refresh or add secrets, you must be attached to a cluster. You can only access secrets that you also have access to in your Spark cluster.
Environment variables
If you prefer a simple way to manage secrets, you can use environment variables available in your Spark cluster. To do so:
- Add a new secret provider and choose Environment.
- Add a new secret. Prophecy will automatically map this secret to an environment variable in your Spark cluster.
- Verify that the new environment variable exists in your Spark cluster with the correct value.
This method does not support refreshing or fetching secrets.