SQLStatement gem
The SQLStatement gem enables you to execute custom SQL queries against input DataFrames and generate one or more output DataFrames. Use this gem when you need to execute complex SQL queries that are difficult to express using native gems or want to leverage existing SQL knowledge and queries in your data pipelines.
Behavior in Databricks
When running pipelines on Databricks, the SQLStatement gem's behavior may vary depending on your Databricks cluster configuration. The underlying Spark execution engine differs between cluster types, which can affect how SQL queries are processed and executed.
- UC dedicated clusters (formerly single user): Uses Spark Classic execution engine
- UC standard clusters (formerly shared): Uses Spark Connect execution engine
One notable difference involves createOrReplaceTempView operations. In Spark Classic, temporary views referenced in spark.sql are resolved immediately, while in Spark Connect they are lazily analyzed. This means that in Spark Connect environments, if a view is dropped, modified, or replaced after the spark.sql call, execution may fail or generate different results.
Always test your SQL queries on your target cluster type to ensure they behave as expected.
To learn more about how Databricks clusters impact Prophecy development, see Feature compatibility with UC clusters.
Parameters
| Parameter | Meaning | Required |
|---|---|---|
| DataFrame(s) | Input DataFrame(s) | True |
| SQL Queries | SQL Query for each output tab | True |
Number of inputs and outputs can be changed as needed by clicking the + button on the respective tab.
Example: SELECT statement
The following screenshot shows an example SQLStatement gem that includes two queries generating two outputs.
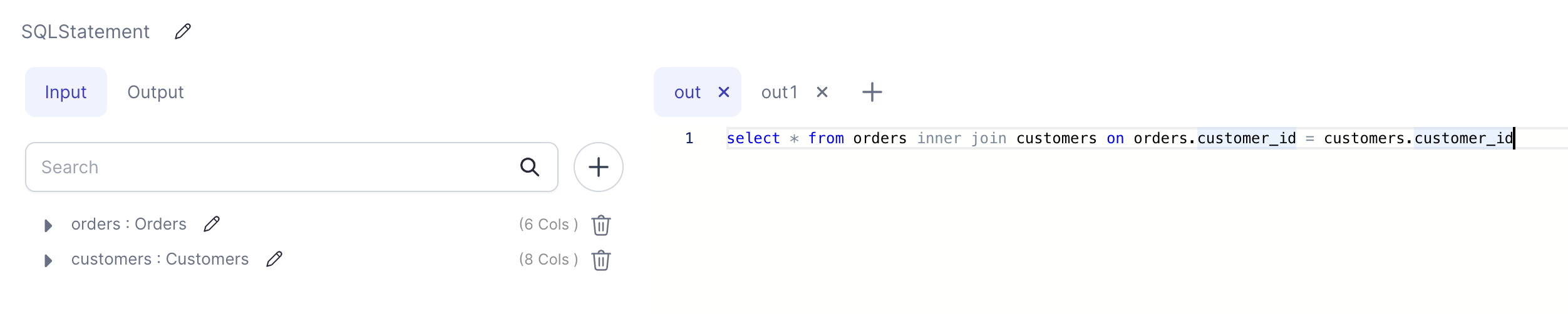
Generated Code
- Python
- Scala
def SQLStatement(spark: SparkSession, orders: DataFrame, customers: DataFrame) -> (DataFrame, DataFrame):
orders.createOrReplaceTempView("orders")
customers.createOrReplaceTempView("customers")
df1 = spark.sql("select * from orders inner join customers on orders.customer_id = customers.customer_id")
df2 = spark.sql("select distinct customer_id from orders")
return df1, df2
object SQLStatement {
def apply(
spark: SparkSession,
orders: DataFrame,
customers: DataFrame
): (DataFrame, DataFrame) = {
orders.createOrReplaceTempView("orders")
customers.createOrReplaceTempView("customers")
(
spark.sql(
"""select * from orders inner join customers on orders.customer_id = customers.customer_id"""
),
spark.sql(
"""select distinct customer_id from orders"""
)
)
}
}