ORC
ProphecySparkBasicsPython 0.0.1+ProphecySparkBasicsScala 0.0.1+UC Dedicated Cluster 14.3+UC Standard Cluster 14.3+Livy 3.2.0+
The ORC (Optimized Row Columnar) file type:
- Is a columnar file format designed for Spark and Hadoop workloads.
- Offers high compression ratios, which helps reduce storage costs.
- Optimizes for large streaming reads, but with integrated support for finding required rows quickly.
- Is type-aware, which means it can choose an encoding for the type and builds an internal index while you write to the file.
Parameters
| Parameter | Tab | Description |
|---|---|---|
| Location | Location | File path to read from or write to the ORC file. |
| Schema | Properties | Schema to apply on the loaded data. In the Source gem, you can define or edit the schema visually or in JSON code. In the Target gem, you can view the schema visually or as JSON code. |
Source
The Source gem reads data from ORC files and allows you to optionally specify the following additional properties.
Source properties
| Property name | Description | Default |
|---|---|---|
| Description | Description of your dataset. | None |
| Use user-defined schema | Whether to use the schema you define. | false |
| Recursive File Lookup | Whether to recursively load files and disable partition inferring. If the data source explicitly specifies the partitionSpec when therecursiveFileLookup is true, the Source gem throws an exception. | false |
Example
Compiled code
tip
To see the compiled code of your project, switch to the Code view in the project header.
- Python
- Scala
def read_orc(spark: SparkSession) -> DataFrame:
return spark.read\
.format("orc")\
.load("dbfs:/FileStore/Users/orc/test.orc")
object read_orc {
def apply(spark: SparkSession): DataFrame =
spark.read
.format("orc")
.load("dbfs:/FileStore/Users/orc/test.orc")
}
Target
The Target gem writes data to ORC files and allows you to optionally specify the following additional properties.
Target properties
| Property name | Description | Default |
|---|---|---|
| Description | Description of your dataset. | None |
| Write Mode | How to handle existing data. For a list of the possible values, see Supported write modes. | error |
| Partition Columns | List of columns to partition the ORC files by. | None |
| Compression Codec | Compression codec when writing to the ORC file. The ORC file supports the following codecs: none, snappy, zlib, and lzo. | snappy |
Supported write modes
| Write mode | Description |
|---|---|
| error | If the data already exists, throw an exception. |
| overwrite | If the data already exists, overwrite the data with the contents of the DataFrame. |
| append | If the data already exists, append the contents of the DataFrame. |
| ignore | If the data already exists, do nothing with the contents of the DataFrame. This is similar to the CREATE TABLE IF NOT EXISTS clause in SQL. |
Example
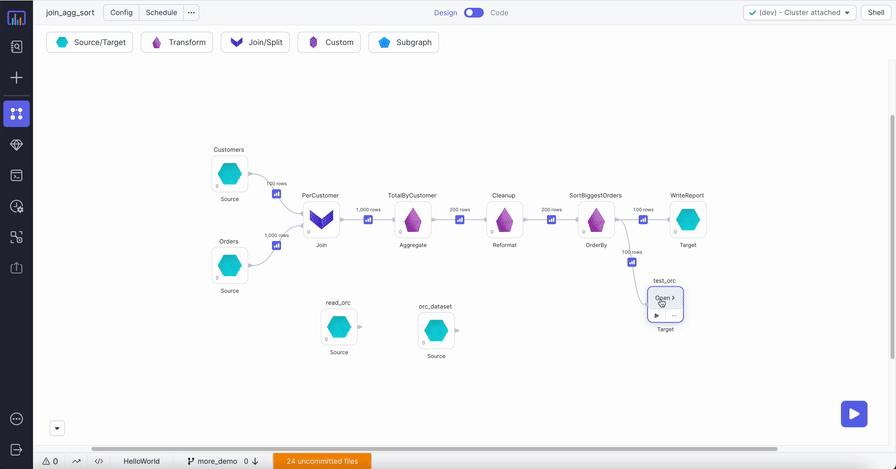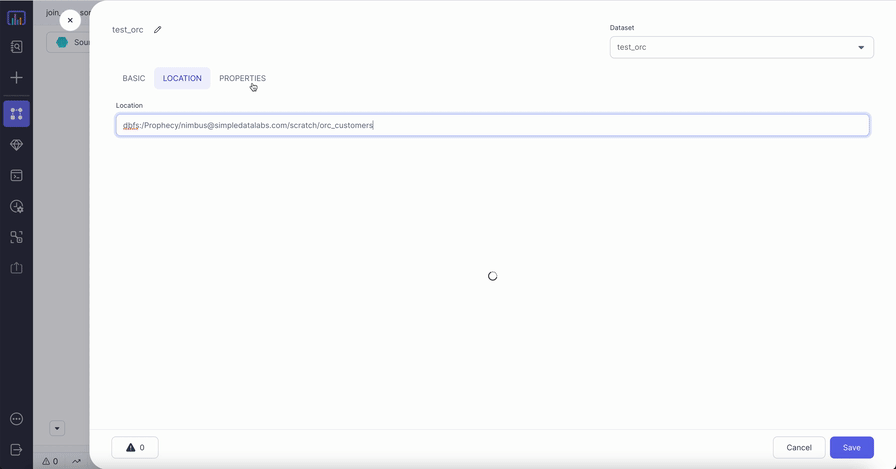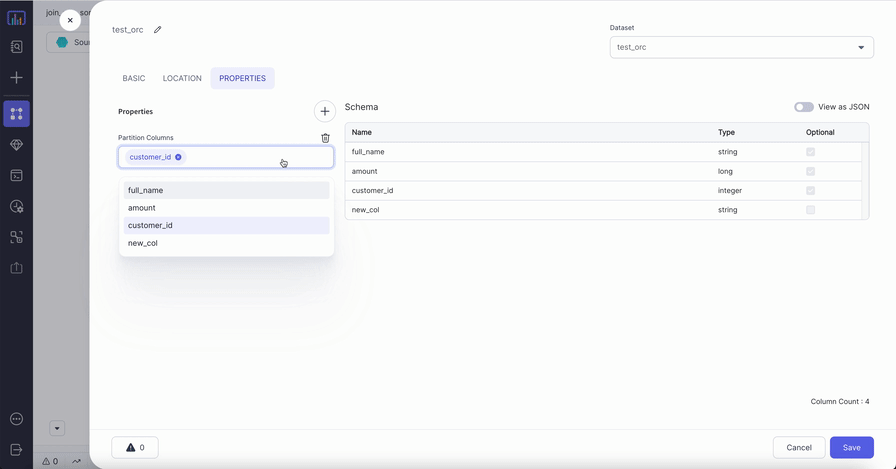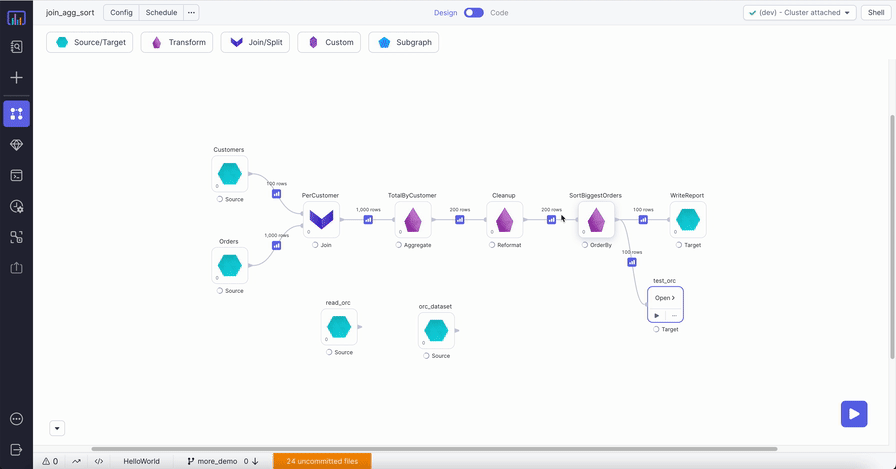
Compiled code
tip
To see the compiled code of your project, switch to the Code view in the project header.
- Python
- Scala
def write_orc(spark: SparkSession, in0: DataFrame):
in0.write\
.format("orc")\
.mode("overwrite")\
.save("dbfs:/data/test_output.orc")
object write_orc {
def apply(spark: SparkSession, in: DataFrame): Unit =
in.write
.format("orc")
.mode("overwrite")
.save("dbfs:/data/test_output.orc")
}