Databricks Jobs
Once you have developed a Spark pipeline using Prophecy, you will want to schedule it to run at some frequency. To support this, Prophecy provides a visual layer on top of Databricks jobs. A Prophecy Databricks job corresponds to a Databricks job definition under the hood, enabling you to add and link pipelines, scripts, Databricks notebooks, conditional logic, and other components to a job. Jobs run in Databricks.
Available for Enterprise Edition only.
Schedule a Databricks job
You can create a job either for a specific project or generically for any project.
-
To schedule a job for a specific project, either:
-
Click the Schedule button at the top of a pipeline's visual canvas, then click New Job in the dialog that opens. (You can still add other pipelines to the job.)
-
Click + to the right of Jobs in the left sidebar.
-
-
To schedule a job for any project, click the Create Entity button in the left navigation bar. Hover over the Job tile and select Create.
When you create a new job, you're asked for the following details. Some fields are automatically populated when you schedule from a pipeline or the left sidebar.
| Field Name | Description |
|---|---|
| Project | Which project to create the job in. This controls who has access to the job, groups jobs together for lineage, and allows you to use pipelines already published within that project. Populated automatically when you schedule a job from a pipeline or from within a project. |
| Branch | Which Git branch to use when developing this job. Populated automatically when you schedule a job from a pipeline. |
| Name | Unique name for job. |
| Scheduler | The underlying engine that will execute your job. Select Databricks. |
| Fabric | The execution fabric to which the job will be deployed. |
| Job Size | The default size of the cluster that will be created for the job. |
| Schedule Interval | Defines how often your job is going to run. The interval is defined using cron format. For example: 0 0/5 * * * ? means "runs every 5 minutes," while 0 0 12 * * ? means "runs daily at noon UTC." You can click on the clock icon to select the interval. |
| Description | Optional description of job. |
| Alerts email | Comma separated list of emails that are going to receive notifications on specific job status events (start, failure, or success). |
| Per Gem Timeout | Timeout for each gem in job pipeline. |
| Number of retries per gem | Number of retries for each gem in job pipeline. |
Build the job
Once you add a job, Prophecy opens a visual canvas that lets you add and connect gems for the job.
Seven gem types are available when defining Databricks jobs. Each gem represents a discrete task, such as running a pipeline, executing a notebook, or triggering another job.
| Gem Type | Purpose |
|---|---|
| Pipeline | Runs a Prophecy pipeline. Pipeline must be in the same project as the job. |
| Script | Runs a custom Python script. |
| Notebook | Runs a Databricks notebook. |
| If Else | Branches job execution conditionally. |
| RunJob | Runs another Prophecy job. |
| Model | Runs a dbt-style data project or a specific SQL model as part of a Databricks job. |
| Delta Live Tables | Runs a Databricks Delta Live Tables pipeline. |
Pipeline gem
The Pipeline gem triggers a Spark pipeline that was developed and published in Prophecy. Use this gem when you want to include an existing Prophecy pipeline as a stage within a Databricks job.
To add a pipeline gem:
-
Drag the Pipeline gem onto the job canvas and click it to open its settings.
-
Enter a descriptive name for the gem.
-
Select pipeline from dropdown menu.
-
Either confirm or configure Pipeline Configurations:
- To confirm, view input parameters in the Schema tab (visible by default when you open the gem).
Field Type Description input_path stringSource file path. processing_date stringDate to use for filtering. - To change configuration, click the Config tab. This tab allows you to override values in the Schema tab: input_path and processing_date.
You can apply conditions for the gem in the Conditions tab, including run conditions (whether or not this gem runs based on upstream gems' success or failure) and For Each (which lets you run the gem multiple times with different parameter values.)
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
Script gem
You can use the Script gem to add ad-hoc Python code to the job. This gem corresponds to a Databricks Python script task, which is a .py file that executes within the Databricks runtime on the cluster associated with the job.
To add a Script gem:
- Drag the Script gem onto the job canvas and click it to open its settings.
- Enter a descriptive name for the gem.
- Enter the Python code you want to execute.
You can apply conditions for the gem in the Conditions tab, including run conditions (whether or not this gem runs based on upstream gems' success or failure) and For Each (which lets you run the gem multiple times with different parameter values.)
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
Notebook gem
The Notebook gem lets you include Databricks notebooks as part of a Prophecy job.
Use this gem when you want to orchestrate a notebook that already exists in Databricks as one stage within your job.
To add a Notebook gem:
- Drag the Notebook gem onto the job canvas and click it to open its settings.
- Enter notebook path for the Databricks notebook you want to run.
- The path must reference a notebook that already exists in Databricks.
- Ensure that the user running the job has Databricks permissions to access this path.
Prophecy does not support creating or editing notebooks directly in Prophecy.
All notebooks must be created and maintained within Databricks.
You can apply conditions for the gem in the Conditions tab, including run conditions (whether or not this gem runs based on upstream gems' success or failure) and For Each (which lets you run the gem multiple times with different parameter values.)
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
If Else gem
The If Else gem lets you branch a job’s execution path based on a logical condition.
Use this gem when you want the job to continue along one branch if a condition is met, and along another branch if it is not.
To add an If Else gem:
- Drag the If Else gem onto the job canvas and click it to open its settings.
- Enter a left operand, operator, and right operand to create a logical comparison.
- Supported operators:
- equals
- not equals
- less than
- greater than
- less than or equal to
- greater than or equal to
- Supported operators:
Branch behavior
- If the condition evaluates to true, the job continues along the upper branch.
- If the condition evaluates to false, the job continues along the lower branch.
You can apply run conditions for the gem in the Conditions tab. These whether or not the gem runs based on upstream gems' success or failure.
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab. Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
RunJob gem
The RunJob gem lets you trigger another job that has been configured in your workspace.
Use this gem to chain jobs together or orchestrate dependent workflows as part of a larger process.
To add a RunJob gem:
- Drag the RunJob gem onto the job canvas and click it to open its settings.
- Choose a job from the dropdown menu, or manually enter the Job ID of the job you want to trigger.
- (Optional) Check Wait for job completion before proceeding if you want the current job to pause until the triggered job finishes running.
You can apply conditions for the gem in the Conditions tab, including run conditions (whether or not this gem runs based on upstream gems' success or failure) and For Each (which lets you run the gem multiple times with different parameter values.)
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
Model gem
The Model gem lets you run either an entire Prophecy (dbt-style) project or a specific SQL model within one. Use it when you want to include data modeling or transformation logic as part of a Databricks job.
You can configure the Model Gem in two modes:
Run Entire Project
Use this mode to execute all SQL models, tests, and seeds within a selected project.
| Field | Description |
|---|---|
| Project | Select the project to run. |
| Fabric | Select the execution fabric where the project should run. |
| Git Target | Choose the Git target (branch or tag). |
| Reference Value | Specify the reference commit or version to use. |
Run a SQL model
Use this mode when you want to run a single SQL model from within a project.
| Field | Description |
|---|---|
| Project | Select the project containing the SQL model. |
| SQL Model | Select the SQL model to run. |
| Fabric | Select the execution fabric where the SQL model should run. |
| Git Target | Choose the Git target (branch or tag). |
| Reference Value | Specify the reference commit or version to use. |
DBT properties
These options control dbt-style behavior when running a project or SQL model:
| Property | Description |
|---|---|
| Run tests | Runs dbt tests (dbt test) after the model executes. |
| Run seeds | Runs dbt seeds (dbt seed) before model execution. |
| Pull most recent version of dependencies | Refreshes dbt dependencies (dbt deps) before execution. |
| Compile and execute against current target (run) | Compiles and executes the selected models (dbt run) against the current target. |
Note: The Model Gem refers to data models (SQL/dbt) rather than machine learning models. It lets you compile and run Prophecy or dbt projects as part of a Databricks job orchestration.
You can apply conditions for the gem in the Conditions tab, including run conditions (whether or not this gem runs based on upstream gems' success or failure) and For Each (which lets you run the gem multiple times with different parameter values.)
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
Delta Live Tables Pipeline gem
The Delta Live Tables Pipeline gem lets you run data pipelines that have already been created and deployed in Databricks. Use this gem when you want to orchestrate an existing Delta Live Tables (DLT) pipeline as part of a Prophecy job.
To add a Delta Live Tables Pipeline gem:
- Drag the Delta Live Tables Pipeline gem onto the job canvas and click it to open its settings.
- Choose from available DLT pipelines for the current fabric.
- (Optional) Enable the Trigger full refresh checkbox to force a full refresh when the pipeline runs.
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
You can apply conditions for the gem in the Conditions tab, including run conditions (whether or not this gem runs based on upstream gems' success or failure) and For Each (which lets you run the gem multiple times with different parameter values.)
Settings for the gem can be inherited from overall job configuration or can be set in the Settings tab.
Apply conditions to gems in the Conditions tab
Use the Conditional tab to control when and how the gem runs within the job. You can define run conditions or configure the gem to run multiple iterations with For Each.
Apply Run conditions
Run conditions determine when the gem executes based on the status of preceding gems.
- All succeeded – Runs if all upstream gems succeed.
- At least one succeeded – Runs if at least one upstream gem succeeds.
- None failed – Runs if all upstream gems complete without failure.
- All done – Runs after all upstream gems finish, regardless of success or failure.
- At least one failed – Runs if at least one upstream gem fails.
Use For Each
Use For Each to run the gem multiple times with different parameter values. You can use For Each for all job gems except for the If Else gem.
- Click Run multiple iterations [For Each].
- Enter a parameter name and a variable name to define the iteration context.
- Set the number of concurrent runs to control parallel execution.
Run the job
When you are satisfied with the job's configuration, you can run it interactively to test it on demand. This lets you validate that the job works correctly before you deploy it.
- Make sure you are connected to a fabric.
- Click the run button in the lower right-hand corner of the job configuration page.
If the job fails, Prophecy displays an error message indicating what went wrong. If the job succeeds, Prophecy displays a page indicating that all stages have succeeded.
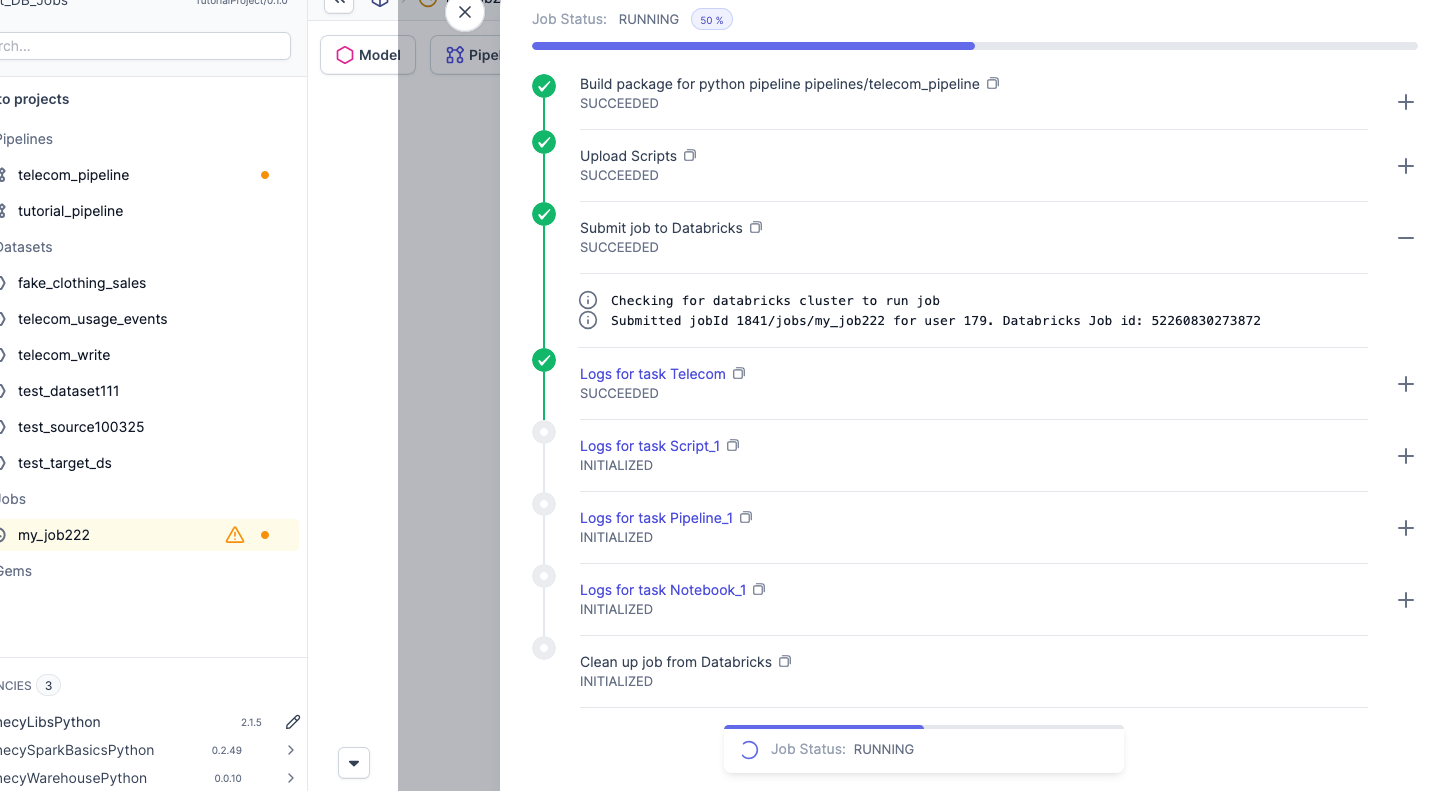
While the job runs, Prophecy displays a Job Status: Running message with a Detail button. To view a job's progress, click the Detail button. A dialog opens showing the job as a series of stages. You can view details on a stage by clicking + to the right of the stage. If the job fails, Prophecy displays an error message for the stage at which the job failed.
Configure clusters for job gems
By default, all Jobs gems run in the same cluster. You can configure clusters for individual gems. This option is especially useful for heavy-duty and production pipelines.
To do so:
-
Select the gem by clicking its border.
-
Click Configure a Cluster.
-
Once the cluster is created, select cluster from dropdown menu.
-
Choose Multi at the top of the visual canvas.
When the job runs, each gem runs in its own independent cluster. All clusters are the same size as the cluster selected for the job.
Deploy job
In order to deploy the job on Databricks, you need to release and deploy the job from Prophecy. See Deployment for more details.
To release and deploy the job:
- Click Enable in the upper right corner of the visual canvas.
- Click Release in the upper right corner of the visual canvas.
- In the dialog that opens, follow the steps to create a git tag for the version, commiting, pulling, and merging changes.
- On the Release and Deploy page of the dialog, assign the job a Release Version (such as
0.3.0), and click Release and Deploy.
The job will now be active in Databricks jobs and the schedule will run.
Make sure to enable the job before creating a Release. If not enabled, the job will not run.
If a job's selected fabric is changed, it will create a separate Databricks job definition. The previous job (with the previous fabric) will be paused automatically and the new version will be scheduled.