March 2023
2.10.0.* (Mar 31, 2023)
- Prophecy Python libs version: 1.4.8
- Prophecy Scala libs version: 7.0.16
Improvements
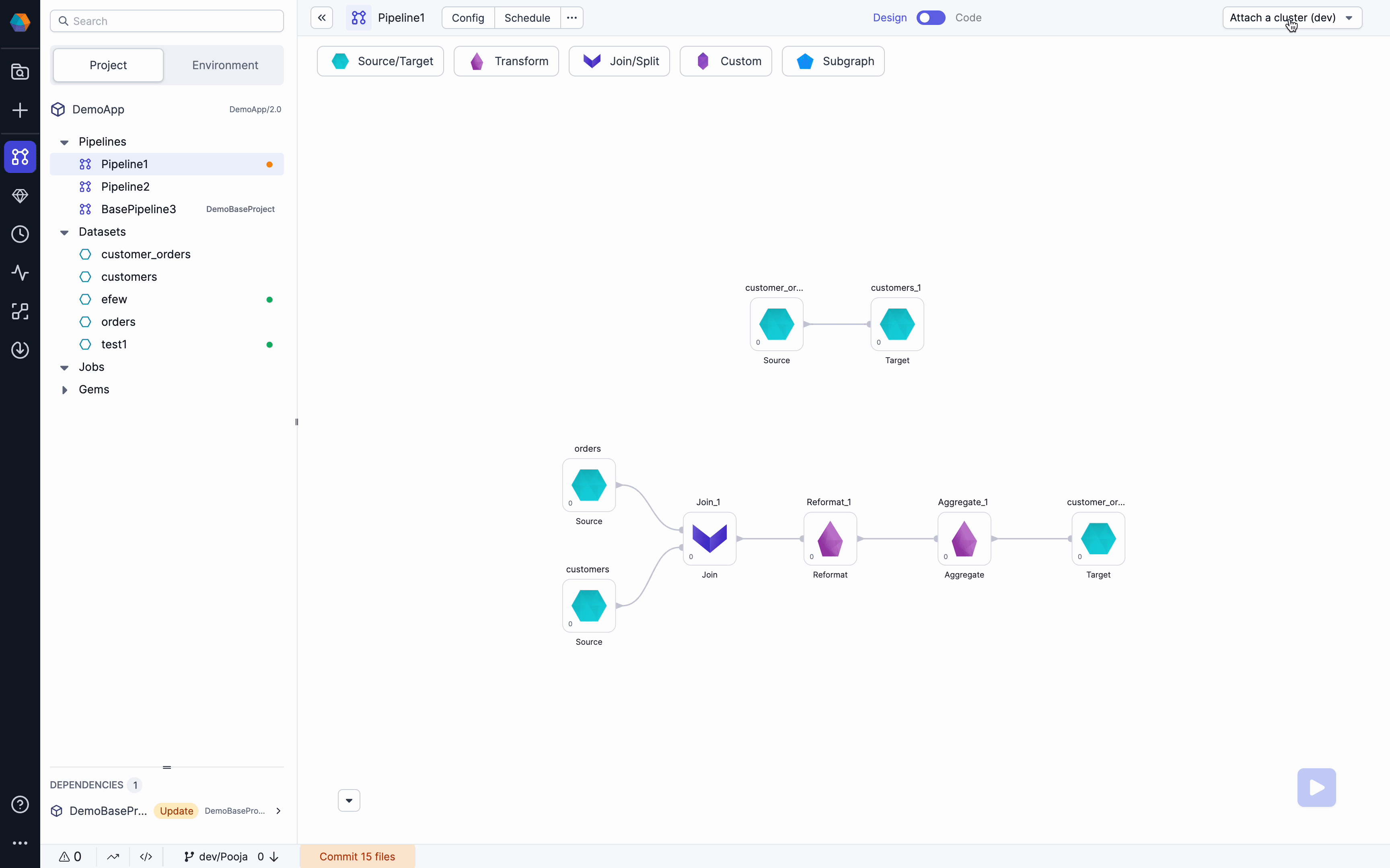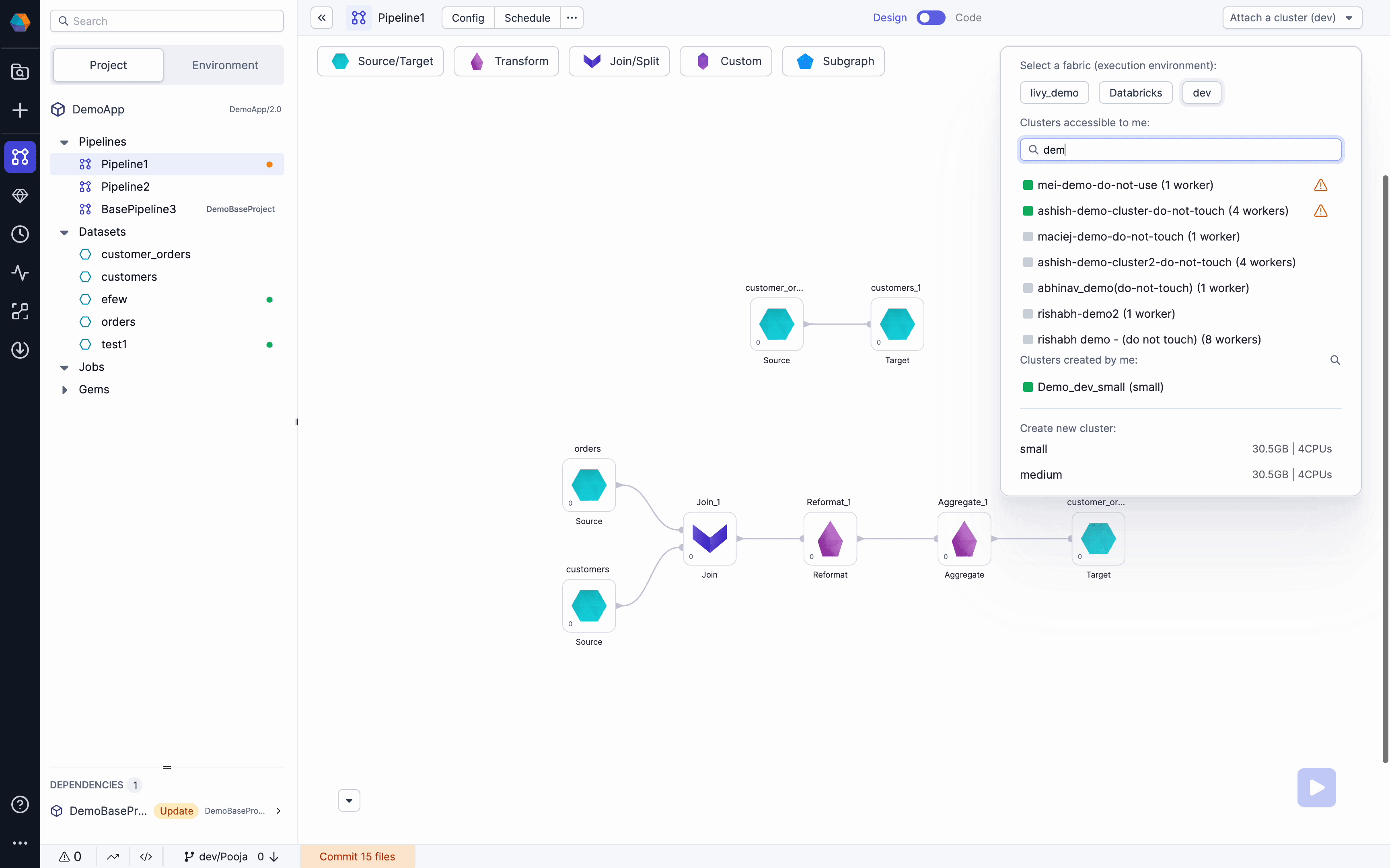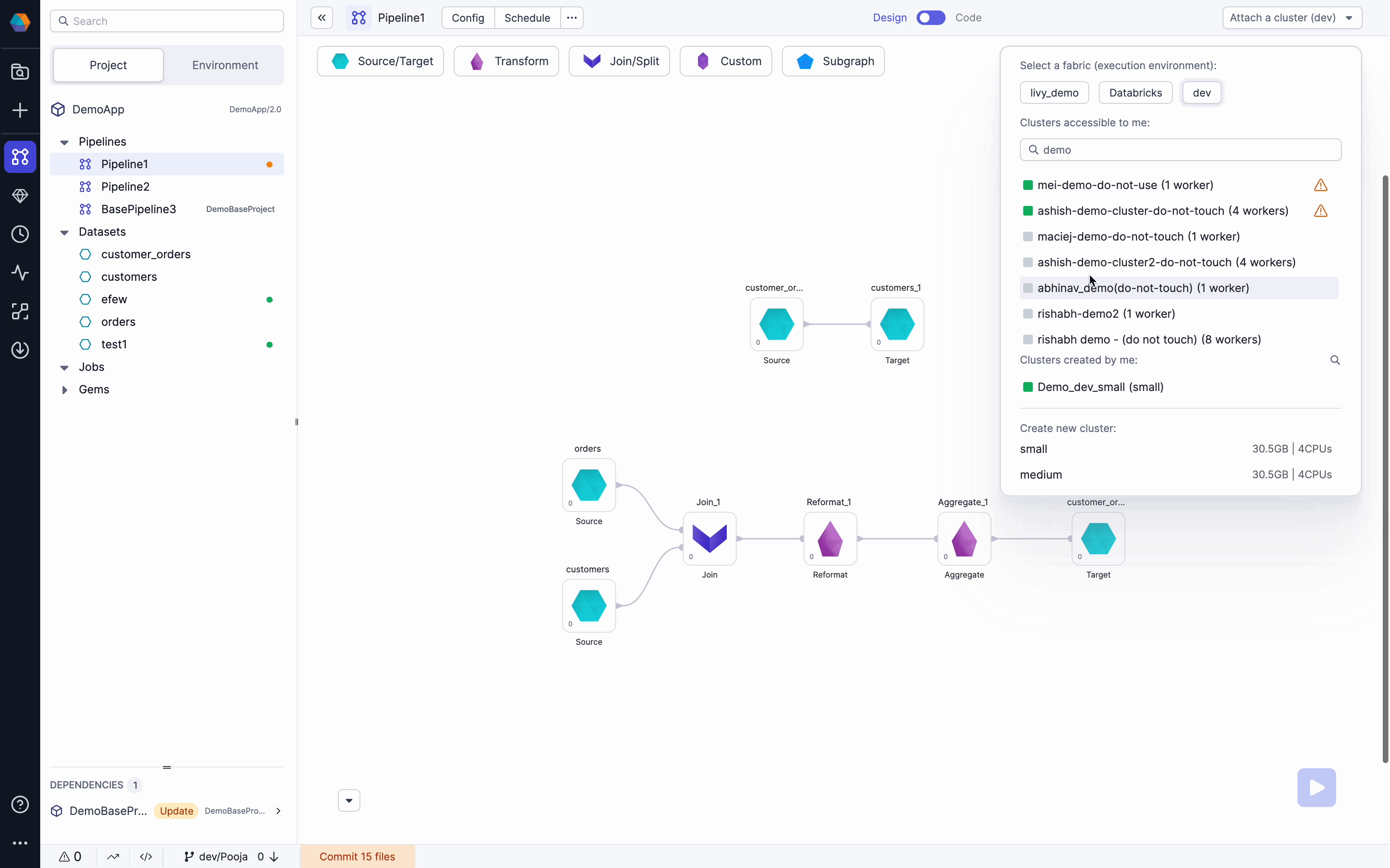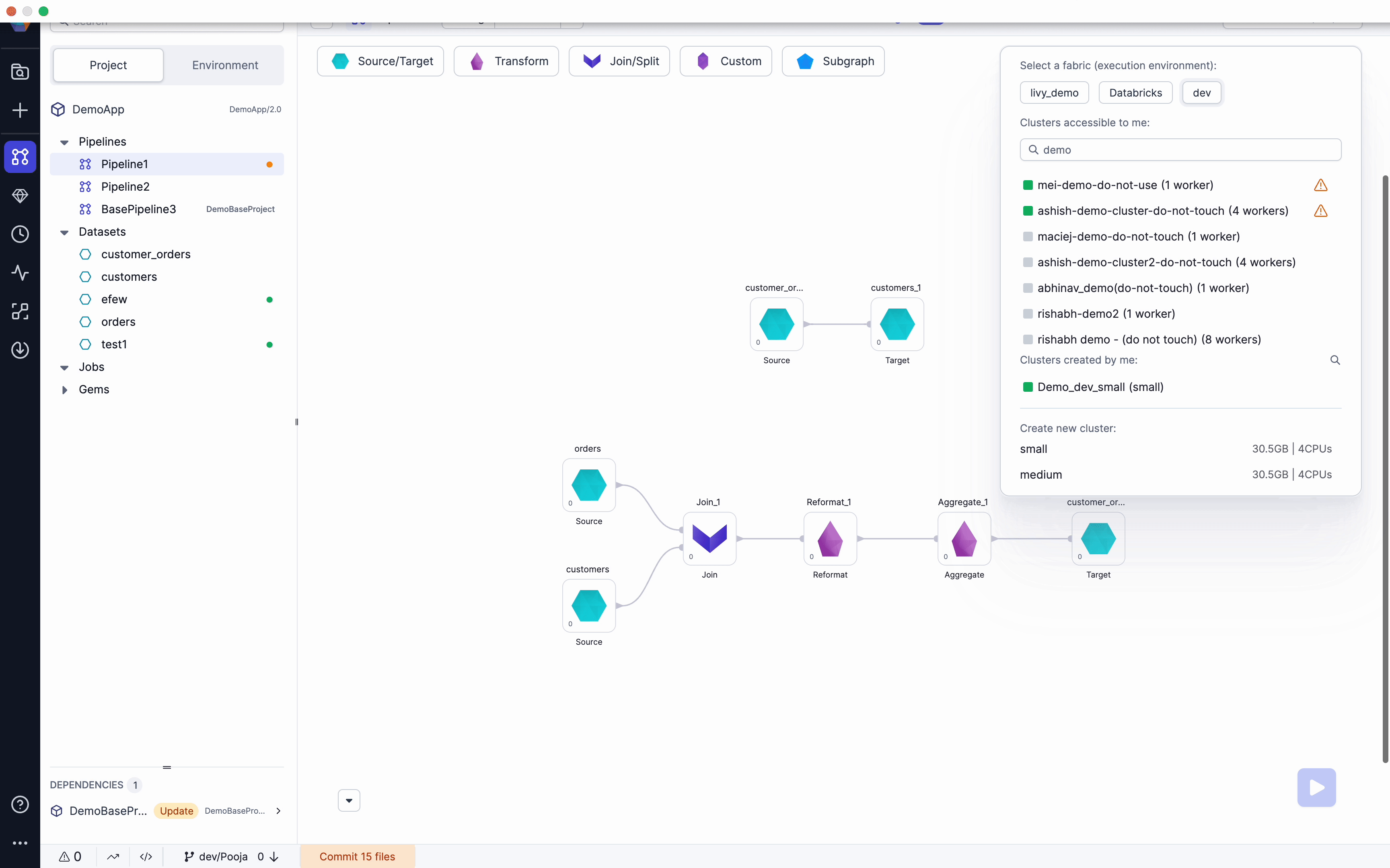
Search box on available clusters
Find clusters faster with cluster search
Performance Improvements for Projects with large Number of Entities
With this release, we have optimized the Project Browser to handle Projects with more than 500 pipelines/datasets. User should not see delays and should be able to seamlessly browse Entities in large Projects.
Datasets improvements
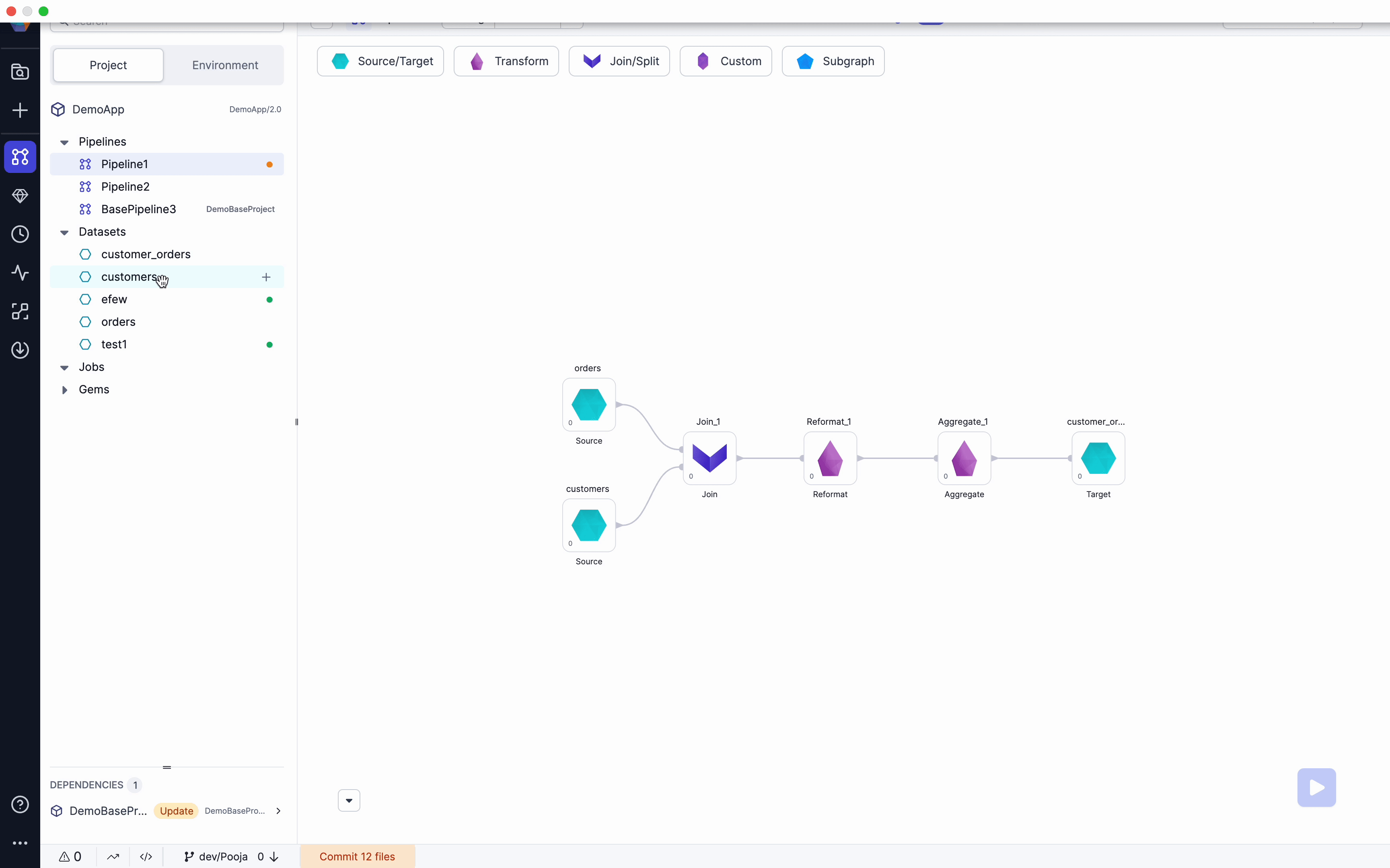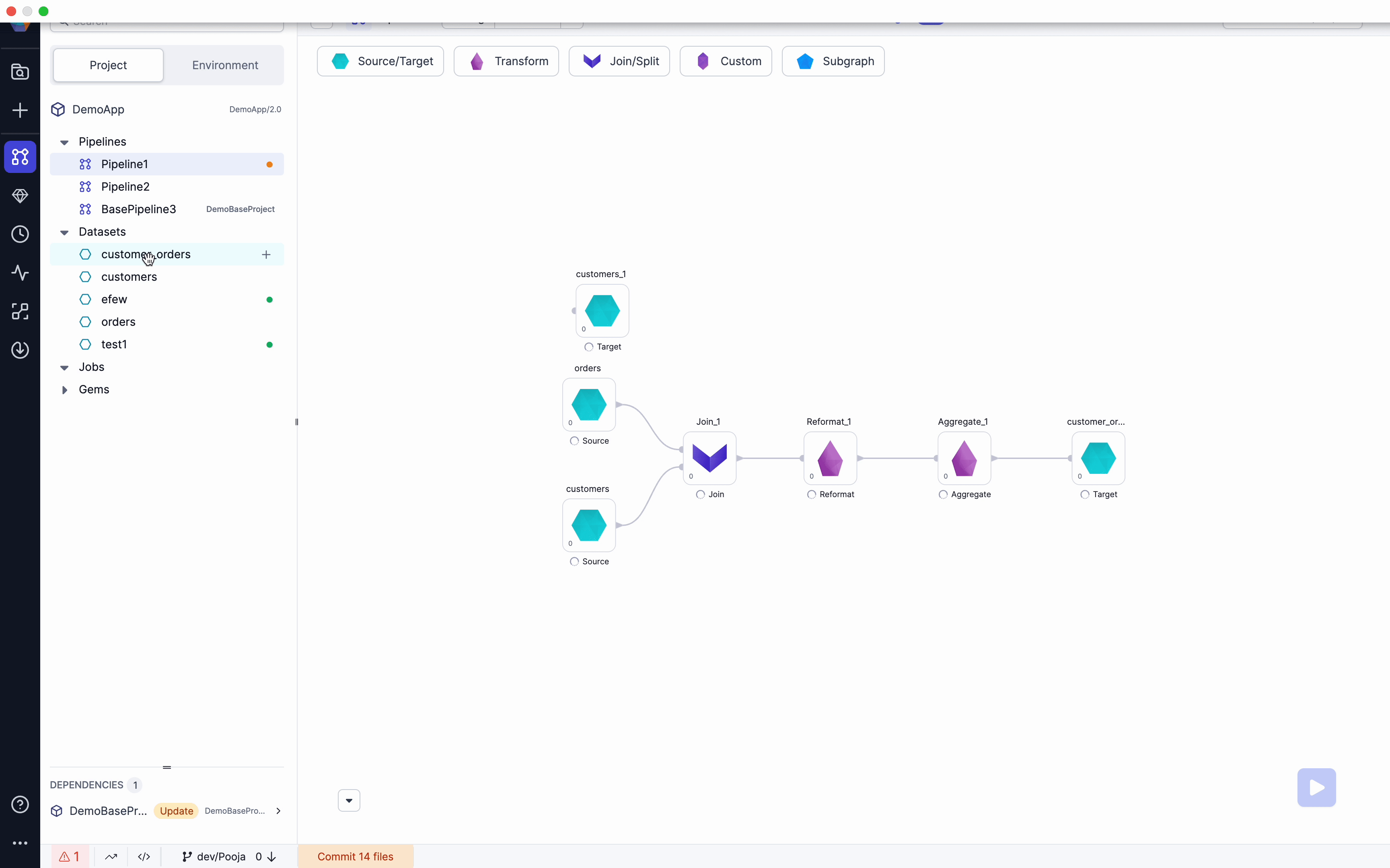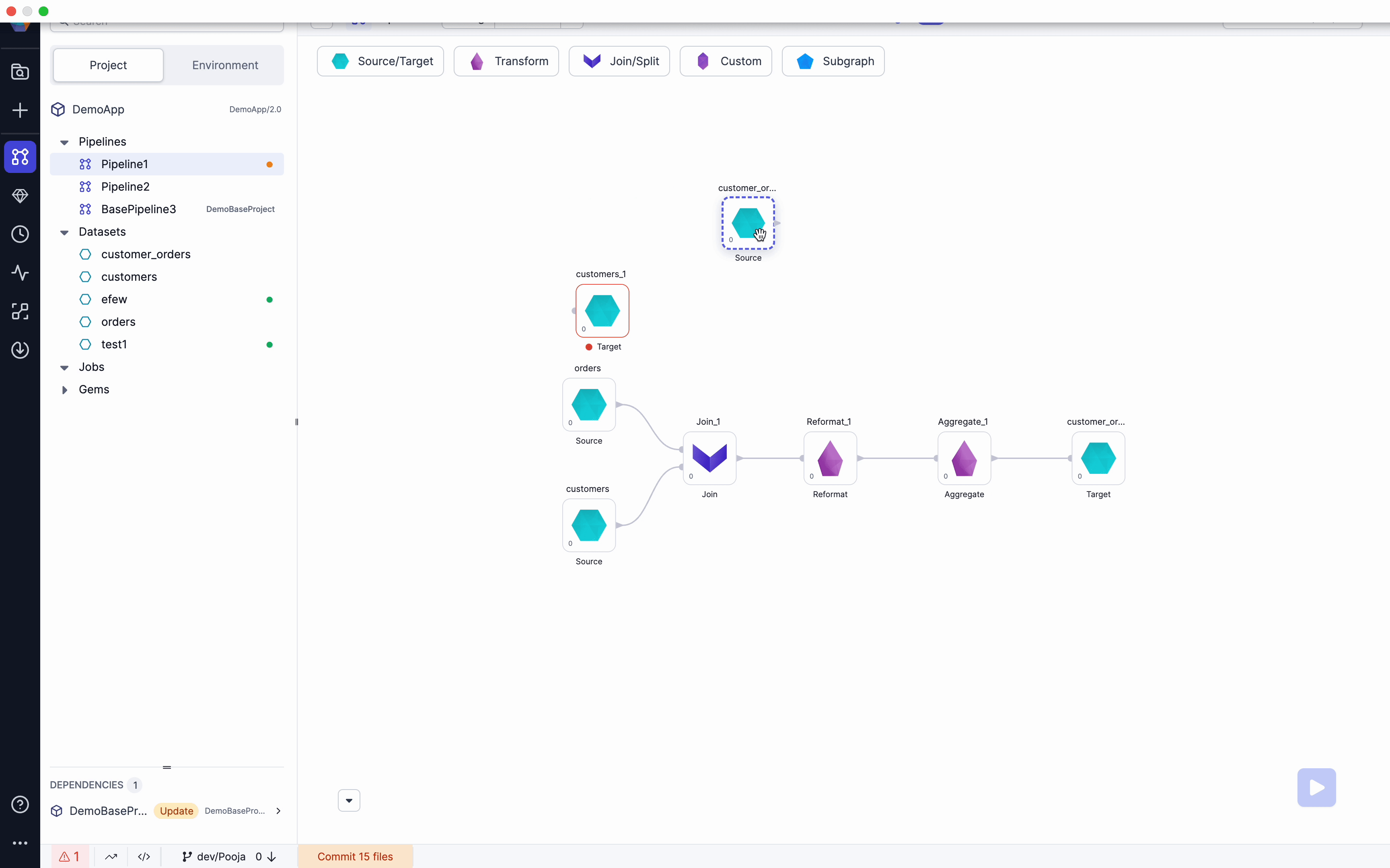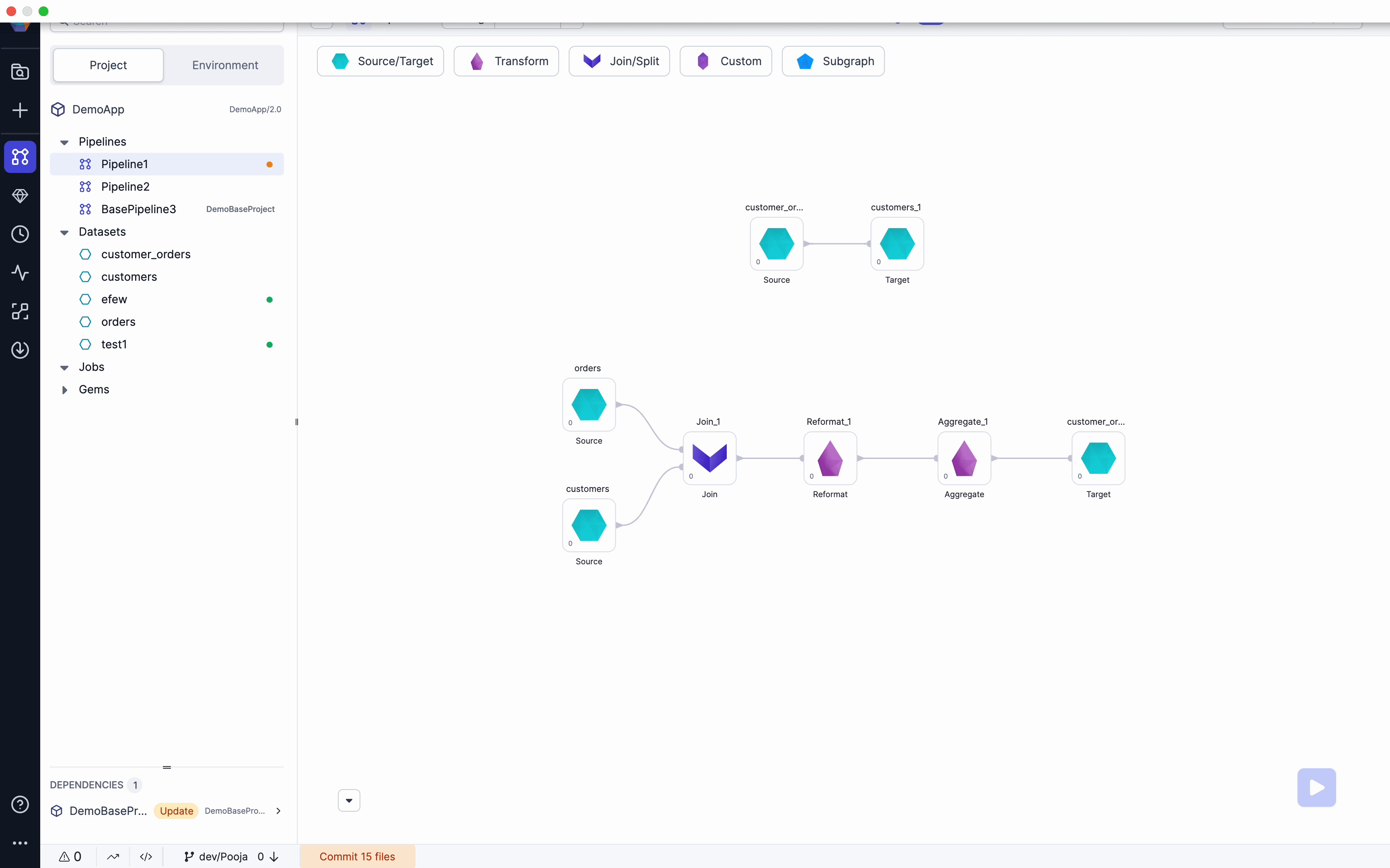
We have removed Restrictions to allow users to be able to save datasets with Diagnostics errors like missing Input ports/Schema etc. Along with this we have also added ability to Choose Source/Target while adding a Dataset to pipeline from browser. Please see below video for example.
Warning when deleting Teams
Users will now see Warnings as shown below before deleting Teams etc. Similar warnings are shown while deleting a Project or fabric too.
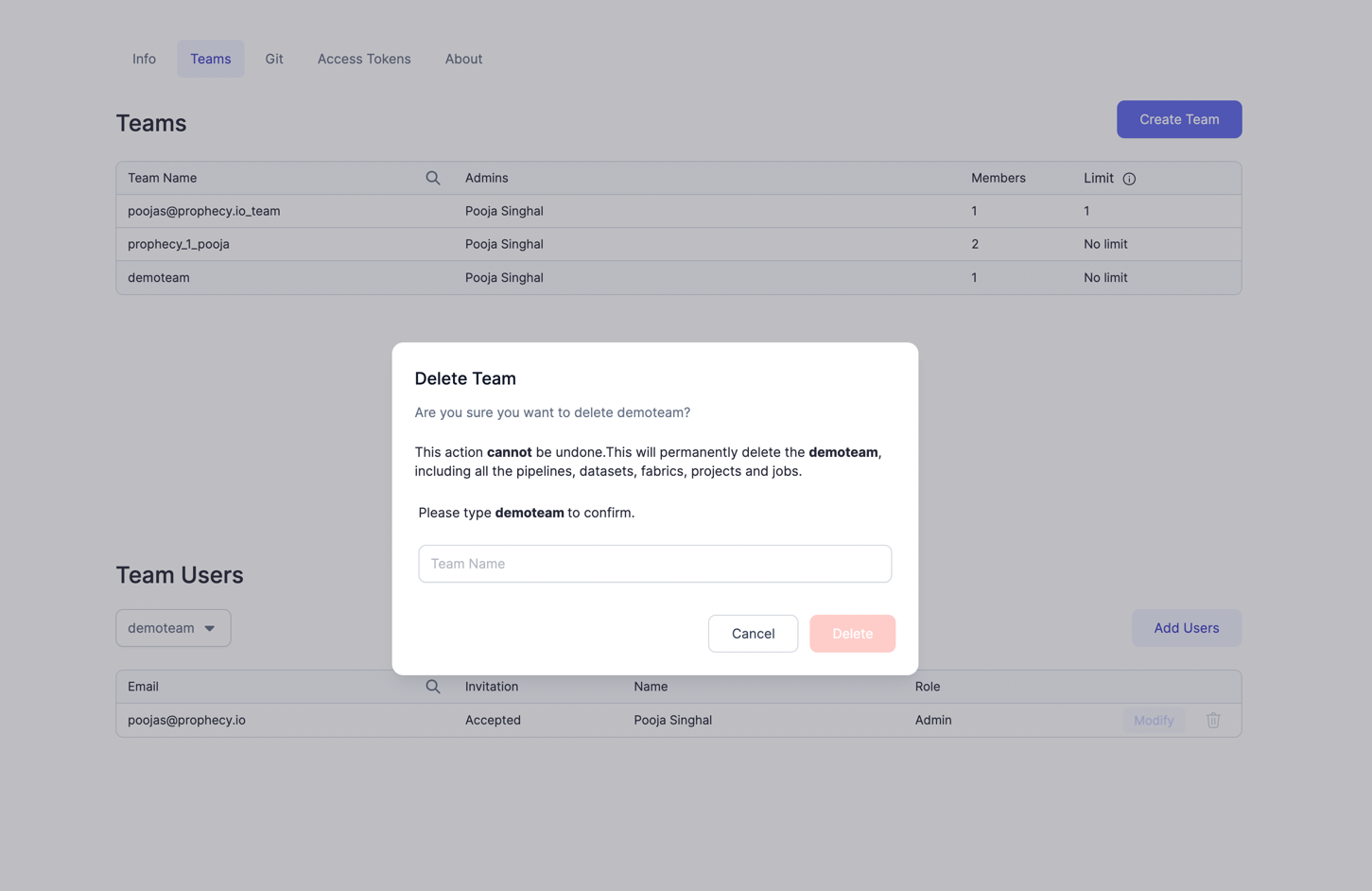
Deleting a Team, deletes all the projects, pipelines, datasets, jobs, fabrics owned by that team.
2.9.0.* (Mar 24, 2023)
- Prophecy Python libs version: 1.4.7
- Prophecy Scala libs version: 7.0.10
Features
Sharable Subgraphs and UDFs
One of the best practices during Data-Project development is to Use standardized components. Prophecy enables this standardization in a few ways:
- Our standard gems
- User-Defined Functions
- Reusable Subgraphs
- Custom gems
With this release, Subgraphs and User-Defined Functions can now be shared across multiple projects and teams. This allows central Data Platform teams to build reusable code to cover a wide variety of business needs, such as Encryption/Decryption or Identity Masking, and have their "consumers" (the Data Practitioners) take a dependency on that reusable code. Since it's all versioned, when the reusable code changes, the downstream consumers will be notified and can update accordingly.
Data admins can also Create deployment templates for the pipelines that have the best practices baked into them for authorization, notifications, handling of errors, and logging the correct information.
Please note, Users will see new Uncommitted changes in their pipelines when they open it. They can see UDF code being added to all pipelines, Configs added to Subgraphs, etc.
Please see here for more details on this Feature.
Ability to commit and Release from the pipeline page
A user can complete the entire CI-CD process from commit to release from the pipeline editor. Please see the below video for an example.
Improvements
Ability to rename a cluster while attaching
When attaching to a cluster, User can now provide a custom name to the cluster (if creating a new cluster), to be able to identify it in the future again. Please see the below video for an example.
Checkout remote branches
Users can now check out branches created directly in Git(outside of Prophecy) for editing. On the checkout screen, users will now see a list of remote and local branches separately. Once checked out, the branch will be shown as a local branch. Please see the below video for an example.
Open Project lineage view
When clicking Open Project from a Project page, Users will now see a Birds-eye view of their entire Project. They will have shortcuts to edit pipelines and access all Metadata from this screen. Please see the below video for an example.
Cluster auto-attach behavior
For Configured pipelines (Read-Only mode from Dependencies) in pipeline view, Cluster will auto-attach to the last-used cluster from the fabric. This behavior is now consistent for all pipelines in Edit/Read-Only mode.
Please see the below video for an example.
Control Data Sampling behavior for Configured Pipelines
A User can now change the Data Sampling Interims for Interactive Runs of Configured pipelines(Read-Only mode from Dependencies). Please see the below video for an example.