Pipeline development for Engineers
Available for Enterprise Edition only.
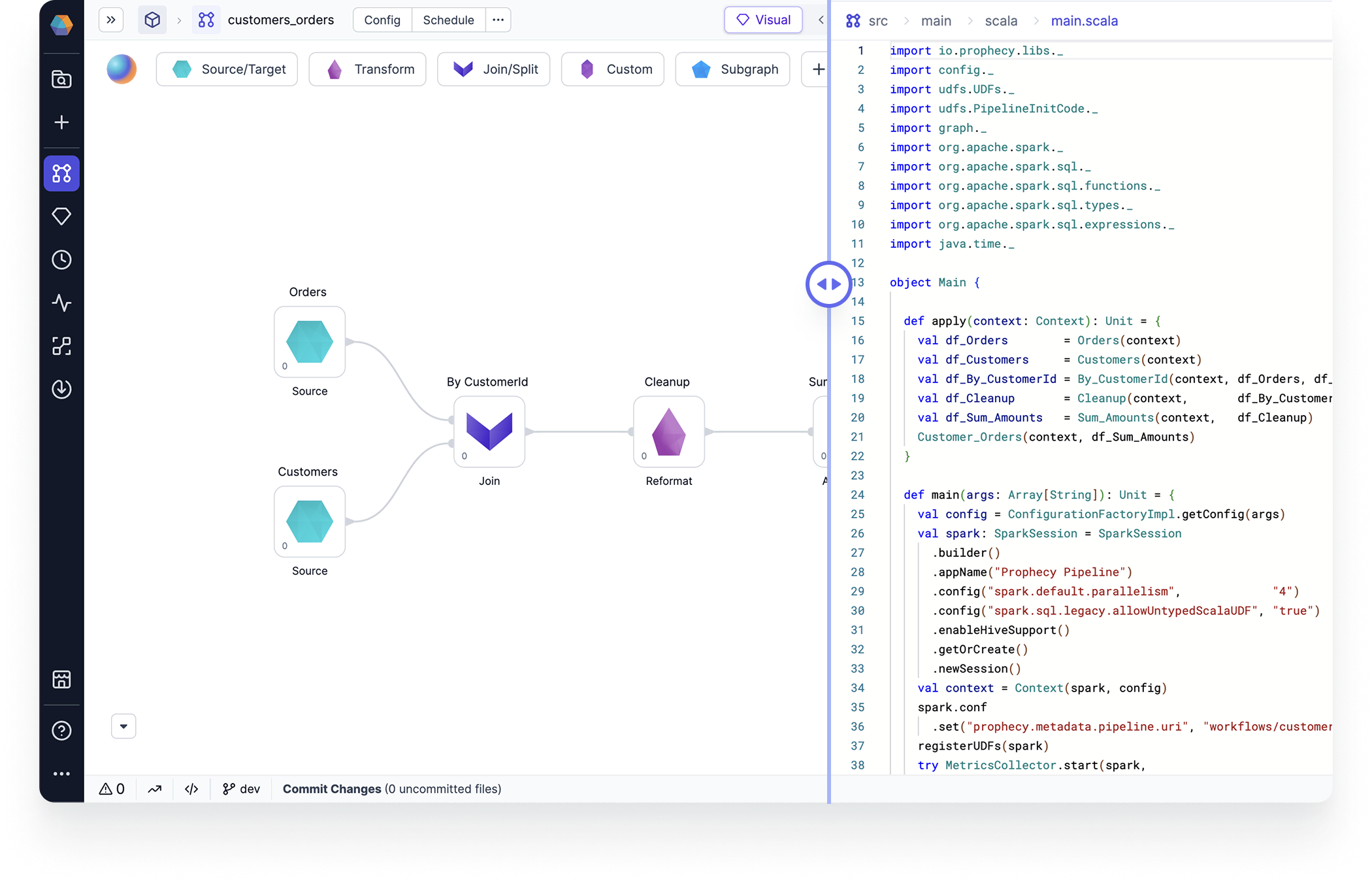
Pipeline development is foundational to data engineering. Prophecy simplifies the development of Spark-based data pipelines with a visual interface that automatically compiles pipelines into production-ready code.
Data transformations
Pipelines include a wide range of pre-built visual components that enable source/target operations, transformations, join/split operations, and machine learning capabilities. These components include datasets, gems, functions, and jobs.
Interactive development
Prophecy enhances Spark pipeline development with features like interim data sampling, which allows users to troubleshoot by visualizing the data flow, comparing historical runs, and inspecting individual datasets in the visual interface.
CI/CD
Prophecy supports CI/CD by managing all project version control on Git and providing control over how you release and deploy projects. This way, you can develop your pipelines in accordance with your Git workflows and other CI/CD tools.
Extensibility
In Prophecy, extensibility enables data practitioners to create and share pipeline components through the Package Hub, which allows teams to build reusable elements rather than rebuilding them for each project.
What's next
Learn more about pipeline development in the following pages.
Pipelines
3 items
Datasets
Use datasets in your Spark project
Gems
7 items
Copilot
Use Copilot to develop and explain your Spark pipelines
Execution
3 items
Data exploration
1 item
Functions
2 items
Spark streaming
2 items
Best practices
Learn about what we recommend to do if you are working in a project.